ukrainian-tts-audiobooks-24khz
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/Mikhailo/ukrainian-tts-audiobooks-24khz
下载链接
链接失效反馈官方服务:
资源简介:
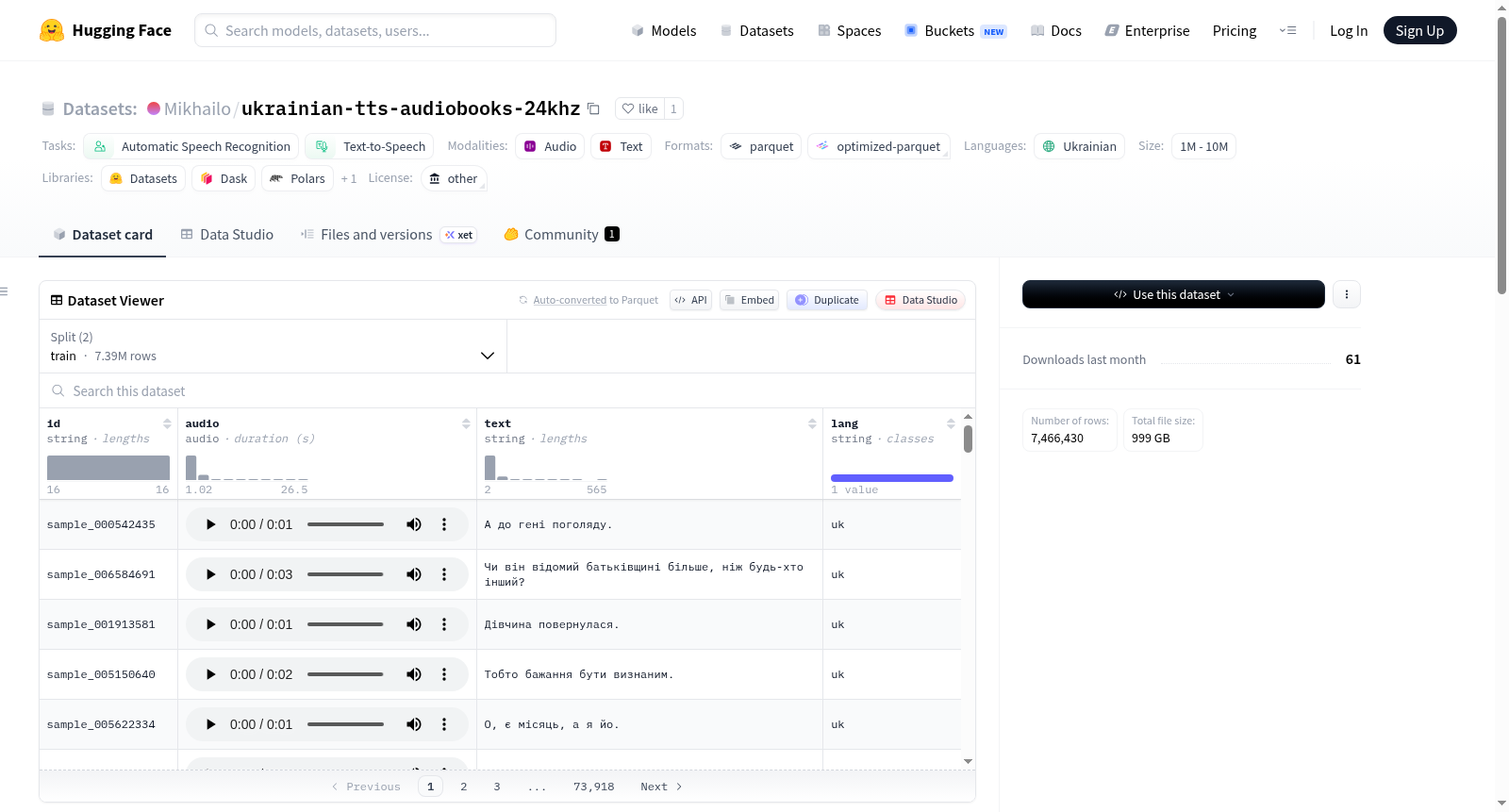
乌克兰语有声书TTS数据集(24 kHz)是一个专为文本到语音(TTS)和自动语音识别(ASR)任务设计的语音数据集。数据集来源于Yehor/audiobooks-xxl,并经过了一系列处理流程,包括背景音乐/噪声过滤、音频处理(从16 kHz重采样至24 kHz并转换为单声道)以及使用nvidia/canary-1b-v2模型生成转录文本。数据集结构包含四个字段:id(唯一样本标识符)、audio(24 kHz单声道WAV音频)、text(乌克兰语转录文本)和lang(语言代码,固定为uk)。数据集分为训练集(约99%)和开发集(约1%)。此外,还提供了一个经过清理和优化的版本,可通过指定链接访问。
Ukrainian Audiobook TTS Dataset (24 kHz) is a speech dataset purpose-built for text-to-speech (TTS) and automatic speech recognition (ASR) tasks. The dataset is sourced from Yehor/audiobooks-xxl, and has undergone a series of processing workflows including background music and noise filtering, audio processing (resampling from 16 kHz to 24 kHz and converting to mono), and transcription generation using the nvidia/canary-1b-v2 model. The dataset structure consists of four fields: id (unique sample identifier), audio (24 kHz mono WAV audio), text (Ukrainian transcription text), and lang (language code fixed to 'uk'). The dataset is split into a training set (approximately 99%) and a development set (approximately 1%). In addition, a cleaned and optimized version of the dataset is available via a designated link.
创建时间:
2026-04-27
原始信息汇总
数据集概述:Ukrainian Audiobook TTS Dataset (24 kHz)
