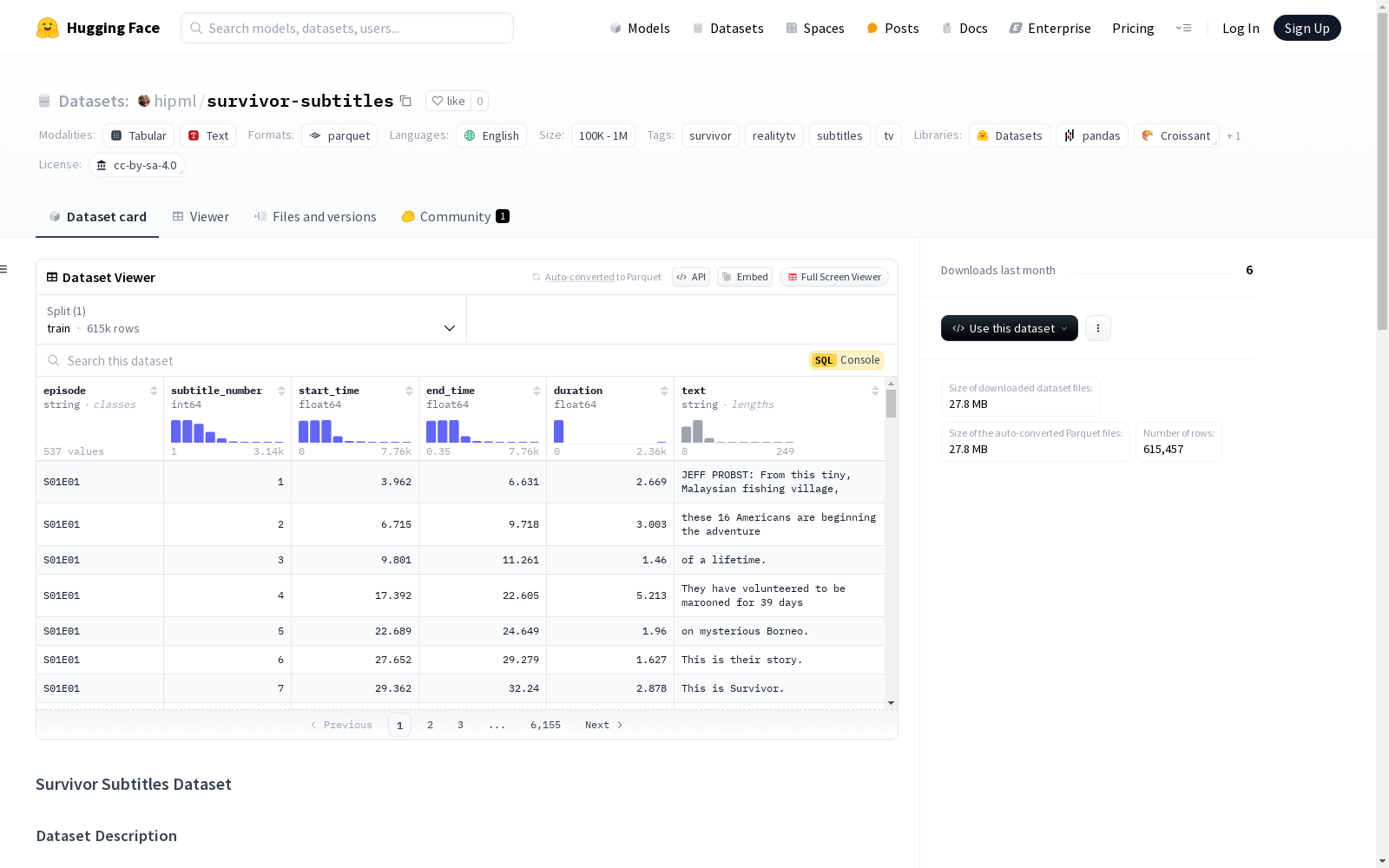
survivor-subtitles
收藏资源简介:
这是一个包含美国真人秀节目《幸存者》第1季至第47季字幕的数据集。数据集包含从节目广播中提取的字幕文本。字幕来源于OpenSubtitles.com。数据集覆盖了1至47季,每季约13-14集,总集数约600集。数据格式为包含时间戳的字幕文本文件,字符编码为UTF-8。使用该数据集时需遵守合理使用原则,任何衍生作品应适当注明CBS并尊重版权限制。数据可能包含转录错误或不一致。引用该数据集时,请引用原始节目《幸存者》(CBS电视台)和字幕来源OpenSubtitles.com。数据集仅用于研究目的,不得用于商业用途。
This is a dataset containing subtitles for the American reality TV show *Survivor* seasons 1 through 47. The subtitle texts are extracted from the program's original broadcast, with subtitles sourced from OpenSubtitles.com. The dataset covers seasons 1 to 47, with approximately 13-14 episodes per season, totaling around 600 episodes overall. The data is stored as timestamped subtitle text files encoded in UTF-8. Users must comply with the fair use principle when utilizing this dataset; any derivative works should appropriately credit CBS and respect relevant copyright restrictions. The dataset may contain transcription errors or inconsistencies. When citing this dataset, please reference the original program *Survivor* (CBS) and the subtitle source OpenSubtitles.com. This dataset is intended solely for research purposes and shall not be used for commercial applications.
Survivor Subtitles 数据集概述
数据集描述
该数据集包含美国真人秀节目《Survivor》第1至第47季的字幕文本,这些字幕是从节目播出中提取的。
数据来源
字幕数据来源于OpenSubtitles.com。
数据集详情
- 覆盖范围:
- 季数:1-47
- 每季集数:约13-14集
- 总集数:约600集
- 格式:
- 包含时间戳的字幕数据文本文件
- 字符编码:UTF-8
数据集特征
- 特征:
episode(string): 集数subtitle_number(int64): 字幕编号start_time(float64): 字幕开始时间end_time(float64): 字幕结束时间duration(float64): 字幕持续时间text(string): 字幕文本
数据集分割
- 训练集:
- 字节数:45973562
- 样本数:615457
下载与大小
- 下载大小:27788539
- 数据集大小:45973562
限制与伦理考虑
- 数据集应仅在合理使用原则下使用
- 任何衍生作品应适当归功于CBS并尊重版权限制
- 数据可能包含转录错误或不一致
引用
使用该数据集时,请引用:
- 原节目:"Survivor" (CBS Television)
- 字幕来源:OpenSubtitles.com
维护
请通过项目的issue tracker报告数据集中的任何问题或错误。
版权声明
所有内容版权归CBS所有。该数据集仅供研究使用。字幕受版权法保护,未经版权持有者授权,不得用于商业用途。
许可证
该数据集采用CC BY-SA 4.0(知识共享署名-相同方式共享 4.0 国际)许可证。
主要条款:
- 需要署名
- 衍生作品需采用相同方式共享
- 内容版权归CBS及各自版权持有者所有