cold-chain-strawberry-sensors
收藏Hugging Face2025-12-02 更新2025-12-03 收录
下载链接:
https://huggingface.co/datasets/NifferLi/cold-chain-strawberry-sensors
下载链接
链接失效反馈官方服务:
资源简介:
冷链草莓多传感器数据集(运输S3)包含9个传感器在冷藏卡车运输新鲜草莓过程中每10分钟的温度测量数据,以及基于1小时滑动窗口计算的窗口级风险标签。
Multi-sensor Dataset for Cold Chain Strawberries (Transportation S3) contains temperature measurement data collected every 10 minutes by 9 sensors during the transportation of fresh strawberries in a refrigerated truck, as well as window-level risk labels calculated based on a 1-hour sliding window.
创建时间:
2025-11-30
原始信息汇总
Cold-chain Strawberry Multi-sensor Dataset (Shipment S3) 数据集概述
数据集基本信息
- 数据集名称: Cold-chain Strawberry Multi-sensor Dataset (Shipment S3)
- 发布者: NifferLi
- 许可证: CC BY 4.0
- 数据集地址: https://huggingface.co/datasets/NifferLi/cold-chain-strawberry-sensors
- 数据格式: CSV
- 主要文件:
S3_aligned_strict_linear_with_labels.csv
数据集内容与结构
数据来源与背景
- 数据来源于一辆运输新鲜草莓的冷藏卡车内部部署的9个传感器。
- 数据以10分钟分辨率记录温度测量值。
- 数据集是以人为中心的冷链监测研究项目的一部分,结合了多传感器数据、基于规则的可解释风险评估以及用于解释的(小型)语言模型。
数据组织与划分
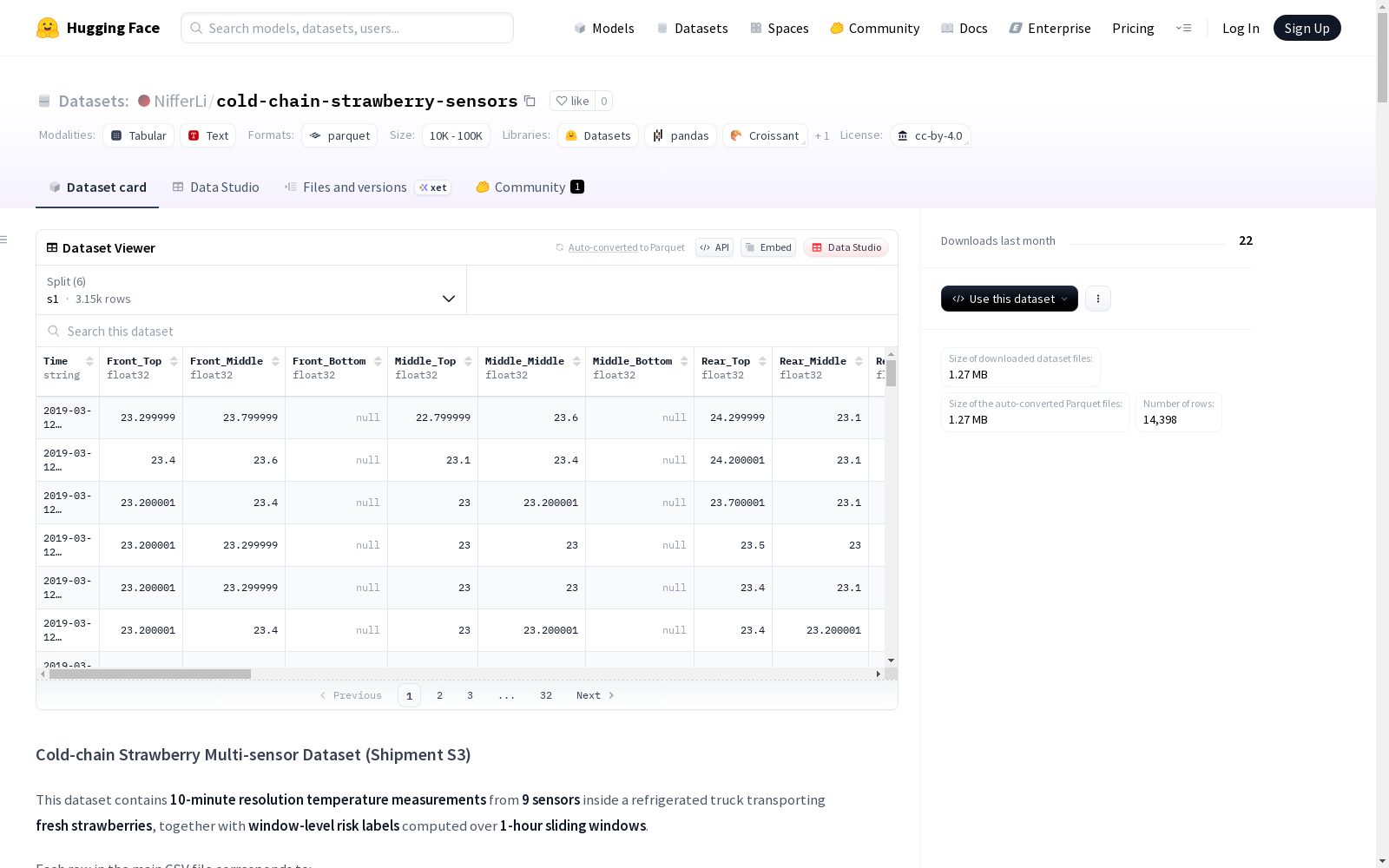
数据集包含6个数据划分(split),对应不同的货件(shipment):
- s1: 3,146 个样本,1,976,125 字节
- s2: 2,616 个样本,1,705,409 字节
- s3: 2,162 个样本,1,385,250 字节
- s4: 2,162 个样本,1,401,590 字节
- s5: 2,039 个样本,1,287,451 字节
- s6: 2,273 个样本,1,474,723 字节
- 总下载大小: 1,270,272 字节
- 总数据集大小: 9,230,548 字节
数据表示
- 主CSV文件中的每一行对应一个10分钟的时间步(原始传感器读数)。
- 同时,每一行也包含了基于前1小时滑动窗口(即当前行加上前5行,共6个时间步)计算得到的风险标签和特征。
- 对于索引
i ≥ 5的每一行,其关联的窗口由时间步i-5, i-4, ..., i-1, i组成(6步 × 10分钟 = 60分钟)。
数据字段详解
1. 时间与元信息