基本信息
- 语言:乌克兰语(
uk) - 许可协议:其他(
other) - 任务类型:自动语音识别(ASR)、文本转语音(TTS)
数据集描述
该数据集是一个乌克兰语语音数据集,适用于 TTS 和 ASR 任务。
数据来源
原始数据集来自:Yehor/audiobooks-xxl
数据处理流程
- 音乐检测过滤:移除含有背景音乐或噪音的样本
- 音频处理(Sidon):将音频从 16 kHz 重采样至 24 kHz,并转换为单声道
- 转录生成:使用
nvidia/canary-1b-v2模型生成转录文本
数据集结构
| 列名 | 类型 | 描述 |
|---|---|---|
| id | string | 唯一样本标识符 |
| audio | Audio 24kHz | 单声道 WAV,采样率 24,000 Hz |
| text | string | 乌克兰语转录文本 |
| lang | string | 语言代码(uk) |
数据集划分
| 划分 | 大小 |
|---|---|
| train | ~99% |
| dev | ~1% |
使用示例
python from datasets import load_dataset
ds = load_dataset("Mikhailo/ukrainian-tts-audiobooks-24khz") print(ds["train"][0])
附加信息
该数据集还有一个经过清洗和优化的版本,可在此访问:Mikhailo/ukrainian-tts-audiobooks-24khz-clean
搜集汇总
数据集介绍
构建方式
该数据集源于乌克兰语有声读物语料库,经过精心筛选与处理而构建。首先,通过音乐检测算法过滤掉含有背景音乐或噪声的样本,确保音频纯净度。随后,利用Sidon工具将原始音频从16 kHz重采样至24 kHz,并转换为单声道格式,以提升音频质量与一致性。最后,基于nvidia/canary-1b-v2模型自动生成对应的乌克兰语转录文本,形成完整的语音-文本对。整个流程旨在为语音合成与识别任务提供高质量、标准化的训练数据。
特点
数据集以24 kHz采样率、单声道WAV格式存储音频,覆盖乌克兰语有声读物内容,兼具语音合成与自动语音识别双重用途。其结构简洁明了,包含唯一标识符、音频文件、转录文本及语言标签四列,便于直接加载与处理。训练集占比约99%,开发集约占1%,划分合理。此外,还提供了经过进一步清洗与优化的精炼版本,以满足更高标准的研究需求,体现了数据集在质量与可用性上的双重优势。
使用方法
用户可通过HuggingFace的datasets库直接加载该数据集,使用from datasets import load_dataset命令,并指定数据集名称即可。加载后,数据集以标准格式返回,可通过索引访问训练集或开发集中的样本,获取音频数据与对应文本。该数据集特别适用于乌克兰语语音合成模型的训练、自动语音识别系统的开发与评估,也可作为多语言语音研究的基础资源。精炼版本额外提供,适合对数据质量有更严格要求的场景。
背景与挑战
背景概述
