epstractor-raw
收藏Hugging Face2025-11-17 更新2025-11-18 收录
下载链接:
https://huggingface.co/datasets/public-records-research/epstractor-raw
下载链接
链接失效反馈官方服务:
资源简介:
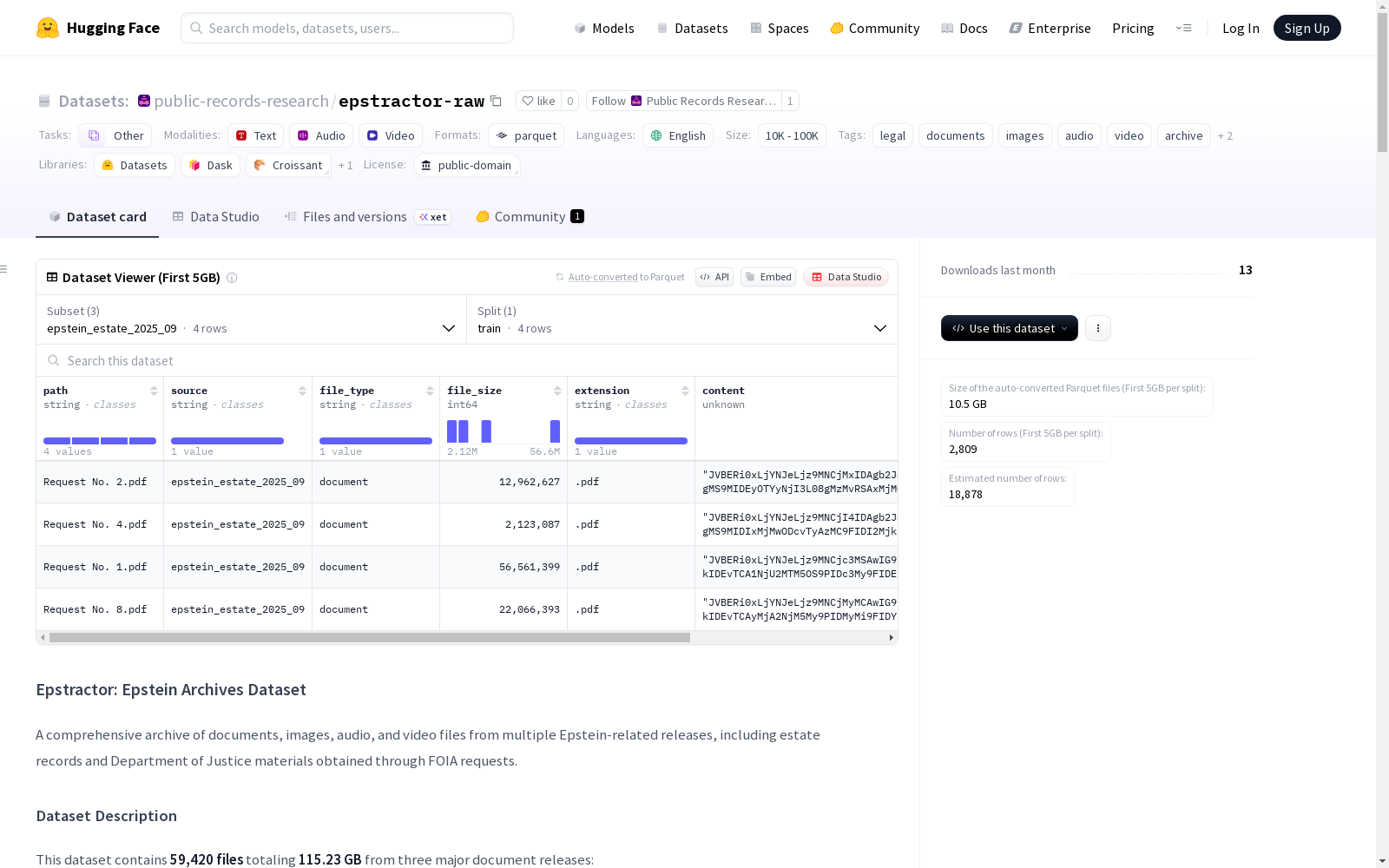
Epstractor: Epstein Archives Dataset 是一个包含与 Epstein 案件相关的文档、图像、音频和视频文件的全面档案,这些文件来源于美国众议院监督和问责委员会以及司法部的官方发布。该数据集以 Parquet 格式组织,并可供公众自由访问。数据集包括来自 Epstein 遗产发布和司法部信息自由请求的材料。
Epstractor: Epstein Archives Dataset is a comprehensive archive containing documents, images, audio, and video files related to the Epstein case, all sourced from official releases of the U.S. House Committee on Oversight and Accountability and the U.S. Department of Justice. This dataset is organized in Parquet format and is freely accessible to the public. It also includes materials from the Epstein estate releases and Freedom of Information Act (FOIA) requests submitted to the Department of Justice.
