tner/tweetner7
收藏Hugging Face2022-11-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tner/tweetner7
下载链接
链接失效反馈官方服务:
资源简介:
TweetNER7是一个用于命名实体识别(NER)的数据集,包含7种实体类型,数据来源于Twitter,时间跨度为2019年9月至2021年8月。数据集中的每条推文都带有时间戳,并且经过了预处理,将URL和用户名转换为特殊标记。数据集分为训练集、验证集和测试集,分别覆盖不同的时间段。
TweetNER7 is a named entity recognition (NER) dataset containing 7 entity types. Its data is sourced from Twitter, spanning from September 2019 to August 2021. Each tweet in the dataset is attached with a timestamp and has been preprocessed by replacing URLs and usernames with special tokens. The dataset is split into training, validation and test sets, which cover different time periods respectively.
提供机构:
tner
原始信息汇总
数据集概述
数据集基本信息
- 名称: TweetNER7
- 语言: 英语
- 许可证: 其他
- 多语言性: 单语
- 大小类别: 1k<10K
- 任务类别: 令牌分类
- 任务ID: 命名实体识别
- 领域: Twitter
- 实体数量: 7
数据集详细描述
- 摘要: TweetNER7 是一个针对Twitter的命名实体识别(NER)数据集,包含7种实体标签。每个实例附带一个时间戳,数据收集时间为2019年9月至2021年8月。
- 实体类型:
corperation,creative_work,event,group,location,product,person - 预处理: 对推文进行预处理,将URL转换为特殊标记
{{URL}},未验证的用户名转换为{{USERNAME}},已验证的用户名显示名为{@}。
数据分割
| 分割 | 实例数量 | 描述 |
|---|---|---|
| train_2020 | 4616 | 2019年9月至2020年8月的训练数据 |
| train_2021 | 2495 | 2020年9月至2021年8月的训练数据 |
| train_all | 7111 | train_2020 和 train_2021 的合并 |
| validation_2020 | 576 | 2019年9月至2020年8月的验证数据 |
