devcenter-articles-embedded
收藏MongoDB Developer Center Articles Embedded Dataset
概述
该数据集包含从MongoDB开发者中心选取的文章子集的块化和嵌入版本。
数据集结构
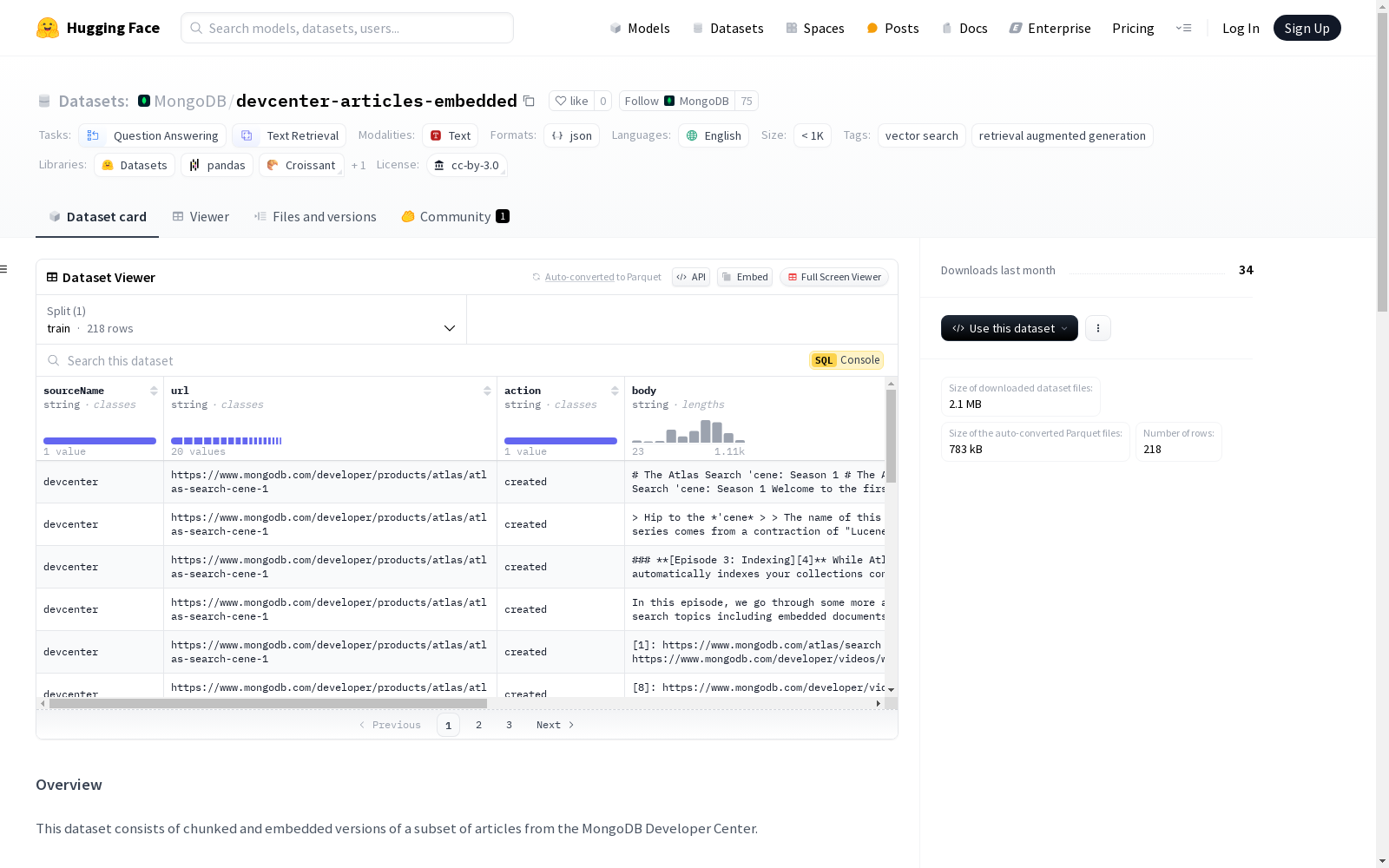
数据集包含以下字段:
- sourceName: 文章来源,整个数据集的值为
devcenter。 - url: 文章链接。
- action: 对文章采取的操作,整个数据集的值为
created。 - body: 以Markdown格式表示的块内容。
- format: 内容格式,所有文章的值为
md。 - metadata: 与文章相关的元数据,如标签、内容类型等。
- title: 文章标题。
- updated: 文章的最后更新日期。
- embedding: 使用Hugging Face的thenlpr/gte-small开源模型创建的块内容嵌入。
用途
该数据集可用于原型化RAG应用程序。这是一个我们用于构建官方文档网站上的AI聊天机器人的真实数据样本。
数据摄取
要使用MongoDB Atlas实验此数据集,首先创建一个MongoDB Atlas账户。
然后可以使用以下脚本将此数据集加载到您的MongoDB Atlas集群中:
python import os from pymongo import MongoClient import datasets from datasets import load_dataset from bson import json_util
uri = os.environ.get(MONGODB_ATLAS_URI) client = MongoClient(uri) db_name = your_database_name # 将此更改为您的实际数据库名称 collection_name = devcenter_articles-embedded
collection = client[db_name][collection_name]
dataset = load_dataset("MongoDB/devcenter-articles-embedded")
insert_data = []
for item in dataset[train]: doc = json_util.loads(json_util.dumps(item)) insert_data.append(doc)
if len(insert_data) == 1000:
collection.insert_many(insert_data)
print("1000 records ingested")
insert_data = []
if len(insert_data) > 0: collection.insert_many(insert_data) insert_data = []
print("Data ingested successfully!")