maixuanvan/dhh2026-tqa-output
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/maixuanvan/dhh2026-tqa-output
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- vi
pretty_name: DHH2026 TQA Output
task_categories:
- question-answering
- text-classification
task_ids:
- multiple-choice-qa
size_categories:
- 10K<n<100K
configs:
- config_name: eval_ready
default: true
data_dir: processed/eval_ready_hf
drop_labels: true
- config_name: full
data_dir: processed/full_hf
drop_labels: true
license: other
tags:
- legal
- vietnamese
- education
- multiple-choice
- bloom-taxonomy
- multimodal
---
# DHH2026 TQA Output
This repository hosts the released output of the TQA pipeline for Vietnamese legal question answering. The release is centered on two subsets under `processed/`:
- `full`: the full processed dataset released by the pipeline, exposed on the Hub through `processed/full_hf/data/metadata.jsonl` so multimodal rows can render their associated images in the Dataset Viewer.
- `eval_ready`: a benchmark-ready subset with normalized 4-option MCQs, explicit gold index/letter, document-level train/validation/test split assignments, and a conservative language-sanity filter to exclude multilingual generation outliers. On the Hub, this subset is exposed via `data_dir: processed/eval_ready_hf`, where each split directory contains a `metadata.jsonl` and colocated images so the Dataset Viewer can load it as an image dataset instead of plain JSON.
The dataset is intended for research on Vietnamese legal QA, multiple-choice evaluation, and Bloom-level reasoning analysis.
## Dataset Summary
- Language: Vietnamese
- Domain: legal education and doctrinal law materials
- Source documents: 48
- Public full-release records: 14,998
- Eval-ready records: 14,210
- Multimodal records in full release after audit: 37
- Bloom levels: `Remember`, `Understand`, `Apply`
Pipeline-derived summary statistics:
- Raw QA pairs: 16,704
- Pipeline-kept records before public cleanup: 16,158
- Public-release removals for multilingual/prompt-leak artifacts: 1,160
- Public full release after sanitation: 14,998
- Rejected during filtering: 546
- Filter pass rate: 96.73%
- Average question length: 126.3 characters
- Average context length: 1,735.5 characters
Eval-ready subset statistics:
- Retention from public full release: 94.75%
- Train/validation/test records: 9,894 / 2,144 / 2,172
- Gold-answer positions are near-uniform `A/B/C/D = 3,544 / 3,564 / 3,557 / 3,545`
- Conservative language-sanity cleanup removed 487 multilingual or scaffold-contaminated rows from the public benchmark subset
- Conservative multimodal-quality audit demoted 21 artifact rows back to text-only, leaving 29 visually grounded eval-ready rows
## Files
### `processed/dataset.jsonl`
This is the public full release after a conservative sanitation pass. The pass:
- stripped harmless English scaffolding such as `(full correct answer text)` from 2,543 rows, and
- removed 1,160 rows that still contained multilingual or prompt-leak artifacts after sanitation.
- adds Hugging Face-friendly image references for multimodal rows via `image_file_name` and `image_file_names`
- demotes low-value multimodal artifacts (covers, logos, malformed visual summaries) back to text-only during the public multimodal audit
Each line is a JSON object with the following top-level fields:
- `qa_id`
- `domain_tag`
- `bloom_level`
- `context_payload`
- `question_content`
- `is_multimodal`
- `candidate_answers`
- `ground_truth`
- `legal_rationale`
For easier display in the Hugging Face Dataset Viewer, each row also includes:
- `context_text`: flattened text extracted from `context_payload.text`
- `visuals`: flattened visual references extracted from `context_payload.visuals`
- `image_file_name`: the first relative image path for Viewer preview on multimodal rows
- `image_file_names`: all relative image paths attached to the row
`context_payload` remains available for traceability and contains:
- `text`: the extracted instructional/legal context used to generate the item
- `visuals`: auxiliary visual references when present
### `processed/full_hf/data/metadata.jsonl`
This is the Hub-facing metadata file used by the `full` config. It mirrors the public full-release schema, adds `file_name` and `file_names`, and colocates all referenced images under `processed/full_hf/data/images/` so Hugging Face can infer an image feature for multimodal rows.
