PFSA-ID
收藏数据集概述
数据集名称
PFSA-ID: An Annotated Indonesian Corpus and Baseline Model of Public Figures Statements Attributions
目的
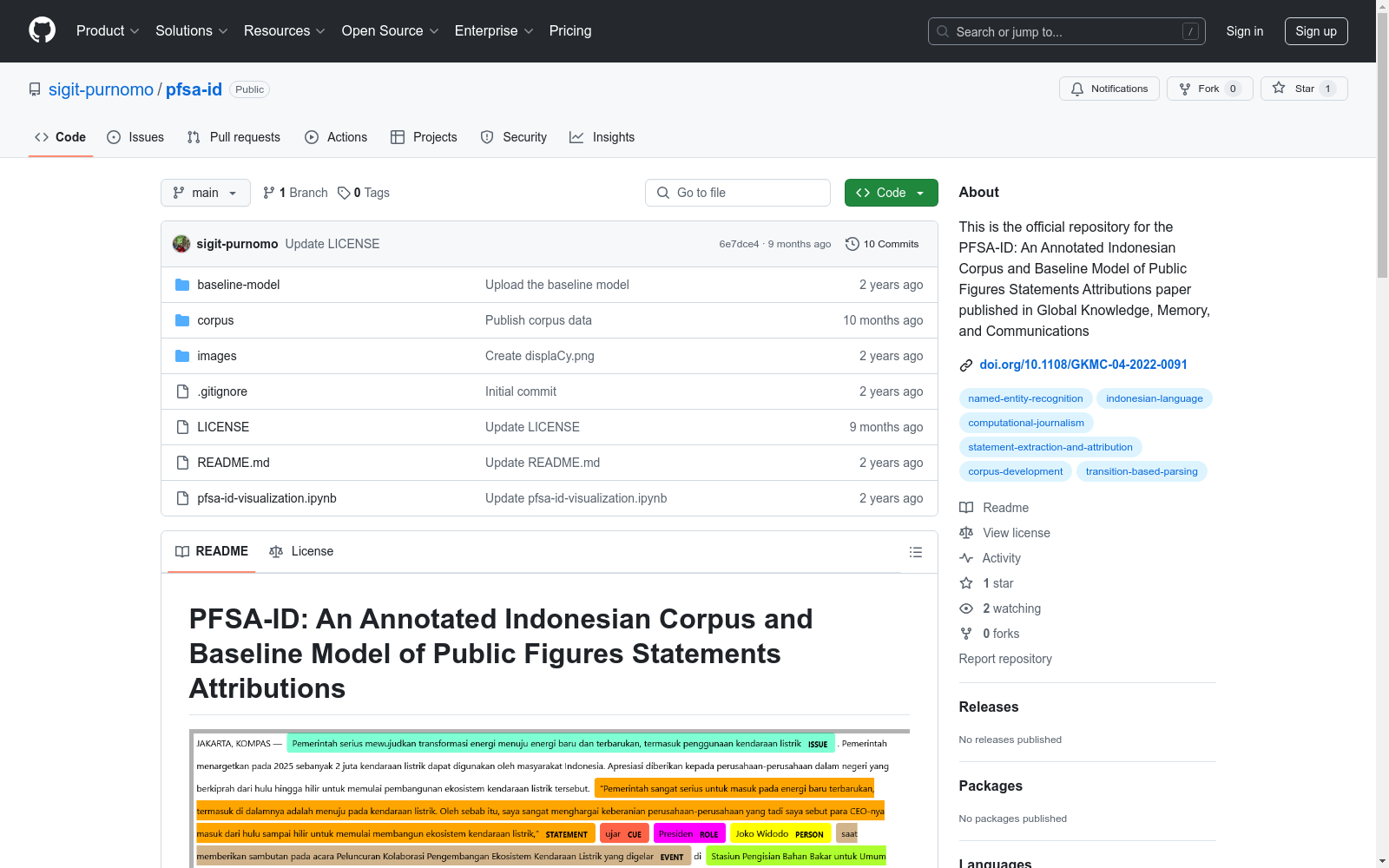
本研究旨在开发一个印尼语公共人物声明归属的标注语料库及一个基准模型,以促进印尼语信息提取的研究。
设计/方法/途径
研究方法分为语料库开发和提取模型开发两部分。语料库开发包括数据收集和标注,提取模型开发涉及特征提取、模型架构定义、参数选择与配置、模型训练与评估以及模型选择。
发现
印尼语公共人物声明归属的标注语料库达到了90.06%的注释者与专家之间的一致性,可作为黄金标准语料库。基准模型在大多数标签上预测准确,达到了82.026%的F-score。
原创性/价值
据作者所知,该语料库是首个针对印尼语公共人物声明归属的语料库,对印尼语归属提取研究具有重要意义。该语料库和基准模型可作为进一步研究的基准。其他研究者可以采用本研究中提出的方法来开发新语料库和基准模型。
引用方式
如需扩展或使用此工作,请引用以下文献: bibtex @article{2022pfsaid, author = {Yohanes Sigit Purnomo W.P., Yogan Jaya Kumar, Nur Zareen Zulkarnain}, title = {PFSA-ID: An Annotated Indonesian Corpus and Baseline Model of Public Figures Statements Attributions}, journal = {Global Knowledge, Memory and Communication}, year = {2022}, volume = {-}, number = {-}, pages = {-}, url = {https://doi.org/10.1108/GKMC-04-2022-0091} }