FleSpeech
收藏arXiv2025-01-09 更新2025-01-10 收录
下载链接:
https://kkksuper.github.io/FleSpeech/
下载链接
链接失效反馈官方服务:
资源简介:
FleSpeech数据集由西北工业大学、香港科技大学和腾讯AI实验室联合创建,旨在支持灵活可控的语音生成研究。该数据集包含多模态数据,如文本、音频和视觉提示,数据来源包括CelebV-HQ、GRID、LRS2和MEAD等公开数据集。数据收集过程涉及视频分割、降噪处理和语音转录,确保数据质量。该数据集的应用领域主要集中在语音合成和语音属性编辑,旨在解决现有语音生成方法在灵活性和控制性方面的不足。
The FleSpeech dataset was jointly created by Northwestern Polytechnical University, The Hong Kong University of Science and Technology, and Tencent AI Lab, aiming to support research on flexible and controllable speech generation. This dataset includes multimodal data such as text, audio, and visual prompts, with data sources covering public datasets like CelebV-HQ, GRID, LRS2, and MEAD. The data collection process involves video segmentation, noise reduction, and speech transcription to guarantee data quality. Its primary application areas are speech synthesis and speech attribute editing, designed to address the limitations of current speech generation methods in terms of flexibility and controllability.
提供机构:
西北工业大学计算机科学与技术学院音频、语音与语言处理组(ASLP@NPU),香港科技大学,腾讯AI实验室
创建时间:
2025-01-09
搜集汇总
数据集介绍
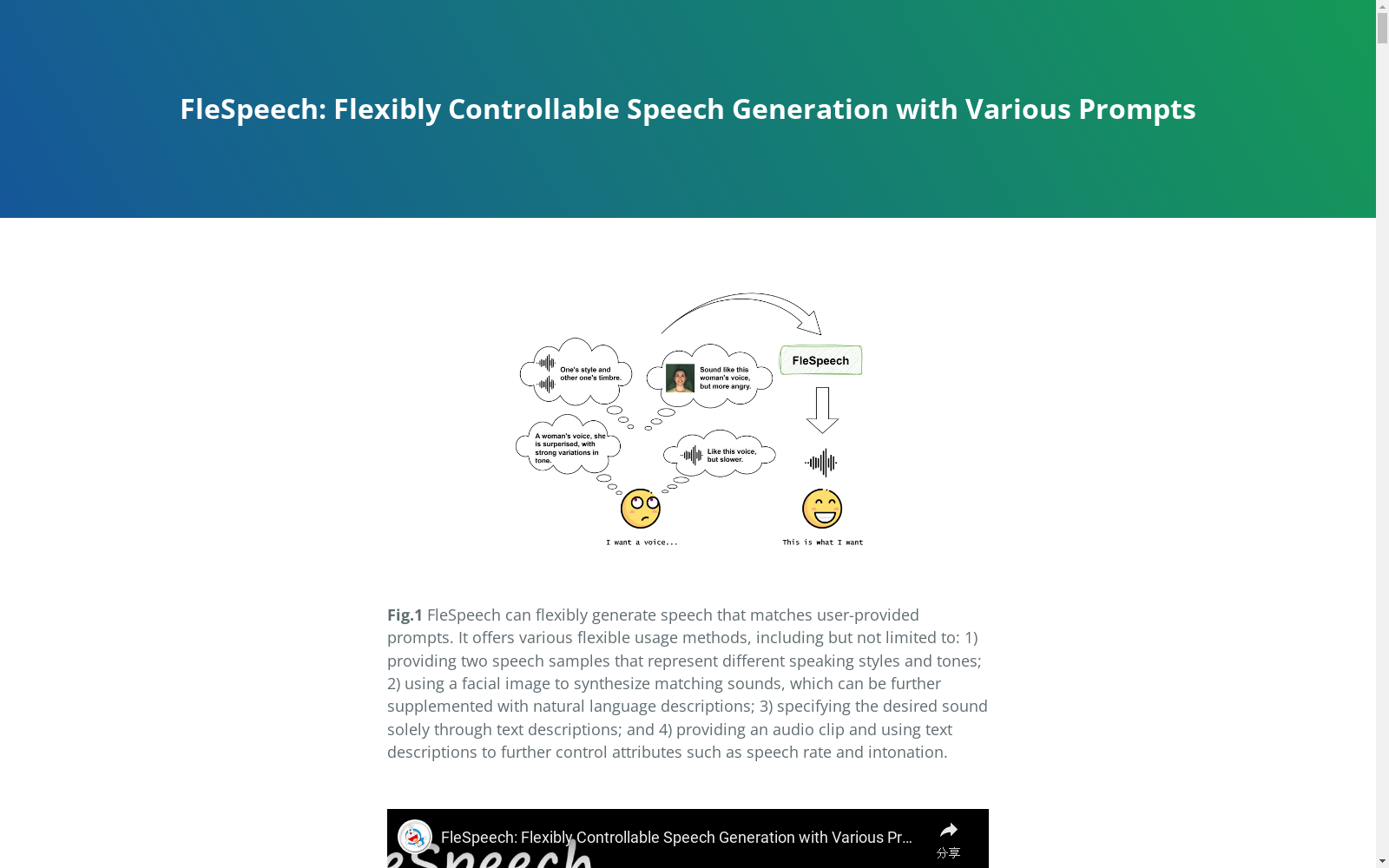
构建方式
FleSpeech数据集的构建采用了多模态数据收集管道,结合了大规模的低表达性语音数据和高表达性语音数据。首先,从LibriHeavy数据集中获取50,000小时的语音数据,确保模型在基础语音合成任务上的稳定性。随后,使用616小时的高表达性语音数据进行微调,以实现领域对齐。最后,通过冻结生成模型的主干网络,训练多模态编码器,使其能够处理除语音提示外的其他模态输入。此外,数据集中还包含了面部模态信息,通过从CelebV-HQ、GRID、LRS2和MEAD等数据集中提取面部视频,并结合Whisper模型进行语音转录和面部描述生成,确保了数据的多样性和丰富性。
特点