Time: 10分钟时间步的时间戳(ISO格式时间)。这是重采样到10分钟间隔后的网格时间。window_id: 以该行结束的1小时滑动窗口的整数ID(从0开始)。第一个完整窗口的window_id = 0。第一个完整窗口之前的行(即前5行)为NaN。window_start_time: 1小时窗口的开始时间。等于6步窗口中第一个时间步的Time。window_end_time: 1小时窗口的结束时间,定义为最后一步的Time加上10分钟。因此每个窗口覆盖一个严格的60分钟区间[window_start_time, window_end_time)。shipment_id: 货件/路线的标识符。对于此文件,始终为"S3"。
2. 原始传感器读数(10分钟分辨率)
传感器布置为3个纵向位置 × 3个垂直高度:
- 位置: 前部(Front)、中部(Middle)、后部(Rear)
- 高度: 顶部(Top)、中部(Middle)、底部(Bottom)
- 对应字段:
Front_Top,Front_Middle,Front_Bottom,Middle_Top,Middle_Middle,Middle_Bottom,Rear_Top,Rear_Middle,Rear_Bottom - 单位: °C(从原始°F转换而来)。
- 缺失测量值(例如传感器离线、间隔>30分钟)表示为
NaN。
3. 窗口级覆盖特征(1小时窗口,6个时间步)
基于以当前行结束的1小时窗口(6个连续的10分钟步)计算:
N_valid: 1小时窗口内非缺失传感器读数的数量(最大值 = 54 = 9个传感器 × 6个时间步)。coverage_points: 点级覆盖率:N_valid / 54。范围在 [0, 1]。N_active_t: 在6个时间步中,至少有一个传感器具有有效读数的时间步数量。coverage_time: 时间级覆盖率:N_active_t / 6。范围在 [0, 1]。
4. 窗口级温度统计量
基于1小时窗口内所有非缺失温度值计算:
T_max_window: 窗口中观察到的最高温度(°C)。T_min_window: 窗口中观察到的最低温度(°C)。T_mean: 窗口内的平均温度(°C)。T_std: 窗口内温度的标准差。
5. 窗口级暴露持续时间
这些特征近似估计了超出草莓推荐温度范围(通常在0–4°C左右,冰点接近-1.1°C)的暴露持续时间。 对于窗口中的每个时间步(6步 × 10分钟):
- 令
T_max_t= 该步中9个传感器的最高温度。 - 令
T_min_t= 该步中9个传感器的最低温度。 - 每个步对应10分钟的暴露时间。
- 对应字段:
dur_gt4: 窗口中T_max_t > 4.0°C且至少有一个传感器处于活动状态的总分钟数。每个符合条件的步贡献10分钟。dur_lt0: 窗口中T_min_t < 0.0°C且至少有一个传感器处于活动状态的总分钟数。dur_lt_minus1: 窗口中T_min_t < -1.0°C且至少有一个传感器处于活动状态的总分钟数(近似冻结风险)。has_over10: 指示器(0/1),表示窗口中是否存在T_max_window > 10.0°C(极端高温事件)。
6. 风险标签
数据集为每个1小时窗口提供了可解释的、基于规则的风险标签。
6.1 主要风险等级 (risk_level)
risk_level 是 {0, 1, 2} 中的整数:
0(R0 – 正常):T_max_window <= 4.0°C且T_min_window >= 0.0°C。解释为草莓冷链控制在0–4°C内的理想状态。2(R2 – 严重风险): 如果窗口满足以下任何条件,则标记为严重风险:T_max_window > 10.0°C(极端高温),或dur_gt4 >= 30分钟(≥ 3 × 10分钟步高于4.0°C),或T_min_window < -1.0°C(低于草莓近似冰点),或dur_lt0 >= 30分钟(≥ 3 × 10分钟步低于0.0°C)。
