candidate-matching-synthetic
收藏Hugging Face2026-01-19 更新2026-01-20 收录
下载链接:
https://huggingface.co/datasets/michaelozon/candidate-matching-synthetic
下载链接
链接失效反馈官方服务:
资源简介:
这是一个大规模高质量的合成数据集,专为简历-职位匹配和候选人检索任务设计。数据集包含10,000份合成简历、2,500份职位发布和2,500份真实匹配记录,适用于训练和评估候选人-职位匹配系统。数据集具有大规模(10,000+高质量简历)、真实数据(资历级别与工作经验年限对齐)、丰富特征(结构化技能和资历+非结构化摘要和项目符号)、真实匹配(基于技能的匹配,60%阈值验证)、多样覆盖(24个角色、10个行业、73个独特技能)和可用于生产(无缺失值,已验证完整性)等特点。数据集结构包括简历、职位和匹配记录三部分,涵盖了24个独特角色、10个行业(如金融科技、电子商务、SaaS、医疗保健、教育科技等)、3个资历级别(初级、中级、高级)和73个独特技能。数据集还提供了详细的数据统计、匹配算法、验证方法、使用案例、快速开始指南、探索性数据分析、数据生成方法、示例应用、数据集卡片、贡献指南、引用信息、致谢、联系方式和版本历史等内容。
This is a large-scale, high-quality synthetic dataset specifically designed for resume-job matching and candidate retrieval tasks. The dataset contains 10,000 synthetic resumes, 2,500 job postings, and 2,500 real matching records, suitable for training and evaluating candidate-job matching systems.
The dataset features multiple advantages: large scale (over 10,000 high-quality resumes), real-world alignment (seniority levels aligned with years of work experience), rich features (structured skills and seniority attributes plus unstructured summaries and bullet points), authentic matching (skill-based matching validated with a 60% threshold), diverse coverage (24 distinct job roles, 10 industries, 73 unique skills), and production readiness (no missing values, verified completeness).
The dataset structure includes three core components: resumes, job postings, and matching records, covering 24 unique job roles, 10 industries (e.g., fintech, e-commerce, SaaS, healthcare, edtech, etc.), three seniority levels (entry-level, mid-level, senior-level), and 73 unique skills.
Additionally, the dataset provides comprehensive supporting resources, including detailed data statistics, matching algorithms, validation methodologies, use cases, quick start guides, exploratory data analysis, data generation methods, sample applications, dataset cards, contribution guidelines, citation information, acknowledgments, contact information, and version history.