乌克兰语作为东斯拉夫语族的重要成员,在语音技术与资源建设方面长期面临数据匮乏的困境。ukrainian-tts-audiobooks-24khz数据集由Mikhailo等人于2024年创建,源自Yehor/audiobooks-xxl大规模有声读物语料库,旨在填补乌克兰语语音合成(TTS)与自动语音识别(ASR)领域的高质量数据空白。该数据集通过音乐检测滤波、音频重采样(16kHz至24kHz)及基于NVIDIA Canary模型的转录标注等精细化流水线处理,提供了超过数十小时的单声道24kHz音频及对应的乌克兰语文本,为低资源语言语音技术的研究与评测奠定了重要基础,显著推动了乌克兰语语音合成与识别系统的性能提升。
当前挑战
该数据集所解决的领域核心挑战在于乌克兰语语音资源的稀缺性,尤其是在嘈杂环境、多说话人及长语音场景下的鲁棒建模问题。构建过程中面临多重技术挑战:首先,原始有声书数据常混杂背景音乐与噪声,直接影响模型训练效果,需设计有效的音乐检测与滤波算法进行清洗;其次,从16kHz重采样至24kHz虽提升了信号保真度,但可能引入频谱畸变或信息损失,需精细处理以保证音频质量;此外,转录阶段依赖预训练模型(如Canary-1b)生成文本,其在乌克兰语上的识别准确率受限于模型训练数据分布,易出现错词或语法偏差,需后续人工或自动校正以确保标注一致性。
常用场景
经典使用场景
在乌克兰语语音技术研究中,ukrainian-tts-audiobooks-24khz 数据集被广泛用于构建和评估文本转语音(TTS)与自动语音识别(ASR)系统。该数据集包含约24kHz采样率的高质量单声道音频,以及对应的乌克兰语转录文本,为语音合成和识别模型提供了对齐良好的声学与文本配对资源。研究者常将其作为乌克兰语语音处理的基础训练语料,尤其适用于多说话人场景下的声学特征建模和端到端语音合成系统的开发。数据集的音频经过背景音乐和噪声过滤,确保了训练数据的纯净度,使其成为评估乌克兰语语音技术性能的首选基准之一。
解决学术问题
该数据集有效解决了乌克兰语语音资源匮乏这一长期困扰学术界的困境。此前,乌克兰语相关的语音数据集数量稀少且规模有限,严重制约了语音合成与识别模型在该语种上的性能提升。ukrainian-tts-audiobooks-24khz 提供了大规模、多元化的有声书录音,覆盖了丰富的声学环境和说话风格,使得研究者能够开展针对低资源语种的迁移学习、域自适应以及多任务联合训练等前沿课题。该数据集的问世,不仅推动了乌克兰语语音技术的标准化评估流程建立,也为跨语种语音处理研究提供了宝贵的对照资源,具有重要的语言学与工程学双重价值。
衍生相关工作
该数据集衍生出了一系列高质量的工作,其中最典型的包括其清洗增强版本 ukrainian-tts-audiobooks-24khz-clean,该版本进一步优化了音频质量与转录一致性,适用于对数据纯净度要求更高的学术研究。基于此数据集,研究者提出了针对乌克兰语的端到端语音合成模型,如结合VITS和FastSpeech架构的改进方案,以及面向低资源语种的跨语言语音识别方法。此外,该数据集还被用于训练乌克兰语语音增强模型,并通过对比实验验证了24kHz采样率相较于16kHz在声学细节保留方面的优势,推动了乌克兰语语音技术从实验室研究走向实际部署的进程。
以上内容由遇见数据集搜集并总结生成