FleSpeech数据集的特点在于其多模态性和灵活性。数据集不仅包含了大量的语音数据,还整合了面部图像和文本描述,使得模型能够通过多种模态进行语音生成的控制。通过多模态提示编码器,FleSpeech能够将文本、音频和视觉提示统一嵌入到一个共同的表示空间中,从而实现对语音风格、音色等属性的精细控制。此外,数据集中还包含了丰富的面部描述信息,能够捕捉到静态和动态的面部特征,进一步增强了语音生成的多样性和个性化。
使用方法
FleSpeech数据集的使用方法主要围绕其多模态提示编码器和多阶段生成框架展开。用户可以通过输入文本、音频或面部图像等不同模态的提示,灵活控制生成的语音属性。首先,文本提示可以用于描述语音的风格和情感,音频提示则用于定义音色和语调,而面部图像提示则能够生成与人物视觉特征相匹配的语音。通过多模态提示编码器,这些提示被统一嵌入到一个共同的表示空间中,作为生成模型的输入条件。最终,模型通过语言模型和流匹配模块生成高质量的语音输出,满足不同场景下的灵活控制需求。
背景与挑战
背景概述
FleSpeech数据集由西北工业大学计算机学院的音频、语音与语言处理组(ASLP@NPU)与香港科技大学、腾讯AI实验室的研究人员共同开发,旨在解决语音生成领域中的灵活控制问题。该数据集于2025年提出,核心研究问题是通过多模态提示(如文本、音频和视觉信息)实现对语音属性的灵活操控。FleSpeech的提出标志着语音合成技术从单一控制向多模态控制的转变,极大地推动了语音生成领域的发展,尤其是在个性化语音生成和跨模态语音控制方面具有重要影响力。
当前挑战
FleSpeech数据集面临的主要挑战包括两个方面。首先,在领域问题方面,传统的语音生成方法通常依赖于单一或固定的提示,难以满足用户对语音风格、音色等属性的精细控制需求。例如,如何在保持特定音色的同时调整语音风格,或如何根据视觉外观生成匹配的语音,这些问题在现有技术中尚未得到充分解决。其次,在数据构建过程中,多模态数据的稀缺性是一个显著挑战。由于语音、文本和视觉数据的融合需要大量的标注和协调,数据收集和处理的复杂性较高,尤其是在确保数据质量和多样性的同时,如何高效地整合多模态信息也是一个亟待解决的难题。
常用场景
经典使用场景
FleSpeech数据集在语音生成领域中被广泛应用于多模态控制的语音合成任务。其经典使用场景包括通过文本、音频和视觉提示的灵活组合,生成具有特定风格、情感和音色的语音。例如,用户可以通过文本描述指定语音的情感风格,同时结合参考音频保留特定说话者的音色,或通过面部图像生成与角色视觉特征相匹配的语音。这种多模态控制能力使得FleSpeech在影视配音、虚拟助手和个性化语音生成等场景中表现出色。
实际应用
FleSpeech在实际应用中展现了广泛的潜力。例如,在影视制作中,可以通过面部图像和文本描述生成与角色特征高度匹配的语音;在虚拟助手中,用户可以通过自然语言指令调整语音的情感表达和语速;在个性化语音生成中,用户能够结合参考音频和视觉提示,生成符合个人偏好的语音。这些应用场景不仅提升了用户体验,还为语音合成技术的商业化落地提供了新的可能性。
衍生相关工作
FleSpeech的提出推动了多模态语音生成领域的相关研究。基于其多模态提示编码器和多阶段生成框架,衍生出了一系列经典工作。例如,MM-TTS进一步扩展了多模态提示的应用范围,支持文本、音频和面部图像的灵活组合;PromptTTS2则通过自然语言描述实现了对语音风格的精细控制。此外,FleSpeech的数据收集管道也为后续研究提供了高质量的多模态数据集,促进了语音生成技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