创建时间:
2026-01-18
原始信息汇总
数据集概述:Candidate-Job Matching Synthetic Dataset
基本信息
- 数据集名称:Candidate-Job Matching Synthetic Dataset
- 发布者:Michael Ozon
- 发布日期:2026年1月 (v1.0.0)
- 许可证:MIT License
- 语言:英语 (en)
- 任务类别:文本分类、句子相似性、信息检索
- 标签:招聘、职位匹配、简历筛选、语义搜索、嵌入、合成数据
- 数据规模:10K < n < 100K
数据集内容与规模
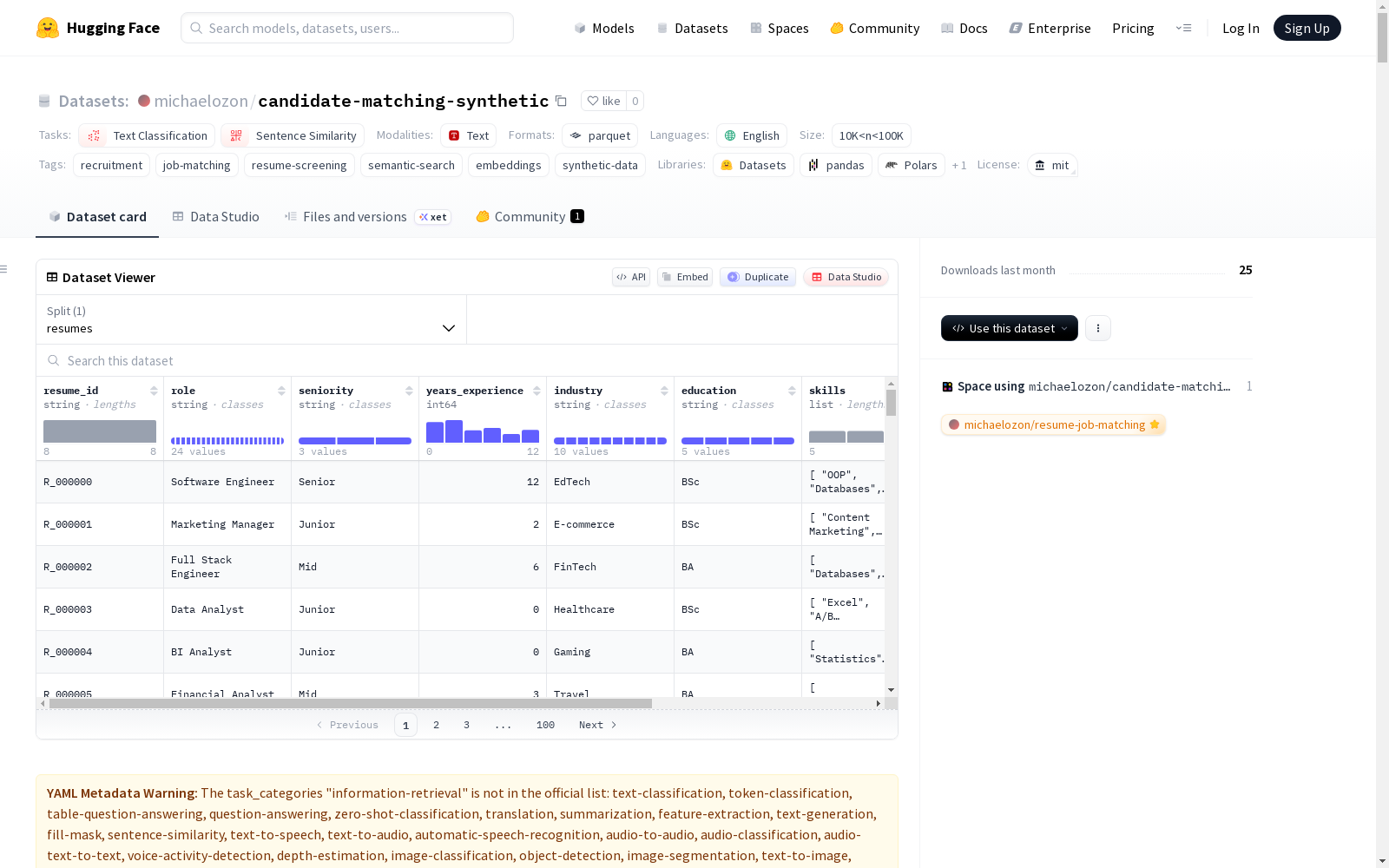
- 简历数据:10,000 条合成简历记录。
- 职位数据:2,500 条合成职位发布记录。
- 匹配数据:2,500 条地面真实匹配记录,包含 75,000 个职位-简历对。
- 数据分割:所有数据均位于
train分割中。
数据结构
1. 简历 (Resumes)
每条记录包含以下字段:
resume_id:简历唯一标识符。role:职位角色(共24种唯一角色)。seniority:资历级别(Junior, Mid, Senior)。years_experience:工作经验年限。industry:行业(共10个行业,如FinTech, E-commerce, SaaS等)。education:教育背景。skills:技能列表(共73种唯一技能)。summary:简历摘要。experience_bullets:经验要点列表。
2. 职位 (Jobs)
每条记录包含以下字段:
job_id:职位唯一标识符。job_title:职位标题。seniority:要求的资历级别。industry:行业。must_have_skills:必备技能列表。nice_to_have_skills:附加技能列表。description:职位描述。responsibilities:职责列表。requirements:要求列表。
3. 匹配 (Matches)
每条记录包含以下字段:
job_id:职位标识符。relevant_resume_ids:相关简历ID列表(平均每个职位30份简历)。
关键特征与质量
- 规模大:包含超过10,000份高质量合成简历。
- 真实性:工作经验年限与资历级别对齐。
- 特征丰富:结合了结构化(技能、资历)和非结构化(摘要、要点)特征。
- 地面真实:基于技能的匹配,经过60%阈值验证。
- 覆盖多样:涵盖24种角色、10个行业、73种独特技能。
- 生产就绪:无缺失值,已验证完整性。
- 数据质量:无缺失值、无重复记录、引用完整性100%、经验分布符合现实。
匹配算法与验证
- 匹配阈值:必备技能重叠度 ≥ 60%。
- 每职位候选人数:平均30份相关简历。
- 技能覆盖:供需之间技能100%重叠。
- 验证:基于技能的匹配,并针对资历和角色对齐进行了验证。
主要用途
- 语义职位-简历匹配:训练嵌入模型,基于语义相似性匹配候选人与职位发布。
- 候选人检索系统:构建生产就绪的检索系统(如密集嵌入、混合搜索、重排序模型)。
- 技能差距分析:分析就业市场中的技能供需情况。
- 经验水平预测:基于简历内容预测资历级别。
- 多模态匹配:结合结构化特征(技能、年限)与非结构化文本(摘要、要点)。
数据生成方法
- 基础模型:Qwen/Qwen2.5-0.5B-Instruct。
- 生成方法:批量生成。
- 硬件:Tesla T4 GPU (Google Colab)。
- 质量控制:结构化提示、技能池控制、经验验证、匹配逻辑。
- 可重复性:种子为42,生成时间约1.5小时,回退率约15-20%。
引用格式
bibtex @dataset{candidate_matching_synthetic_2026, author = {Michael Ozon}, title = {Candidate-Job Matching Synthetic Dataset}, year = {2026}, publisher = {HuggingFace}, url = {https://huggingface.co/datasets/michaelozon/candidate-matching-synthetic} }
