cad-sft
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/Hula0401/cad-sft
下载链接
链接失效反馈官方服务:
资源简介:
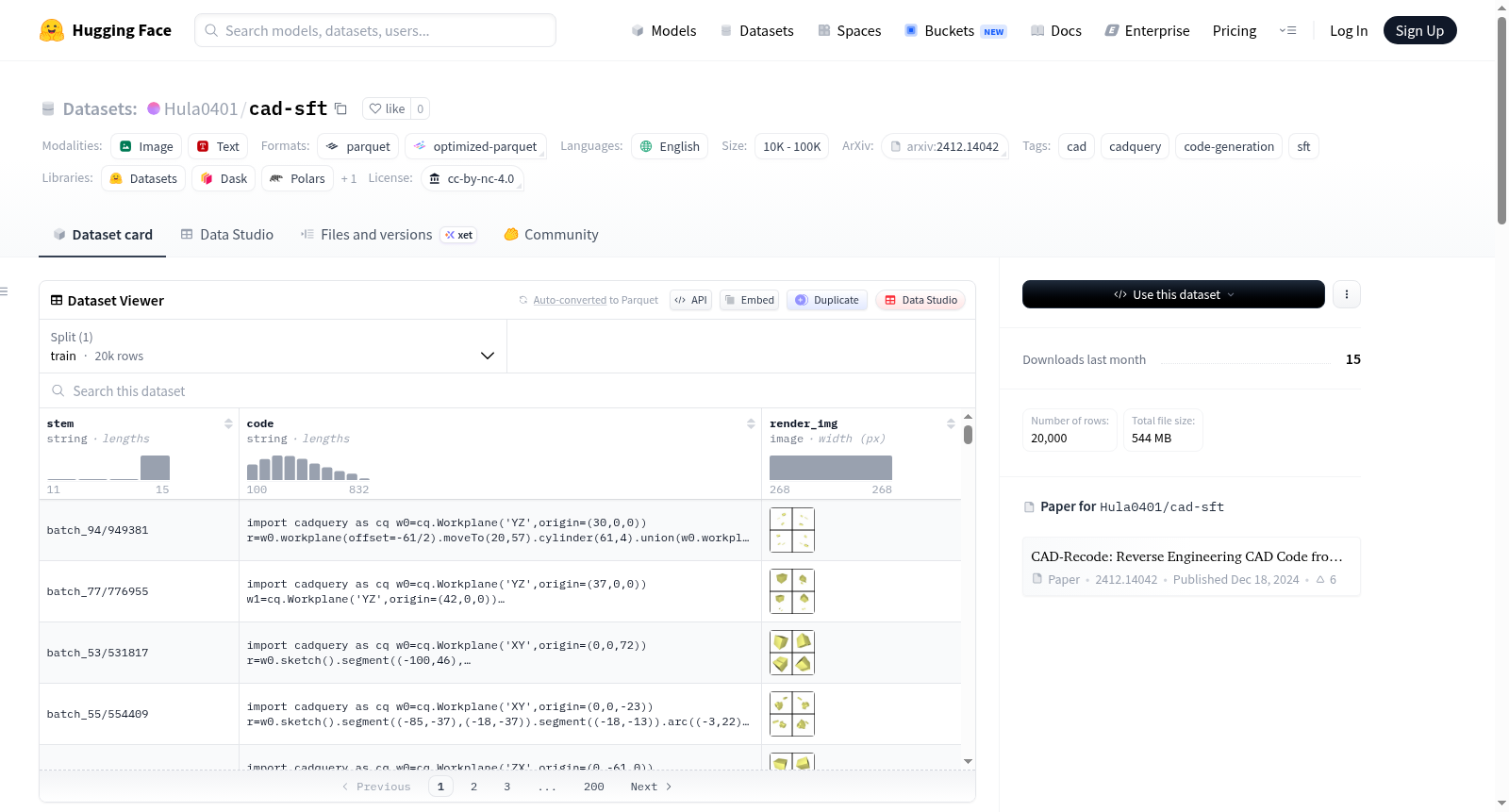
CAD-SFT 是一个用于CAD代码生成模型监督微调的数据集,包含经过重新格式化的CadQuery代码。数据集包含两个子集(10k和20k样本),每个样本包含三个字段:stem(字符串)、code(字符串)和render_img(图像)。原始几何内容保持不变,仅对Python源代码进行了重新布局,从单行紧凑格式转换为多行链式result = (...)形式,以提高可读性和语言模型训练效果。数据集来源于两个公开资源:cad-recode-v1.5和Text2CAD语料库,并继承了cc-by-nc-4.0许可协议。该数据集特别适用于CAD代码生成、程序合成和计算机辅助设计相关的研究与应用。
CAD-SFT is a dataset for supervised fine-tuning of CAD code generation models, containing reformatted CadQuery code. The dataset includes two subsets (10k and 20k samples), with each sample containing three fields: stem (string), code (string), and render_img (image). The original geometric content remains unchanged; only the Python source code has been rearranged from a single-line compact format to a multi-line chained `result = (...)` form to enhance readability and the effectiveness of language model training. The dataset is derived from two public resources: cad-recode-v1.5 and the Text2CAD corpus, and adopts the CC-BY-NC-4.0 license. This dataset is particularly applicable to research and applications related to CAD code generation, program synthesis, and computer-aided design.