### `processed/eval_ready/{train,dev,test}.jsonl`
These files are derived from `processed/dataset_eval_ready.jsonl`. They keep only benchmark-ready 4-option MCQs with normalized gold labels, document-level split assignments, and a conservative public-release language filter. They additionally include:
- `candidate_answers_raw`
- `ground_truth_raw`
- `gold_index`
- `gold_letter`
- `doc_id`
- `chunk_id`
- `split`
- `eval_ready`
- `eval_ready_meta`
- `image_file_name`
- `image_file_names`
This is the recommended subset for benchmarking and model evaluation. In the Hub-facing image layout, `dev.jsonl` is exported into the `validation/` directory so that the Viewer follows the documented `train` / `validation` / `test` convention.
### `processed/eval_ready_hf/{train,validation,test}/metadata.jsonl`
These are the Hub-facing files used under `data_dir: processed/eval_ready_hf`. Each split directory contains:
- a `metadata.jsonl` file that mirrors the benchmark schema,
- a `file_name` column for the first image attached to a row,
- a `file_names` column for the full image list, and
- a colocated `images/` directory with relative paths that the Hugging Face Dataset Viewer can auto-cast as images.
This split-local layout follows the Hugging Face `imagefolder` convention, which is stricter than simply adding string paths to a generic JSONL dataset loaded via `data_files`.
### `processed/eval_ready/images/`
This directory contains the 17 unique image files still referenced by multimodal rows after the public multimodal audit. The metadata files use relative image paths so that the Hugging Face Dataset Viewer can render image previews directly for rows where `is_multimodal = true`.
## Splits
Document-level splits were assigned to reduce document leakage:
- `train`: 9,894 items
- `validation` (from `dev.jsonl`): 2,144 items
- `test`: 2,172 items
Multimodal rows remaining in the eval-ready release:
- `train`: 12
- `validation`: 4
- `test`: 13
Split assignment in the eval-ready file is document-aware and inherited from a context manifest built over 48 source documents.
## Recommended Usage
For benchmarking, use:
```python
from datasets import load_dataset
ds = load_dataset("maixuanvan/dhh2026-tqa-output", "eval_ready", split="train")
```
This loads the Hub-facing split from `processed/eval_ready_hf`, including the auto-cast image column for multimodal rows once the Hub re-indexes the imagefolder config.
For the validation split:
```python
val_ds = load_dataset("maixuanvan/dhh2026-tqa-output", "eval_ready", split="validation")
```
If you need the wider processed release with all pipeline-kept records, use:
```python
full_ds = load_dataset("maixuanvan/dhh2026-tqa-output", "full", split="data")
```
This loads the Hub-facing full-release directory from `processed/full_hf`, including the auto-cast image column for multimodal rows once the Hub re-indexes the imagefolder config.
## Data Schema Notes
- The two Hugging Face configs have different schemas: `full` exposes the broader processed release, while `eval_ready` adds benchmark-only fields such as `gold_index`, `gold_letter`, `doc_id`, `chunk_id`, and `split`.
- Multimodal rows in the public JSONL release include `image_file_name` for the first image preview and `image_file_names` for the full image list.
- The Hub-facing `full` and `eval_ready` configs are intentionally served through `data_dir` directories that follow the `imagefolder` convention, so `file_name` can be inferred as an image feature instead of a plain string.
- `candidate_answers` is a list of answer options.
- In the eval-ready file, `ground_truth` is the cleaned gold answer text after normalization.
- `gold_index` and `gold_letter` provide the gold answer position after deterministic option rebalancing.
- `bloom_level` captures the intended cognitive level of the item.
- `domain_tag` is pipeline-provided and may be coarse for some subjects.