1(R1 – 轻度风险): 所有既不是R0也不是R2的剩余情况(与0–4°C存在一些偏差,但严重程度不足以归类为R2)。
6.2 置信度等级 (conf_level)
conf_level 是 {0, 1, 2} 中的整数,基于数据覆盖率计算:
令 coverage_points = N_valid / 54,coverage_time = N_active_t / 6,conf_score = (coverage_points + coverage_time) / 2。
则:
conf_level = 2(高置信度),如果conf_score >= 0.8conf_level = 1(中置信度),如果0.5 <= conf_score < 0.8conf_level = 0(低置信度),如果conf_score < 0.5或覆盖率非常稀疏。
6.3 独热编码标签
为方便起见,包含了独热编码标签:
label_R0: 如果risk_level == 0则为1,否则为0。label_R1: 如果risk_level == 1则为1,否则为0。label_R2: 如果risk_level == 2则为1,否则为0。
7. 风险原因指标
为帮助解释为何一个窗口被标记为R2(严重),提供了几个二元原因指标:
cause_high_peak: 如果T_max_window > 10.0°C则为1,否则为0。cause_high_duration: 如果dur_gt4 >= 30分钟则为1,否则为0。cause_low_peak: 如果T_min_window < -1.0°C则为1,否则为0。cause_low_duration: 如果dur_lt0 >= 30分钟则为1,否则为0。
8. 其他字段
summary_text: 字符串类型。
数据预处理摘要
- 原始温度读数以°F记录,并转换为°C。
- 不规则时间戳通过基于时间的线性插值对齐到规则的10分钟网格。
- 原始测量值之间超过30分钟的间隔未进行插值,在网格中保持为
NaN。 - 对于每个索引
i ≥ 5的行,定义了一个覆盖时间步i-5, ..., i的1小时滑动窗口。 - 所有窗口级特征和标签(
T_max_window,dur_gt4,risk_level等)均基于这些1小时窗口计算。
潜在应用任务
- 窗口级风险分类: 根据1小时多传感器数据(原始时间序列或窗口特征)预测
risk_level。 - 置信度估计: 根据覆盖率和传感器模式预测
conf_level。 - 时间序列异常检测: 检测具有R2风险或特定
cause_*模式的片段。 - 以人为中心的解释: 使用
risk_level、conf_level和cause_*作为结构化输入,通过(小型)语言模型为驾驶员、冷库操作员或质量经理生成自然语言解释和操作建议。
局限性与说明
- 此初始版本仅包含单个货件(S3);更多货件(S2, S4–S6)可能在未来的扩展中添加。
- 风险标记方案是基于规则的,来源于已发布的草莓温度建议和工程判断,可能未涵盖所有商业或区域冷链标准。
- 传感器布置特定于安装了仪器的车辆(3个纵向位置 × 3个高度)。
搜集汇总
数据集介绍
构建方式
在冷链物流监测领域,精准的温度数据是评估生鲜产品品质的关键。本数据集通过部署九个传感器于冷藏卡车内部,以十分钟为间隔采集草莓运输过程中的温度读数。原始数据经过时间对齐与线性插值处理,确保时间序列的规整性;随后采用一小时滑动窗口机制,将连续六个时间步的温度数据聚合为分析单元,并基于预设规则计算窗口级别的风险标签与统计特征,从而构建出兼具时序粒度与风险语义的结构化数据集。
