kamel-usp/aes_enem_dataset
收藏Hugging Face2025-02-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/kamel-usp/aes_enem_dataset
下载链接
链接失效反馈官方服务:
资源简介:
Automated Essay Score (AES) ENEM数据集主要用于自动作文评分,包含学生作文的评分数据。数据集来源于GitHub,规模小于1000条。数据集的结构包括作文的ID、主题、标题、文本、评分和年份等信息。数据集的创建者是Igor Cataneo Silveira, André Barbosa和Denis Deratani Mauá,数据集的使用目的是估计作文分数。数据集采用MIT许可证,并提供了相关的引用信息。
Automated Essay Score (AES) ENEM数据集主要用于自动作文评分,包含学生作文的评分数据。数据集来源于GitHub,规模小于1000条。数据集的结构包括作文的ID、主题、标题、文本、评分和年份等信息。数据集的创建者是Igor Cataneo Silveira, André Barbosa和Denis Deratani Mauá,数据集的使用目的是估计作文分数。数据集采用MIT许可证,并提供了相关的引用信息。
提供机构:
kamel-usp
原始信息汇总
Automated Essay Score (AES) ENEM Dataset
数据集描述
- 目的: 自动作文评分
- 内容: 学生作文成绩
- 来源: https://github.com/kamel-usp/aes_enem
- 大小: N<1000
使用案例和创建者
- 预期用途: 估计作文分数
- 创建者: Igor Cataneo Silveira, André Barbosa 和 Denis Deratani Mauá
- 联系信息: igorcs@ime.usp.br; andre.barbosa@ime.usp.br
许可信息
- 许可: MIT License
引用详情
- 首选引用:
@proceedings{DBLP:conf/propor/2024, editor = {Igor Cataneo Silveira, André Barbosa and Denis Deratani Mauá}, title = {Computational Processing of the Portuguese Language - 16th International Conference, {PROPOR} 2024, Galiza, March 13-15, 2024, Proceedings}, series = {Lecture Notes in Computer Science}, volume = {TODO}, publisher = {Springer}, year = {2024}, url = {TODO}, doi = {TODO}, isbn = {TODO}, timestamp = {TODO}, biburl = {TODO}, bibsource = {dblp computer science bibliography, https://dblp.org} }