| validation_2021 | 310 | 2020年9月至2021年8月的验证数据 |
| test_2020 | 576 | 2019年9月至2020年8月的测试数据 |
| test_2021 | 2807 | 2020年9月至2021年8月的测试数据 |
| train_random | 4616 | 从 train_all 随机抽样的训练数据 |
| validation_random | 576 | 从 validation_all 随机抽样的验证数据 |
| extra_2020 | 87880 | 2019年9月至2020年8月的额外未标注推文 |
| extra_2021 | 93594 | 2020年9月至2021年8月的额外未标注推文 |
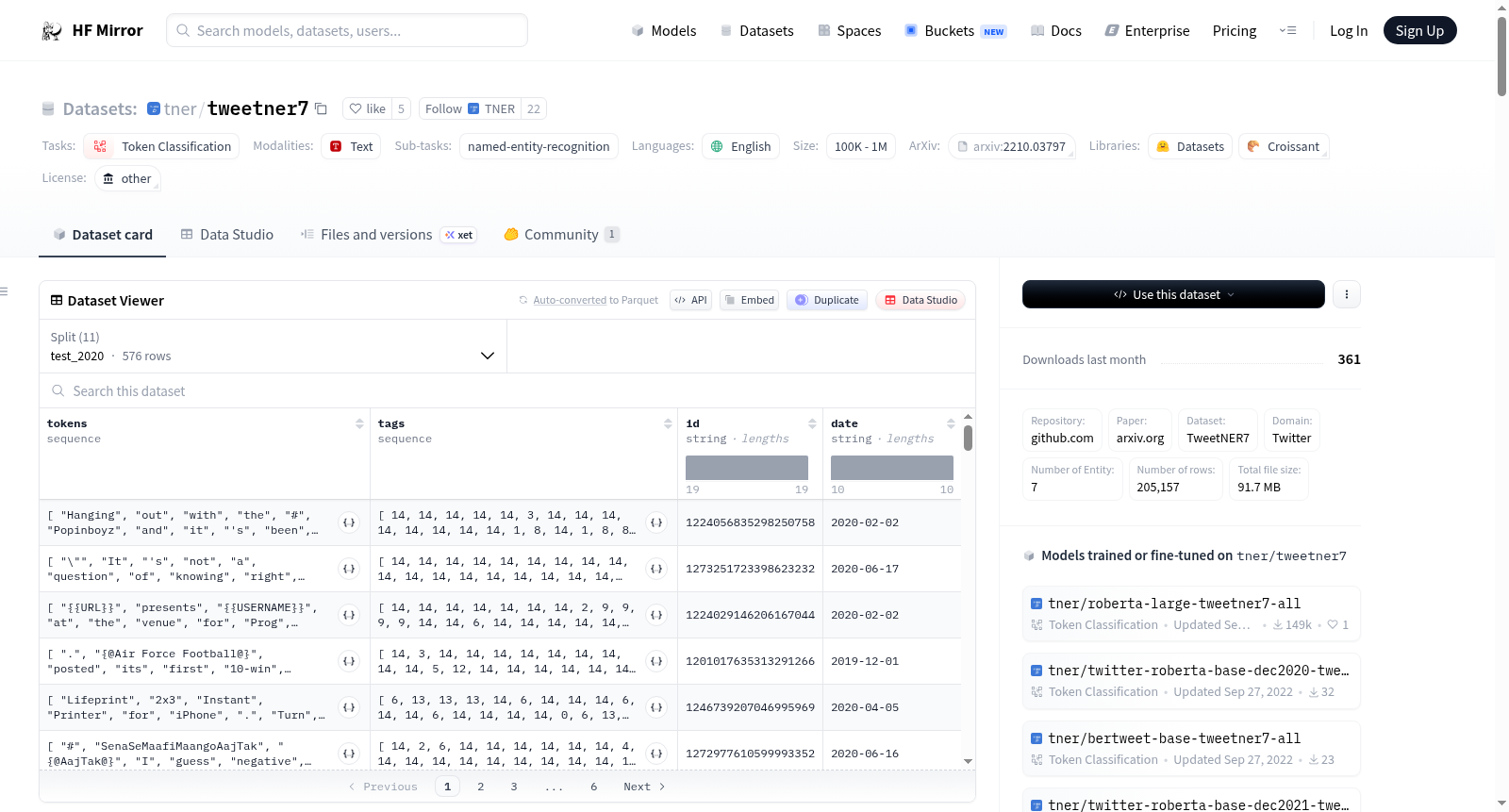
数据集结构
- 数据实例: 每个实例包含
tokens(令牌),tags(标签),id(标识符),date(日期)。 - 标签ID: 标签到ID的映射可在指定链接中找到。
模型
- 主模型: 包括多种基于不同语言模型的模型,如
roberta-large,roberta-base,twitter-roberta-base-2019-90m等,用于不同的训练和验证设置。 - 子模型: 用于 ablation study 的模型,如
roberta-large-tweetner7-random,仅在train_random上进行训练并在validation_2020上验证。
搜集汇总
数据集介绍
构建方式
在社交媒体命名实体识别领域,TweetNER7数据集的构建体现了严谨的学术方法。该数据集源自Twitter平台,覆盖了2019年9月至2021年8月的时间跨度,确保了数据的时效性与代表性。构建过程中,研究者首先收集原始推文,并采用统一的预处理流程,将URL替换为特殊标记{{URL}},对非认证用户名进行{{USERNAME}}的标准化处理,而认证用户名则保留其显示名称并用{@}符号标注。随后,经过专业标注人员对七类实体进行精细标注,形成了包含时序信息的结构化语料,为研究短时态偏移现象提供了坚实基础。
特点
TweetNER7数据集的显著特征在于其精心设计的时序结构与实体分类体系。该数据集不仅提供了按年份划分的训练、验证与测试子集,如train_2020与test_2021,还特别设置了用于研究时序泛化能力的实验配置,使模型能够评估在时间分布变化下的性能稳定性。实体类别涵盖组织、创意作品、事件、团体、地点、产品与人名七大类,并采用BIO标注格式,确保了标注的一致性与机器可读性。每个数据实例均附有精确的时间戳,为分析社交媒体语言的动态演变提供了珍贵资源。
使用方法
该数据集的使用方法灵活多样,主要服务于命名实体识别模型的训练与评估。研究者可通过HuggingFace平台直接加载数据集,利用其预定义的划分进行实验。针对时序分析,推荐采用train_2020训练并以test_2021测试,以探究模型在时间偏移下的泛化能力;若追求最佳性能,则可使用train_all进行训练。数据以字典格式呈现,包含tokens、tags、id与date字段,便于直接输入模型。此外,数据集中提供的预处理函数有助于用户复现文本规范化步骤,确保与原始研究的一致性。
