pmoa-tts
收藏Hugging Face2025-05-15 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/snoroozi/pmoa-tts
下载链接
链接失效反馈官方服务:
资源简介:
PMOA-TTS数据集是从PubMed开放获取的临床病历报告中提取的结构化文本时间序列数据集。它包含了124k个病例报告,每个报告包括时间戳的临床事件序列、人口统计信息、诊断和死亡表型标签。数据集适用于时间序列建模、生存分析、事件预测和多媒体表征学习等研究。
The PMOA-TTS dataset is a structured text time-series dataset extracted from open-access clinical case reports sourced from PubMed. It contains 124,000 case reports, each including timestamped clinical event sequences, demographic information, diagnostic and death phenotypic labels. This dataset is applicable to research areas such as time-series modeling, survival analysis, event prediction, and multimedia representation learning.
创建时间:
2025-05-10
原始信息汇总
PMOA-TTS 数据集概述
数据集基本信息
- 任务类别:文本分类、时间序列预测
- 语言:英语
- 标签:临床、时间序列、生物医学、文本
- 数据集名称:PMOA-TTS
- 规模:100K < n < 1M
- 许可证:CC BY NC SA 4.0
数据集结构
特征字段
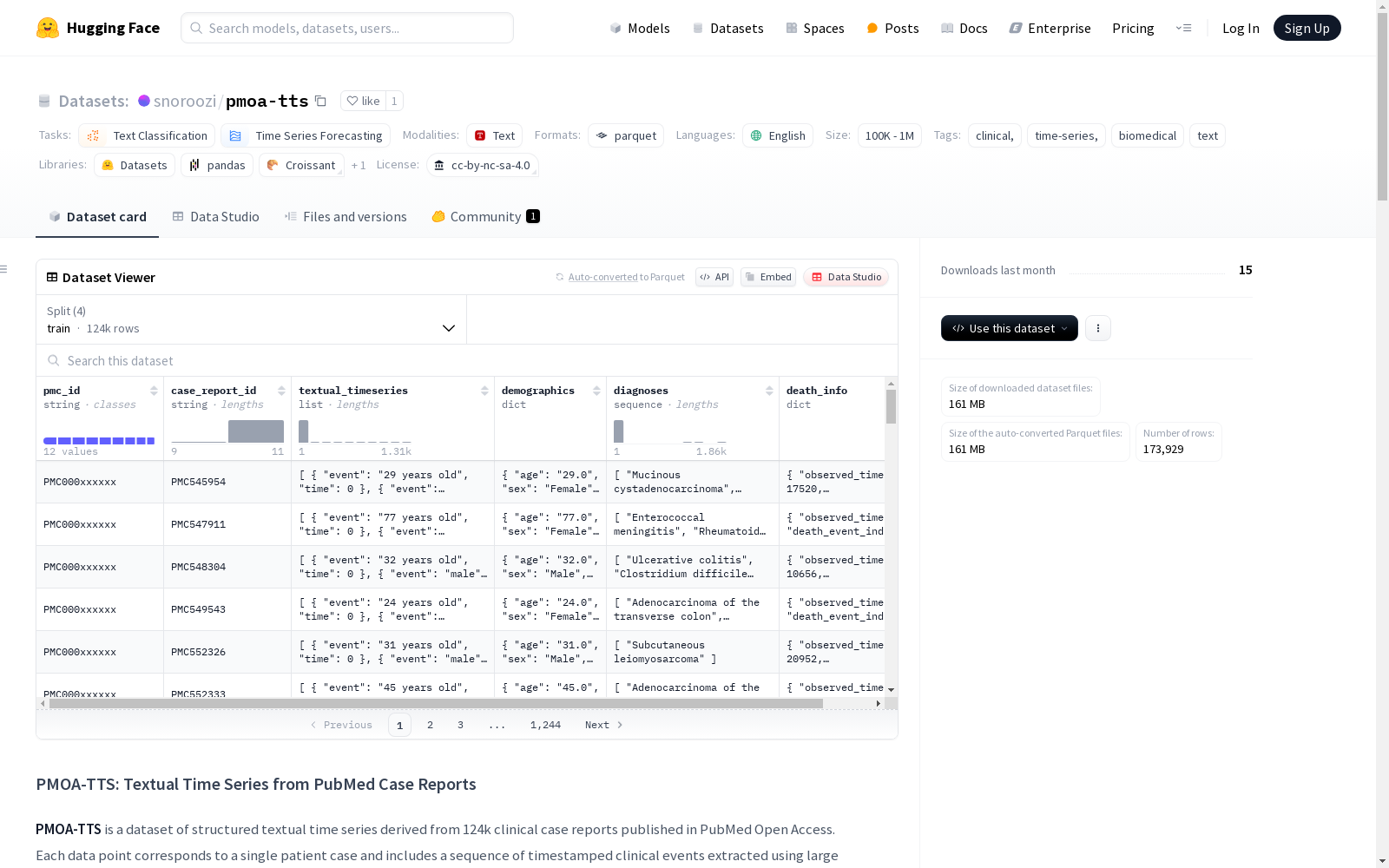
pmc_id:字符串,PubMed案例报告的文件夹级IDcase_report_id:字符串,案例的完整文件名textual_timeseries:列表,包含时间戳的临床事件序列event:字符串,事件描述time:int64,时间戳
demographics:结构体,包含患者人口统计信息age:字符串,年龄sex:字符串,性别ethnicity:字符串,种族
diagnoses:字符串序列,诊断术语列表death_info:结构体,包含死亡信息observed_time:float64,观察时间death_event_indicator:int64,死亡事件指示器(0或1)
数据集分割
- train:124,349个案例,240,122,853字节
- case_study_100:88个案例,205,311字节
- case_study_25k_L33:24,746个案例,47,652,572字节
- case_study_25k_DSR1:24,746个案例,63,989,161字节
数据集用途
- 非结构化文本的时间序列建模
- 时间表示学习
- 生存分析
- 临床预测(下一事件预测)
- 多模态临床建模(文本、时间、人口统计、结果)
未来更新
- 将提供完整的125k数据集的DeepSeek-R1注释(目前25k子集已可用)。
致谢
- 数据集由美国国立医学图书馆(NLM)和卡内基梅隆大学的研究生成。
- 感谢PubMed开放获取计划和案例报告的作者。
搜集汇总
数据集介绍
构建方式