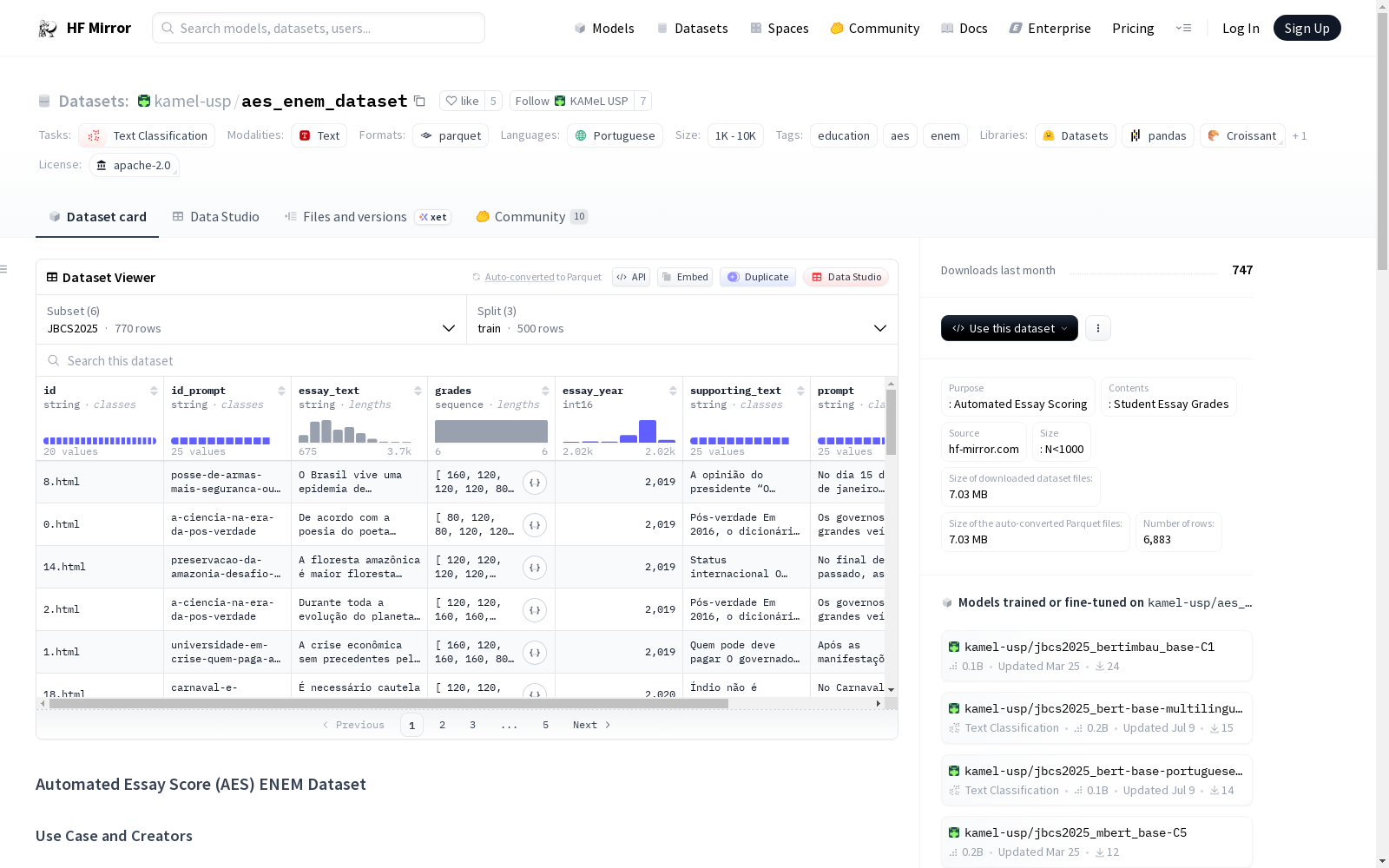
数据结构
- 特征:
- id: 抓取页面的ID。
id_prompt+id应该是唯一的 - id_prompt: 作文的主题
- essay_title: 作文标题
- essay_text: 作文文本
- grades: 包含六个元素的列表,包含五个概念的每个等级的分数以及所有等级的总和
- essay_year: 作文的年份
- id: 抓取页面的ID。
- 实例数量:
- sourceAOnly:
- train: 227
- validation: 68
- test: 90
- sourceAWithGraders:
- train: 744
- validation: 195
- test: 216
- sourceB:
- full: 3219
- sourceAOnly:
- 数据分割:
- sourceAOnly: sourceA 数据
- sourceAWithGraders: sourceA 数据增强,带有评分者的评论。简而言之,每一行变成三行(原始评分加上两个评分者的结果)
- sourceB: sourceB 数据
数据考虑
- 已知限制:
- 伦理考虑:
搜集汇总
数据集介绍
构建方式
在教育评估领域,自动作文评分系统的开发依赖于高质量标注数据的支撑。该数据集通过系统性地收集巴西国家中学教育考试(ENEM)中的学生作文构建而成,涵盖了多个年份的考试题目与对应答卷。数据采集过程整合了官方发布的作文题目、支持性文本以及学生实际撰写的作文内容,并依据评分标准对每篇作文进行了多维度的概念评分。构建过程中,原始数据经过清洗与去标识化处理,确保了数据的规范性与隐私保护。数据集进一步细分为多个配置,如sourceAOnly与sourceAWithGraders,通过引入评阅者复核信息增强了数据的多样性与可靠性,为自动化评分模型的训练与验证提供了结构化基础。
特点
该数据集在自动作文评分研究领域展现出鲜明的特色。其核心特征在于包含了丰富的元数据,如作文标题、支持文本、提示信息及参考标准,这些要素共同构成了完整的评分上下文环境。数据集中每篇作文均附有六维评分序列,涵盖了五个独立概念维度及总分,为多维度评分模型的开发提供了精细标注。数据集以葡萄牙语呈现,专门针对巴西教育体系设计,并提供了多个配置版本,如PROPOR2024与gradesThousand,以适应不同研究场景的需求。数据规模虽不足千例,但通过评阅者增广与多源数据整合,有效提升了数据的代表性与实用性。
使用方法
在自然语言处理与教育技术交叉领域,该数据集为自动作文评分模型的训练与评估提供了直接支持。研究人员可通过HuggingFace平台便捷加载数据集,利用其预定义的训练、验证与测试划分进行模型开发。使用时应根据研究目标选择合适的配置,例如sourceAWithGraders适用于探索评阅者一致性对评分模型的影响,而PROPOR2024配置则便于与现有研究成果进行对比。典型工作流程包括对作文文本进行特征提取,结合提示信息与支持文本构建上下文表示,并基于多维度评分序列训练回归或分类模型。数据集兼容常见的机器学习框架,支持端到端的评分系统构建与性能验证。