创建时间:
2025-11-16
原始信息汇总
Epstractor数据集概述
数据集基本信息
- 数据集名称: Epstractor: Epstein Archives Dataset
- 许可证: 公共领域 (public-domain)
- 语言: 英语 (en)
- 数据规模: 10K<n<100K
- 总文件数: 59,420个文件
- 总数据量: 115.23 GB
数据来源与构成
数据来源
- Epstein Estate 2025-09: 5个文件,0.09 GB
- Epstein Estate 2025-11: 26,035个文件,36.56 GB
- House DOJ 2025-09: 33,380个文件,78.58 GB
文件类型分布
- 图像文件: ~56,418个文件 (JPG, TIF格式) - 扫描文档和照片
- 文本文件: ~2,897个TXT文件 - OCR处理和提取的文本
- 音频文件: 56个WAV文件
- 视频文件: 28个MP4/MOV文件
- 文档文件: 14个PDF/XLS/XLSX文件
- 元数据: JSON清单文件
数据结构
配置信息
- epstein_estate_2025_09: 1个分片
- epstein_estate_2025_11: 75个分片
- house_doj_2025_09: 60个分片
数据模式
| 列名 | 类型 | 描述 |
|---|---|---|
| path | string | 源存档中的相对文件路径 |
| source | string | 源数据集名称 |
| file_type | string | 分类类型:图像、文本、音频、视频、文档、其他 |
| file_size | int64 | 文件大小(字节) |
| extension | string | 文件扩展名 |
| content | binary | 原始文件字节(大于2GB的文件为null) |
| content_available | bool | 完整内容是否可用 |
数据来源与合法性
官方发布渠道
- 美国众议院监督与问责委员会通过Google Drive公开发布(2025年9月)
- Epstein Estate公开发布(2025年9月和11月)通过Google Drive
- 司法部FOIA发布(2025年)
数据性质
- 所有材料均来自官方政府来源的公开发布
- 非爬取、泄露或专有内容
- 无访问限制、付费墙或分发限制
技术特性
数据格式
- 存储格式:Parquet格式
- 压缩方式:Snappy压缩
- 最大分片大小:500 MB
- 总分片数:136个
限制说明
- 2个超过2GB的文件仅包含元数据(content字段为null)
- 受PyArrow二进制值限制影响
使用说明
数据加载方式
支持加载全部数据或特定来源数据,可通过data_files模式选择特定配置
文件处理
提供文件内容保存功能,支持按文件类型过滤
法律与伦理考虑
- 许可证: 公共领域(美国政府作品)
- 内容性质: 包含法律文件、个人通信和媒体材料
- 隐私考虑: 材料来自公开发布,用户应审查适用的隐私考虑
- 个别文件: 可能受到额外限制或版权声明约束
维护信息
- 创建日期: 2025-11-16
- 最后更新: 2025-11-16
- 版本: 1.0.0
搜集汇总
数据集介绍
构建方式