## Intended Uses
- Benchmarking Vietnamese legal QA systems
- Evaluating instruction-tuned LLMs on legal MCQs
- Studying Bloom-level performance differences
- Building train/dev/test experiments with document-level separation
## Limitations
- The dataset is derived from instructional and legal study materials; it should not be treated as authoritative legal advice.
- `domain_tag` is not a gold-standard taxonomy for all records.
- Multimodal coverage is limited relative to the full textual corpus.
- The eval-ready subset excludes records whose gold answer could not be resolved cleanly.
## Licensing And Access
This card labels the dataset as `license: other` because the repository contains pipeline outputs derived from source educational/legal materials. Users are responsible for verifying that their use complies with the rights and restrictions applicable to the original source documents.
If this repository is kept private, access requires a Hugging Face token with repository read permission.
## Citation
If you use this dataset in research, cite the associated TQA pipeline project and this dataset repository:
```bibtex
@dataset{dhh2026_tqa_output,
title = {DHH2026 TQA Output},
author = {Mai Xuan Van},
year = {2026},
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/maixuanvan/dhh2026-tqa-output}
}
```
语言:
- 越南语(Vietnamese)
美观名称:DHH2026 TQA 输出
任务类别:
- 问答(question-answering)
- 文本分类(text-classification)
任务类型:
- 多项选择问答(multiple-choice-qa)
规模类别:
- 1万至10万条数据
配置项:
- 配置名称:评估就绪版(eval_ready)
默认:是
数据目录:processed/eval_ready_hf
移除标签:是
- 配置名称:完整版(full)
数据目录:processed/full_hf
移除标签:是
许可证:其他
标签:
- 法律(legal)
- 越南语(vietnamese)
- 教育(education)
- 多项选择(multiple-choice)