背景与挑战
背景概述
在教育评估领域,自动作文评分(AES)技术旨在通过计算模型模拟人类评分者的评判过程,以提升评估效率与一致性。kamel-usp/aes_enem_dataset由圣保罗大学的Igor Cataneo Silveira、André Barbosa与Denis Deratani Mauá等研究人员于2024年构建,专注于葡萄牙语教育场景,特别是巴西国家中等教育考试(ENEM)的作文评分。该数据集的核心研究问题在于解决葡萄牙语自动作文评分的模型训练与验证需求,通过整合多源评分数据与评语信息,为自然语言处理与教育技术的交叉研究提供了关键资源,推动了多语言AES系统的发展。
当前挑战
该数据集致力于解决自动作文评分领域的核心挑战,即如何准确建模人类评分者对作文内容、结构与语言运用的多维评判标准,尤其是在葡萄牙语这类资源相对有限的语境中。构建过程中的挑战包括数据采集与标注的复杂性:ENEM作文涉及敏感的学生信息,需在伦理框架下获取与匿名化处理;评分标准包含多个维度,需协调不同评分者间的主观差异以确保标注一致性;此外,数据规模有限(实例数小于1000),且需整合来自不同来源(如sourceA与sourceB)的异构数据,这增加了数据清洗与标准化的难度。
常用场景
经典使用场景
在教育技术领域,自动作文评分系统的开发依赖于高质量标注的文本数据。该数据集汇集了巴西国家中等教育考试(ENEM)的考生作文及其多维评分,为研究人员提供了构建和验证葡萄牙语自动作文评分模型的基准资源。通过整合不同年份的作文题目、支持文本及多位评分者的详细评语,该数据集能够支持从简单的回归预测到复杂的多维度评分分析等多种建模任务,成为自然语言处理与教育评估交叉研究的典型实验平台。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作,例如在PROPOR2024会议上发表的论文利用其进行了葡萄牙语自动评分模型的比较与优化。这些工作不仅探索了基于Transformer的预训练模型在作文评分任务上的适应性,还研究了多评分者信息融合、评分可解释性增强等方法。后续研究进一步扩展至跨题目泛化、评分偏差检测以及结合评语生成反馈的端到端系统构建,持续推动了教育人工智能领域的技术进步。
数据集最近研究
最新研究方向
在教育技术领域,自动作文评分(AES)系统正成为提升评估效率与公平性的关键工具。基于葡萄牙语ENEM考试构建的aes_enem_dataset,其最新研究聚焦于利用多源评分者注释与细粒度反馈信息,探索深度学习模型在跨主题作文评分中的鲁棒性与可解释性。前沿工作结合自然语言处理技术,分析作文文本与评分者评论之间的语义关联,旨在开发能够模拟人类评分者认知过程的智能系统,以应对大规模教育评估中的一致性与偏见挑战。该数据集的应用不仅推动了葡萄牙语教育评估的自动化进程,也为多语言AES研究提供了重要的跨文化比较基准。
以上内容由遇见数据集搜集并总结生成