在司法档案数字化领域,Epstractor数据集通过系统整合美国政府公开渠道获取的档案资料构建而成。该数据集汇集了爱泼斯坦遗产文件与美国众议院监督委员会公布的司法部材料,涵盖三个独立来源的公开数据。原始文件从无需身份验证的谷歌云端硬盘公开链接获取,经过完整性校验后采用PyArrow工具进行标准化处理。数据处理过程中采用500MB分片策略与Snappy压缩算法,将图像、文本、音视频等异构文件统一转换为Parquet格式,同时提取文件路径、类型、大小等元数据字段。针对超过2GB的大文件则保留元数据信息,确保数据结构的完整性与访问效率。
特点
作为司法档案研究的重要资源,该数据集展现出多模态与大规模并存的显著特征。其囊括59,420个文件共计115.23GB数据量,包含56,418张扫描文档图像、2,897份OCR文本文件以及84个音视频媒体文件。数据按来源划分为三个独立配置,分别对应2025年9月与11月的遗产文件及司法部材料。文件类型覆盖JPG、TIF、TXT、WAV、MP4等十余种格式,并通过二进制字段完整保存文件内容。数据集采用分层存储架构,136个数据分片均配备内容可用性标识,为研究者提供灵活的数据筛选与访问机制。
使用方法
面向司法档案分析应用场景,研究者可通过HuggingFace数据集库实现便捷的数据调用。使用load_dataset函数可加载完整数据集或通过data_files参数指定特定来源,如单独调用爱泼斯坦遗产2025年11月版本。数据访问支持行列级操作,每条记录包含文件路径、来源、类型、大小及二进制内容等字段。对于内容可用的文件,可直接将二进制流写入本地重建原始文件;研究者还可通过filter方法按文件类型筛选目标数据。需要注意的是,两个超过2GB的文件仅提供元数据访问,实际使用时应结合内容可用性标识进行条件处理。
背景与挑战
背景概述
在数字取证与法律档案研究领域,Epstractor数据集于2025年由美国众议院监督问责委员会通过《信息自由法》渠道系统化构建,整合了爱泼斯坦遗产档案与司法部公开材料。该数据集涵盖59,420份多模态文件,包括扫描文档、图像、音视频及OCR文本,总容量达115.23GB,为研究金融犯罪网络与司法透明度提供了首个标准化数据基础。其结构化存储方案与政府公开链路的可溯源性,显著推动了法律文本计算分析与跨媒体证据关联研究的发展。
当前挑战
该数据集需应对法律文档多模态融合的核心难题:图像类文件占比超过94%的扫描文档需解决复杂版式OCR与手写体识别问题,而音视频材料的语义对齐则依赖跨模态检索技术。构建过程中面临原始数据异构性挑战,包括2GB以上大文件因PyArrow限制导致内容缺失,以及文本与多媒体证据的时空关联重建。此外,公共领域数据的合规使用要求与隐私边界的界定,亦构成法律技术交叉研究的关键瓶颈。
常用场景
经典使用场景
在司法档案数字化研究领域,Epstractor数据集作为大规模多模态法律档案的典型范例,主要应用于证据链重构与司法文本分析。其包含的扫描文档、OCR文本及多媒体材料为法律实证研究提供了结构化数据基础,研究者可通过跨媒体关联分析追溯案件脉络,同时支撑司法透明度评估与历史档案保护等学术实践。
解决学术问题
该数据集有效解决了司法档案碎片化导致的实证研究困境,通过系统整合文字、图像与音视频材料,为犯罪学中的证据关联性研究、司法信息公开制度评估提供了标准化数据支撑。其多模态特性尤其推动了数字取证技术的方法论创新,使研究者能够基于真实案例验证跨媒体证据融合模型的可靠性。
衍生相关工作
基于该数据集衍生的经典研究包括多模态司法文档智能检索系统、基于注意力机制的证据关联模型,以及面向大规模档案数据的分布式处理框架。这些工作显著提升了司法档案的机器可读性,并为后续《数字司法档案元数据标准》的制定提供了实证基础。
以上内容由遇见数据集搜集并总结生成