- 布鲁姆分类法(Bloom Taxonomy)
- 多模态(multimodal)
# DHH2026 TQA 输出
本仓库托管面向越南语法律问答的TQA流水线发布的输出结果。本次发布围绕`processed/`目录下的两个子集展开:
- `full`:流水线发布的完整处理后数据集,通过`processed/full_hf/data/metadata.jsonl`在Hugging Face Hub上对外暴露,使得多模态数据行可在数据集查看器(Dataset Viewer)中渲染关联图片。
- `eval_ready`:适配基准测试的子集,包含标准化的4选项多项选择题(Multiple-Choice Questions,MCQs)、明确的标准答案索引/字母标识、基于文档级别的训练/验证/测试集划分,以及用于过滤多语言生成异常值的保守语言合理性过滤器。在Hugging Face Hub上,该子集通过`data_dir: processed/eval_ready_hf`对外暴露,每个拆分目录均包含`metadata.jsonl`与配套图片,使数据集查看器可将其作为图片数据集而非纯JSON加载。
本数据集旨在服务于越南语法律问答、多项选择评估以及布鲁姆层级推理分析相关研究。
## 数据集摘要
- 语言:越南语
- 领域:法律教育与教义法学资料
- 源文档数量:48份
- 公开完整版数据条目:14998条
- 评估就绪版数据条目:14210条
- 审核后完整版中的多模态数据条目:37条
- 布鲁姆认知层级:记忆(Remember)、理解(Understand)、应用(Apply)
## 流水线衍生统计摘要
- 原始问答对数量:16704对
- 公开清理前流水线保留的数据条目:16158条
- 因多语言/提示泄露异常样本被移除的公开发布条目:1160条
- 数据净化后的公开完整版条目:14998条
- 过滤阶段被拒绝的条目:546条
- 过滤通过率:96.73%
- 平均问题长度:126.3字符
- 平均上下文长度:1735.5字符
## 评估就绪子集统计
- 源自公开完整版的留存率:94.75%
- 训练/验证/测试集条目数:9894 / 2144 / 2172
- 标准答案位置分布近似均匀:`A/B/C/D = 3544 / 3564 / 3557 / 3545`
- 保守语言合理性清理从公开基准子集中移除了487条多语言或框架污染的数据行
- 保守多模态质量审核将21条异常样本数据行降级为纯文本模式,最终保留29条具备视觉支撑的评估就绪数据行
## 文件说明
### `processed/dataset.jsonl`
该文件为经过保守数据净化后的公开完整版发布数据。本次净化流程包括:
- 从2543条数据行中移除了无害的英文框架文本(如`(full correct answer text)`),以及
- 移除了1160条在净化后仍包含多语言或提示泄露异常样本的数据行
- 通过`image_file_name`与`image_file_names`字段为多模态数据行添加了适配Hugging Face的图片引用
- 在公开多模态审核阶段,将低价值的多模态异常样本(如封面、标识、格式错误的视觉摘要)降级为纯文本模式
每行均为JSON对象,包含以下顶层字段:
- `qa_id`
- `domain_tag`
- `bloom_level`
- `context_payload`
- `question_content`
- `is_multimodal`
- `candidate_answers`
- `ground_truth`
- `legal_rationale`
为适配Hugging Face数据集查看器的展示,每条数据还额外包含:
- `context_text`:从`context_payload.text`中提取的扁平化文本
- `visuals`:从`context_payload.visuals`中提取的扁平化视觉引用