背景与挑战
背景概述
在社交媒体自然语言处理领域,推特平台因其独特的语言风格和动态内容,为命名实体识别任务带来了新的研究机遇。TweetNER7数据集由相关研究团队于2022年构建,并发表于AACL主会议,旨在解决推特文本中七类命名实体的识别问题,涵盖公司、创意作品、事件、团体、地点、产品和个人等实体类型。该数据集覆盖了2019年9月至2021年8月的时间跨度,每条推文均附有时间戳,为研究短期时间偏移现象提供了宝贵资源。其构建基于与TweetTopic相同的数据收集框架,并整合入TweetNLP生态系统,显著推动了社交媒体语境下实体识别模型的发展与评估。
当前挑战
TweetNER7数据集面临的挑战主要体现在两个方面:在领域问题层面,推特文本的非正式性、缩写频繁、新词涌现以及语境依赖性强,使得实体识别模型难以准确捕捉实体边界与语义;同时,时间偏移现象导致模型在跨时段数据上性能下降,凸显了动态语言环境中的泛化难题。在构建过程中,数据预处理面临特殊符号如URL和用户名的标准化处理,需设计规则将其转换为统一标记,同时确保标注者能正确忽略这些标记;此外,标注一致性维护与时间戳对齐的复杂性,也为数据集的质控与划分带来了额外挑战。
常用场景
经典使用场景
在社交媒体自然语言处理领域,TweetNER7数据集为命名实体识别任务提供了经典的应用场景。该数据集专门针对推特文本设计,涵盖了七类实体标签,包括人物、地点、事件等,其独特之处在于每条数据均附带时间戳,使得研究者能够深入探索短时态偏移对模型性能的影响。通过构建时间分段的训练集与测试集,该数据集为评估模型在动态变化的社交媒体环境中的泛化能力提供了标准化的实验框架。
衍生相关工作
围绕TweetNER7数据集,学术界衍生出一系列经典研究工作。以该数据集为基础,研究者开发了多种针对推特文本的预训练模型微调策略,如时序连续训练与领域自适应方法。相关成果已集成至TweetNLP生态系统,并催生了如Twitter-RoBERTa等社交媒体专用语言模型的性能评估基准。这些工作不仅深化了对社交媒体实体识别任务的理解,也为后续跨平台、多语言社交媒体NLP研究提供了方法论借鉴。
数据集最近研究
最新研究方向
在社交媒体自然语言处理领域,TweetNER7数据集因其标注的时序特性,已成为研究短时域迁移学习的关键资源。该数据集覆盖了2019年至2021年的推特文本,并标注了七类实体,为探索命名实体识别模型在动态语言环境中的适应性提供了实证基础。当前研究聚焦于利用时序分割数据,评估预训练语言模型在跨时间泛化能力上的表现,尤其是在面对新兴事件和词汇演变时的鲁棒性。相关热点事件如全球公共卫生事件和社会运动,凸显了推特数据中实体分布的快速变化,促使研究者开发连续学习与领域自适应方法。这些探索不仅推动了时序感知NER模型的发展,也为社交媒体信息抽取在实时应用中的可靠性奠定了理论框架。
以上内容由遇见数据集搜集并总结生成