快速统计摘要
| 指标 | 数值 |
|---|---|
| 简历总数 | 10,000 |
| 职位总数 | 2,500 |
| 匹配总数 | 75,000 对 |
| 独特角色 | 24 |
| 行业 | 10 |
| 独特技能 | 73 |
| 平均技能/简历 | 6.5 |
| 平均技能/职位 | 5.0 |
| 数据完整性 | 100% |
| 技能重叠度 | 100% |
搜集汇总
数据集介绍
构建方式
在人才招聘与智能匹配领域,高质量数据的稀缺性长期制约着相关模型的发展。本数据集采用前沿的大语言模型技术进行构建,以Qwen 2.5-0.5B-Instruct模型为核心,通过精心设计的结构化提示词批量生成了合成数据。生成过程严格遵循预设的验证规则,包括对技能池、经验年限与资历级别的对齐控制,并采用确定性回退机制确保数据质量。所有记录均经过严格的模式验证,最终形成了包含一万份简历、两千五百个职位及对应匹配关系的大规模语料库,其生成过程具备良好的可复现性。
特点
该数据集展现出多维度的高质量特性。其规模宏大,包含超过一万份结构丰富的简历与两千五百个职位描述,并提供了基于技能匹配的真实标签。数据在资历级别、行业与职能角色上分布均衡,覆盖了二十四个独特岗位、十个行业领域及七十三项技能,确保了广泛的代表性。尤为突出的是,数据集实现了简历技能与职位需求间的完全覆盖,且所有记录均无缺失值,具备完整的引用完整性,为模型训练与评估提供了坚实可靠的基础。
使用方法
该数据集为招聘场景下的信息检索与语义匹配任务提供了直接的应用支持。使用者可通过Hugging Face Datasets库便捷加载简历、职位及匹配关系三个独立配置。典型应用包括训练句子嵌入模型以实现简历与职位的语义相似度计算,构建结合稠密向量与稀疏检索的混合搜索系统,或进行技能供需差距分析。数据集中提供的真实匹配标签可直接用于评估检索模型的召回率等性能指标,为开发与验证生产级的候选人匹配系统提供了完整的实验平台。
背景与挑战
背景概述
在人工智能与人力资源技术交叉领域,候选人与职位匹配是核心研究议题,旨在通过算法高效连接人才与岗位。候选匹配合成数据集由Michael Ozon于2026年创建并发布,依托前沿大语言模型Qwen 2.5生成大规模合成数据。该数据集聚焦于简历与职位描述的语义匹配、技能检索及候选人推荐等任务,其构建涵盖了10,000份合成简历、2,500个职位发布及2,500条真实匹配记录,覆盖24种角色、10个行业与73项独特技能。通过精心设计的技能重叠阈值与经验对齐验证,该数据集为招聘领域的信息检索与嵌入模型训练提供了标准化基准,推动了语义搜索与混合检索系统的研究进展。
当前挑战
该数据集致力于解决招聘领域中候选人与职位高效精准匹配的挑战,其核心问题在于如何从多模态文本中提取语义特征,并实现技能、经验与岗位需求的结构化对齐。构建过程中的挑战主要体现在合成数据的真实性与多样性平衡:一方面需确保生成简历的年份经验与资历级别严格对应,避免分布失真;另一方面要维持技能池的广泛覆盖,使73项独特技能在供需两端完全重叠,以模拟真实市场动态。此外,生成过程需克服大语言模型的幻觉倾向,通过严格模式验证与确定性回退机制保障数据完整性,确保75,000对匹配记录均基于不低于60%的必要技能重叠阈值,从而为检索系统提供可靠的地面真值。
常用场景
经典使用场景
在人才招聘与信息检索领域,该数据集为简历与职位匹配任务提供了标准化的评估基准。研究者通常利用其大规模、高质量的合成数据,训练语义嵌入模型,以计算简历文本与职位描述之间的相似度。通过构建密集向量表示,系统能够从海量候选人中精准检索出与特定职位要求最契合的简历,实现高效的人岗匹配。
解决学术问题
该数据集有效解决了招聘场景中数据稀缺与隐私敏感的问题,为信息检索、自然语言处理等学术研究提供了可控的实验环境。它支持对语义匹配算法、技能提取技术以及多模态融合方法的系统性评估,助力研究者探索更精准的候选人检索模型,推动个性化推荐系统与智能人力资源管理的理论发展。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于Sentence-Transformers的嵌入模型比较、结合传统检索与神经排序的混合搜索框架,以及利用注意力机制进行多特征融合的匹配算法。这些工作不仅验证了数据集在召回率与精度方面的可靠性,还进一步拓展了其在跨领域迁移学习与小样本场景下的应用潜力。
以上内容由遇见数据集搜集并总结生成