- `image_file_name`:多模态数据行用于查看器预览的首张图片相对路径
- `image_file_names`:当前数据行关联的所有相对图片路径
`context_payload`字段保留用于溯源,其包含:
- `text`:用于生成当前数据条目的提取式教学/法律上下文文本
- `visuals`:若存在则为辅助视觉引用
### `processed/full_hf/data/metadata.jsonl`
该文件是`full`配置所使用的Hub对外元数据文件。它与公开完整版的 schema 保持一致,额外添加了`file_name`与`file_names`字段,并将所有引用图片存储在`processed/full_hf/data/images/`目录下,以便Hugging Face为多模态数据行自动识别图片特征。
### `processed/eval_ready/{train,dev,test}.jsonl`
这些文件源自`processed/dataset_eval_ready.jsonl`,仅保留适配基准测试的4选项多项选择题,包含标准化的标准答案标签、文档级别划分信息以及保守的公开发布语言过滤器。此外还包含以下字段:
- `candidate_answers_raw`
- `ground_truth_raw`
- `gold_index`
- `gold_letter`
- `doc_id`
- `chunk_id`
- `split`
- `eval_ready`
- `eval_ready_meta`
- `image_file_name`
- `image_file_names`
本子集为基准测试与模型评估的推荐使用子集。在Hub对外的图片布局中,`dev.jsonl`被导出至`validation/`目录,以遵循文档中定义的`train`/`validation`/`test`命名惯例。
### `processed/eval_ready_hf/{train,validation,test}/metadata.jsonl`
这些文件是`data_dir: processed/eval_ready_hf`所使用的Hub对外文件。每个拆分目录均包含:
- 与基准测试 schema 一致的`metadata.jsonl`文件
- 用于表示数据行首张图片的`file_name`字段
- 用于表示完整图片列表的`file_names`字段
- 配套的`images/`目录,其中的相对路径可被Hugging Face数据集查看器自动识别为图片格式
该拆分本地布局遵循Hugging Face的`imagefolder`惯例,相较于仅将字符串路径添加至通过`data_files`加载的通用JSONL数据集而言,该规范更为严格。
### `processed/eval_ready/images/`
该目录包含经过公开多模态审核后,评估就绪子集中多模态数据行所引用的17张唯一图片文件。元数据文件使用相对图片路径,以便Hugging Face数据集查看器可直接为`is_multimodal = true`的数据行渲染图片预览。
## 数据集拆分
为降低文档泄露风险,本次划分采用文档级别的拆分策略:
- `train`:9894条数据
- `validation`(源自`dev.jsonl`):2144条数据
- `test`:2172条数据
评估就绪子集中的多模态数据行分布:
- `train`:12条
- `validation`:4条
- `test`:13条
评估就绪文件中的拆分分配基于文档感知策略,继承自基于48份源文档构建的上下文清单。
## 推荐使用方式
若需进行基准测试,请使用:
python
from datasets import load_dataset
ds = load_dataset("maixuanvan/dhh2026-tqa-output", "eval_ready", split="train")