在生物医学信息学领域,PMOA-TTS数据集通过系统化处理PubMed开放获取病例报告构建而成。该数据集采用大型语言模型LLaMA 3.3对12.4万份临床病例报告进行自动化提取,形成结构化的时间序列数据。数据构建过程包含三个关键环节:从PMC文献中识别单病例报告,使用语言模型提取时间标记的临床事件序列,以及整合人口统计学特征、诊断信息和死亡表型标签。未来版本还将纳入DeepSeek-R1模型的完整注释,为比较研究提供更丰富的标注数据。
特点
该数据集最显著的特征在于其多维度临床时间序列表示能力。每条记录包含精确到小时级别的临床事件时间戳,与患者人口统计学特征、诊断清单及生存分析标签形成完整映射。特别设计的25k病例子集为计算密集型研究提供可行性,而经过人工校验的100例基准集则为模型评估提供可靠标准。数据字段设计兼顾临床实用性与机器学习需求,如死亡事件指示器与观察时间的结构化存储,直接支持生存分析等研究场景。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,默认分割包含完整训练集。针对不同研究目标,可选择特定子集:case_study_100适用于模型验证,两个25k子集则分别包含LLaMA 3.3和DeepSeek-R1的标注结果,便于进行标注质量对比研究。数据以JSON格式存储,临床事件时间序列、人口统计变量等字段可直接用于时间序列建模、生存分析或临床预测等任务。使用前需注意遵守CC BY NC SA 4.0许可协议,确保符合生物医学数据使用的伦理规范。
背景与挑战
背景概述
PMOA-TTS数据集是由美国国立医学图书馆(NLM)与卡内基梅隆大学联合构建的临床文本时间序列资源,源自PubMed开放获取平台收录的12.4万份临床病例报告。该数据集通过大语言模型(LLaMA 3.3和DeepSeek-R1)自动提取患者诊疗过程中的时间戳事件序列,整合人口统计学特征、诊断标签及死亡结局指标,旨在为时序建模、生存分析和临床预测等研究提供多模态数据支持。作为首个大规模结构化临床文本时序库,其创新性地将非结构化病历转化为可计算的时间事件轨迹,显著推进了医疗人工智能领域对病程动态演变规律的量化研究。
当前挑战
构建PMOA-TTS面临双重挑战:在领域问题层面,临床事件的时间不确定性表达、异构医疗术语的标准化映射、以及病例报告固有的选择偏倚,均对时序建模的鲁棒性提出严峻考验;在技术实现层面,大语言模型对医疗实体与时间关系的抽取准确率、缺失人口统计学数据的插补策略、以及不同标注模型(LLaMA与DeepSeek)输出结果的一致性校验,构成数据集构建过程中的核心难点。此外,病例报告文本中隐含的时间逻辑冲突(如矛盾的时间陈述)需通过多轮人工核查消除,这对保证数据质量提出极高要求。
常用场景
经典使用场景
在临床医学研究中,PMOA-TTS数据集以其丰富的时序临床事件记录为特色,为时间序列建模提供了理想的研究素材。研究者常利用该数据集中的文本化时间序列数据,探索患者病程发展的动态模式,特别是在疾病进展预测和治疗效果评估方面展现出独特价值。数据集内精确到小时的时间戳与结构化临床事件相结合,使得基于深度学习的序列建模方法能够捕捉疾病发展的潜在规律。
解决学术问题
该数据集有效解决了临床文本时序建模中的关键挑战,包括非结构化医疗记录的时序对齐问题和稀疏事件序列的表示学习难题。通过提供标准化的事件时间标注和死亡结局指标,显著提升了生存分析研究的可重复性。其大规模病例覆盖特性为罕见病病程研究提供了统计学基础,而多模态字段设计则推动了临床文本与结构化数据的融合建模方法创新。
衍生相关工作
基于该数据集衍生的经典研究包括《TemporalBERT》系列工作时序预训练模型,其创新性地将临床事件序列转化为可计算的语义表示。在生存分析领域,研究者提出的《SurvLLM》框架充分利用数据集中的死亡结局标注,建立了基于大语言模型的预后预测新范式。另有工作《ClinicalT5》通过多任务学习统一处理数据集中的事件预测与诊断分类任务,推动了临床文本理解的边界。
以上内容由遇见数据集搜集并总结生成