创建时间:
2026-04-24
原始信息汇总
数据集概述:CAD-SFT (reformatted)
基本信息
- 数据集名称:CAD-SFT (reformatted)
- 许可协议:CC-BY-NC-4.0(继承自上游CAD-Recode v1.5)
- 语言:英语
- 标签:CAD、CadQuery、代码生成、SFT
- 仓库地址:https://huggingface.co/datasets/Hula0401/cad-sft
数据集描述
该数据集是经过重新格式化(漂亮打印)的CadQuery代码,专为CAD代码生成模型的监督微调(SFT)而设计。它仅对Python源代码的布局进行了调整(从单行紧凑形式转换为多行链式调用形式),而几何内容保持不变,使其更适合语言模型训练且更易于阅读。
数据子集
数据集包含两个子集,分别来自不同的已发布来源:
| 子集名称 | 样本数量 | 文件大小 | 特征 |
|---|---|---|---|
| cad-recode-10k | 10,000 | 约198 MB | stem(字符串)、code(字符串)、render_img(图像) |
| cad-recode-20k | 20,000 | 约397 MB | stem(字符串)、code(字符串)、render_img(图像) |
所有数据均为训练集(train),无验证集或测试集划分。
数据内容与结构
text2cad/目录:包含171,177个重新格式化的.py文件,以及train.pkl、val.pkl、test.pklcad-recode-v1.5/目录:包含981,865个重新格式化的.py文件(分布在100个批次中),以及982个验证文件、train.pkl、val.pkl和README.md
来源与引用
- cad-recode-v1.5 子集:源自 filapro/cad-recode-v1.5
- 引用论文:Rukhovich等人,2024年,《CAD-Recode: Reverse Engineering CAD Code from Point Clouds》,arXiv:2412.14042
- text2cad 子集:基于Text2CAD语料库,重新用CadQuery代码表达
格式差异示例
原始格式(紧凑单行): python import cadquery as cq w0=cq.Workplane(XY,origin=(-100,0,-14)) r=w0.sketch().face(w0.sketch().push([(100,0)]).circle(100)).finalize().extrude(28)
重新格式化后(多行链式): python import cadquery as cq
result = ( cq.Workplane(XY, origin=(-100, 0, -14)) .sketch() .face( cq.Workplane(XY, origin=(-100, 0, -14)) .sketch() .push([(100, 0)]) .circle(100) ) .finalize() .extrude(28) )
使用方法
解压文件时使用 tar xf <archive> 命令,目录结构与上游布局一致。数据以Parquet格式存储,可通过Hugging Face Datasets库加载。
搜集汇总
数据集介绍
构建方式
CAD-SFT数据集专为CAD代码生成模型的监督微调而设计,其构建方式源于对已有数据集文本的重新编排。具体而言,该数据集对来自Text2CAD语料库和CAD-Recode v1.5的原始CadQuery代码进行了格式化转换,将原本紧凑的单行代码重构为多行链式调用形式(如`result = (…)`),从而提升了代码的可读性与语言模型训练的友好度。这一过程严格保留了原始几何内容与功能性,仅调整Python源代码的布局结构。数据集包含两个子集:cad-recode-10k和cad-recode-20k,分别提供10,000个和20,000个训练样本,每个样本由文本描述(stem)、重构后的代码(code)以及渲染图像(render_img)三部分构成,源于研究机构发布的公开资源。
特点