该代码将从`processed/eval_ready_hf`加载Hub对外的训练拆分,待Hub重新索引imagefolder配置后,将自动包含多模态数据行的图片特征列。
针对验证拆分:
python
val_ds = load_dataset("maixuanvan/dhh2026-tqa-output", "eval_ready", split="validation")
若需获取包含所有流水线保留条目的更广泛处理后发布版本,请使用:
python
full_ds = load_dataset("maixuanvan/dhh2026-tqa-output", "full", split="data")
该代码将从`processed/full_hf`加载Hub对外的完整发布目录,待Hub重新索引imagefolder配置后,将自动包含多模态数据行的图片特征列。
## 数据模式说明
- 两个Hugging Face配置拥有不同的schema:`full`配置暴露更广泛的处理后发布版本,而`eval_ready`配置则添加了仅用于基准测试的字段,如`gold_index`、`gold_letter`、`doc_id`、`chunk_id`与`split`。
- 公开JSONL发布版本中的多模态数据行包含用于首张图片预览的`image_file_name`字段,以及用于完整图片列表的`image_file_names`字段。
- Hub对外的`full`与`eval_ready`配置均通过遵循`imagefolder`惯例的`data_dir`目录对外提供服务,因此`file_name`字段可被自动识别为图片特征而非普通字符串。
- `candidate_answers`为答案选项列表。
- 在评估就绪文件中,`ground_truth`为经过标准化清理后的标准答案文本。
- `gold_index`与`gold_letter`提供经过确定性选项重平衡后的标准答案位置。
- `bloom_level`用于表示当前数据条目的预期认知层级。
- `domain_tag`由流水线生成,部分主题的分类可能较为粗略。
## 预期用途
- 基准测试越南语法律问答系统
- 评估针对法律多项选择题的指令微调大语言模型(Large Language Model,LLM)
- 研究布鲁姆层级下的性能差异
- 基于文档级别划分构建训练/开发/测试实验
## 局限性
- 本数据集源自教学与法律学习资料,不应被视为权威法律建议。
- `domain_tag`并非所有数据条目的黄金标准分类法。
- 相较于完整文本语料库,多模态覆盖范围有限。
- 评估就绪子集排除了无法清晰解析标准答案的数据条目。
## 许可证与访问方式
本数据集卡片标注为`license: other`,因为本仓库包含源自源教育/法律资料的流水线输出结果。用户需自行验证其使用行为是否符合原始源文档的权利与限制要求。
若本仓库设置为私有,则需使用具备仓库读取权限的Hugging Face令牌方可访问。
## 引用说明
若您在研究中使用本数据集,请引用关联的TQA流水线项目与本数据集仓库:
bibtex
@dataset{dhh2026_tqa_output,
title = {DHH2026 TQA 输出},
author = {梅春凡(Mai Xuan Van)},
year = {2026},
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/maixuanvan/dhh2026-tqa-output}
}
提供机构:
maixuanvan
搜集汇总
数据集介绍
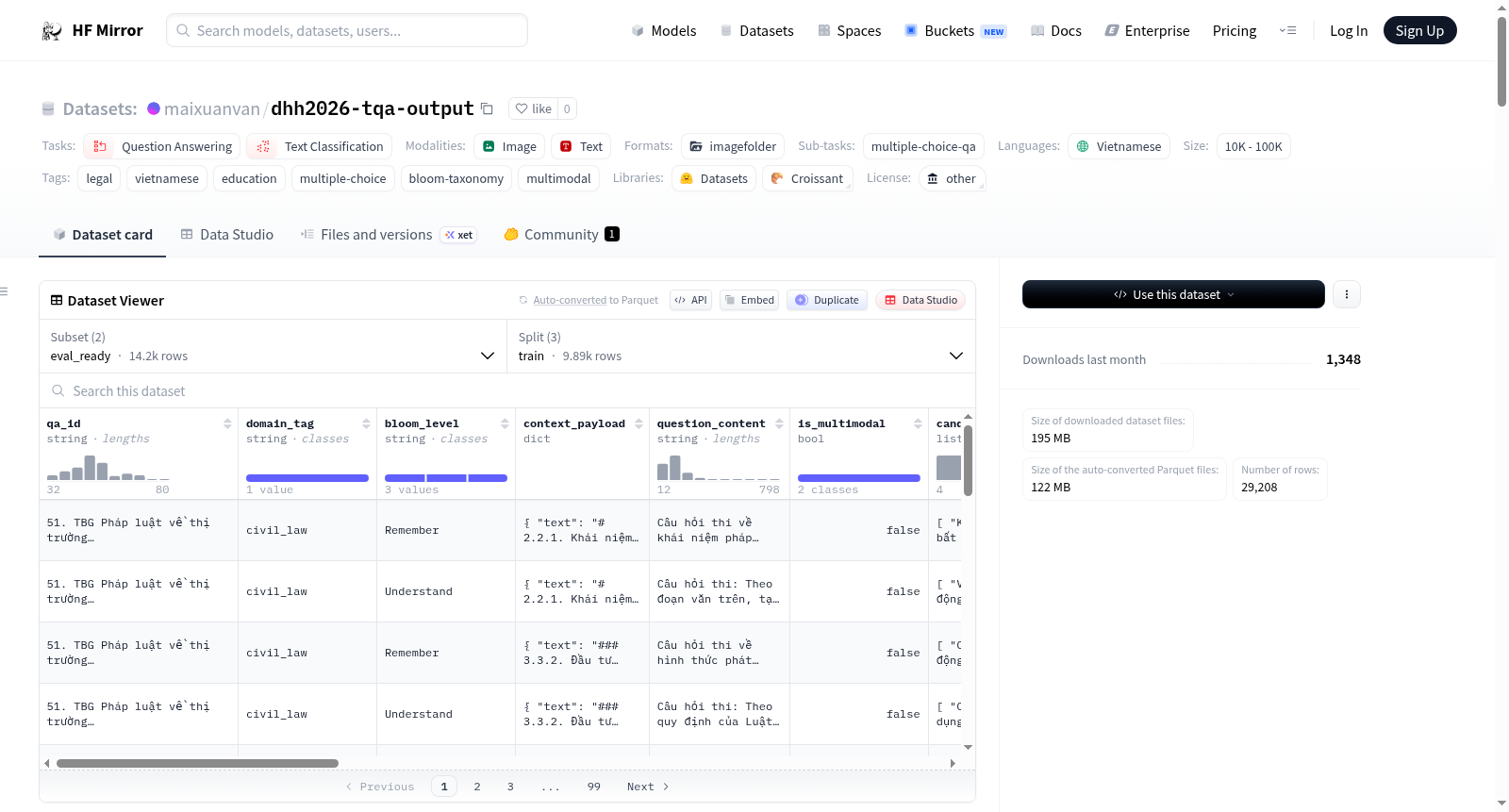
构建方式