CAD-SFT数据集的核心特点在于其高度的结构化与可操作性,旨在弥合CAD领域自然语言指令与程序代码生成之间的鸿沟。首先,数据集的格式化输出通过将原先一行式代码分解为层次分明的链式方法调用,显著增强了模型对CAD建模操作序列的理解能力。其次,每个样本均附带渲染图像作为视觉佐证,使得代码与最终三维形状的对应关系更为直观。此外,数据集规模宏大,包含来自两大来源的超过一百万个重新格式化的Python文件,覆盖广泛的几何构造模式,为训练鲁棒的代码生成模型提供了丰富的训练素材。最后,数据遵循cc-by-nc-4.0许可协议,适用于非商业研究与学术探索。
使用方法
使用CAD-SFT数据集时,用户可通过HuggingFace的datasets库便捷加载子集,例如指定`config_name='cad-recode-10k'`以获取10k规模数据。每个样本以字典形式提供,包含`stem`(建模任务的自然语言描述)、`code`(多行格式的CadQuery代码)及`render_img`(对应渲染图像)。数据文件以tar.gz压缩包组织,解压后目录结构保留上游布局,便于集成到现有流水线。在微调语言模型时,可直接将`stem`字段作为输入,以`code`字段作为目标输出进行训练。此外,数据集提供训练/验证/测试划分(如cad-recode-v1.5子集包含验证集和测试集),支持标准的模型评估流程,用户可根据需求灵活选择全量数据或特定子集展开实验。
背景与挑战
背景概述
CAD-SFT数据集诞生于计算机辅助设计(CAD)与人工智能深度融合的背景下,旨在推动基于自然语言或代码的CAD模型自动生成技术发展。该数据集由研究人员Danila Rukhovich、Elona Dupont等跨机构团队于2024年构建,其核心研究问题在于如何利用监督微调(SFT)方法提升语言模型对CAD程序代码的生成能力。通过将来自CAD-Recode v1.5和Text2CAD两大权威来源的CadQuery代码进行多行格式化重排,数据集为模型提供了更友好、易解析的训练样本,显著降低了模型学习CAD几何构建逻辑的难度。作为面向代码生成任务的专用资源,CAD-SFT在促进CAD设计自动化、加速工程建模流程方面具有重要影响力,为后续研究奠定了坚实的基准基础。
当前挑战
CAD-SFT所应对的核心领域挑战在于CAD程序代码的自动生成——即从文本描述或点云数据转化为可执行的几何建模指令,这一任务要求模型同时理解程序语法结构、空间几何逻辑以及用户设计意图。在构建过程中,数据集面临多重困难:原始来源于CAD-Recode v1.5和Text2CAD的代码采用紧凑单行格式,难以被语言模型有效学习,需在不改变几何内容的前提下进行复杂的多行重排,保留原始语义的完整性与计算等价性;同时,处理超过百万级规模的代码文件(如981,865个文件)需要稳定高效的数据清洗与格式化流水线;此外,跨数据集整合时需兼容不同源的代码风格与注释规范,并确保许可证(cc-by-nc-4.0)的合规性。
常用场景
经典使用场景
CAD-SFT数据集专为计算机辅助设计(CAD)领域的代码生成模型而构建,其核心应用场景在于对大型语言模型进行监督式微调,使之能够从自然语言描述或部分几何提示中自动生成结构化的CadQuery代码。该数据集将原始的紧凑型单行代码重构为多行链式调用形式,极大提升了代码的可读性与模型对上下文依赖关系的理解能力,因此成为训练面向CAD编程任务的代码生成模型的标准数据资源。
衍生相关工作
基于CAD-SFT数据集,研究者已衍生出多项重要工作,例如CAD-Recode项目利用该数据微调代码生成模型,实现从点云到CAD程序的反向工程。此外,该数据集的格式化版本为后续研究提供了统一基准,催生了更高效的代码表示学习方法,并在模型对比评估中成为标准测试集。这些工作共同推动了CAD代码生成从学术探索走向工业级应用。
数据集最近研究
最新研究方向
CAD-SFT数据集聚焦于计算机辅助设计(CAD)领域中代码生成模型的有监督微调,通过将紧凑型CadQuery代码重构为多行链式调用格式,显著提升语言模型对CAD程序的理解与生成能力。当前前沿探索包括基于该数据集训练专用大语言模型(如CAD-LLM),实现从自然语言描述或三维点云到参数化CAD建模脚本的端到端转换;同时推动逆向工程方向,如CAD-Recode项目从点云反向生成CadQuery代码,加速数字孪生与工业4.0场景下的自动化设计流程。该数据集的发布为构建符合工程直觉的生成式CAD工具提供了关键训练基准,有望降低专业设计门槛并推动智能制造的范式变革。
以上内容由遇见数据集搜集并总结生成