在越南法律教育领域,数据集的构建依托于自动化问答生成流程,从四十八份法律教学文档中提取原始问答对。经过多轮清洗与筛选,原始数据经历了去除多语言混杂及提示泄露等噪声的净化处理,最终形成包含一万四千余条记录的全量数据集。为进一步适配基准评测需求,从中衍生出具备标准化四选项选择题格式的评估就绪子集,该子集通过文档级划分策略分配训练、验证与测试样本,有效避免了文档内容泄露对模型评估的干扰。
特点
本数据集以越南法律问答为核心,其显著特征在于融合了布鲁姆认知分类体系,将问题划分为记忆、理解与应用三个层次,为研究认知难度与模型性能关联提供了结构化标注。数据呈现多模态特性,部分条目关联法律图表等视觉材料,尽管视觉样本数量有限,却拓展了法律文本理解的维度。评估就绪子集经过严格的答案位置均衡处理,确保选项分布接近均匀,同时通过语言纯净度过滤剔除多语言混杂条目,保障了评测结果的可靠性与一致性。
使用方法
针对不同研究目的,数据集提供了两种配置模式。若需进行模型基准测试,推荐加载评估就绪配置,该配置已预置文档级划分,并支持图像特征的自动解析,便于直接用于法律问答系统的性能评估。若希望探索更广泛的原始生成结果,可选用全量配置以获取包含全部净化后记录的数据。数据加载过程遵循Hugging Face标准接口,通过指定配置名称与分割集即可便捷访问,其图像文件夹布局设计使得多模态样本能在数据集查看器中直接预览关联图像。
背景与挑战
背景概述
VDTM-LegalQA数据集由Mai Xuan Van于2026年发布,旨在为越南法律领域的问答系统研究提供高质量基准资源。该数据集源自48份法律教育及学说材料,通过自动化流程生成并经过严格清洗,最终包含近1.5万条记录,涵盖记忆、理解与应用三个布鲁姆认知层次。其核心研究问题聚焦于如何构建一个适用于越南语的法律多选问答评估体系,以推动自然语言处理在法律文本理解、推理分析及多模态学习方面的发展,对东南亚地区法律人工智能研究具有重要参考价值。
当前挑战
该数据集致力于解决越南法律问答任务中的领域挑战,包括处理复杂法律术语的语义理解、依据布鲁姆分类进行多层次推理评估,以及整合有限的多模态信息以增强上下文表征。在构建过程中,研究团队面临多重困难:需从原始文档中自动化提取并清洗问答对,同时消除多语言混杂及提示泄露等噪声;为确保评估可靠性,必须实施严格的文档级数据划分以避免信息泄漏,并对多模态内容进行质量审核以剔除低价值视觉样本,这些步骤均对数据集的规模与一致性提出了较高要求。
常用场景
经典使用场景
在越南法律智能问答研究领域,VDTM-LegalQA数据集为评估模型在法律文本理解与推理方面的能力提供了标准化基准。其经典使用场景聚焦于多选问答任务,研究者利用该数据集训练和测试模型对越南法律条文及教育材料的理解深度,特别是在记忆、理解和应用三个布鲁姆认知层级上的表现。数据集经过精心划分的训练、验证和测试子集,确保了评估过程的严谨性,有效支撑了法律领域自然语言处理技术的迭代与优化。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,主要集中在越南语法律大语言模型的指令微调与评估框架构建上。研究者利用其标准化评测子集,系统比较了不同预训练模型在法律多选问答任务上的性能,并深入分析了模型在布鲁姆各认知层级的表现差异。这些工作不仅验证了数据集的实用价值,也进一步推动了针对低资源语言和法律垂直领域的模型适配与评估方法论创新。
数据集最近研究
最新研究方向
在越南法律智能问答领域,VDTM-LegalQA数据集正推动多项前沿研究。其融合多模态元素与布鲁姆分类法的设计,为探索法律文本理解与推理机制提供了新视角。当前研究热点集中于利用该数据集评估大语言模型在复杂法律多选题上的表现,特别是模型在不同认知层级(记忆、理解、应用)上的能力差异。同时,数据集严格的文档级划分避免了信息泄露,使得基于它的模型评估更具鲁棒性和可信度。这些研究不仅助力提升越南语法律人工智能的精准度,也对跨语言法律知识处理与教育技术应用产生了深远影响。
以上内容由遇见数据集搜集并总结生成