特点
本数据集的核心特点在于其多维度的信息集成与精细化的风险标注。数据不仅包含九个空间分布传感器的高分辨率温度序列,还衍生出覆盖度、统计指标及暴露时长等窗口级特征。风险标签体系融合了温度阈值与持续时间规则,将每个窗口划分为正常、轻度风险与严重风险三个等级,并辅以置信度评估与风险成因标识。这种设计使得数据集既能支持传统的时序分析,也为可解释的风险评估与决策支持研究提供了丰富的基础。
使用方法
该数据集适用于多种冷链监控与机器学习任务。研究者可直接加载CSV文件或通过Hugging Face Datasets库获取数据,用于窗口级别的风险分类模型训练,预测风险等级或置信度。时间序列异常检测任务可利用原始温度序列或窗口特征识别风险时段。此外,结构化的风险标签、成因标识及文本摘要字段,为结合小型语言模型生成自然语言解释、实现人机协同的冷链管理决策提供了理想的数据基础。
背景与挑战
背景概述
在农产品冷链物流领域,温度监控是保障生鲜果蔬品质与安全的核心环节。Cold-chain Strawberry Multi-sensor Dataset 由研究人员于2025年前后创建,作为一项聚焦于“以人为本的冷链监控”研究项目的重要组成部分。该数据集旨在通过部署于冷藏货车内的九路传感器,以十分钟分辨率采集草莓运输过程中的多维温度时序数据,并结合基于规则的、可解释的一小时滑动窗口风险标注,系统性地量化运输过程中的温度异常风险。其核心研究问题在于如何将多传感器时序数据转化为具有可操作性的风险洞察,从而提升冷链物流的透明性与决策智能化水平,对智慧农业与食品供应链管理领域具有显著的示范价值。
当前挑战
该数据集致力于解决冷链运输中草莓品质保障的时序风险分类与异常检测问题,其核心挑战在于如何从高维、可能包含缺失值的传感器时序数据中,精准识别并解释复杂的温度偏离模式,例如短暂高温峰值与长时间低温暴露对果实品质的差异化影响。在数据集构建过程中,挑战主要源于实际物流场景的复杂性:原始传感器数据存在时间戳不规则与测量间隙,需通过严格的时间对齐与插值处理以生成规整的时序网格;同时,为生成可靠的窗口级风险标签,必须设计一套既符合草莓生理特性(如0-4°C的理想存储范围与-1.1°C左右的冻结点)又具备工程可解释性的规则体系,并在数据覆盖度不足时妥善处理标签置信度评估问题。
常用场景
经典使用场景
在冷链物流与农产品质量安全领域,该数据集为基于多传感器时间序列的风险评估提供了标准化的研究平台。其经典使用场景聚焦于以一小时滑动窗口为单位,对草莓运输过程中的温度异常进行风险等级分类。研究人员利用九个传感器在十分钟分辨率下采集的温度数据,结合预计算的窗口级统计特征(如最高温度、暴露时长等),构建机器学习模型以自动识别正常、轻度风险与严重风险三种状态,从而实现对冷链运输环境的实时监控与预警。
解决学术问题
该数据集有效解决了冷链监测中多传感器数据融合与可解释风险建模的关键学术问题。通过提供规则定义的风险标签与置信度等级,它支持研究者探索如何从高维、可能缺失的时空温度数据中提取稳健特征,并建立透明、可信的风险评估模型。其意义在于推动了冷链物流从传统阈值报警向精细化、预测性管理的范式转变,为保障生鲜农产品品质、减少损耗提供了数据驱动的决策依据,对智慧农业与食品供应链研究产生了积极影响。
衍生相关工作
围绕该数据集,已衍生出若干经典研究方向。例如,结合时间序列分类与异常检测算法,对风险等级进行端到端预测;利用其结构化的风险成因标签(如高温峰值、低温持续时间),发展可解释人工智能方法,为风险事件提供归因分析;此外,也有工作探索将多传感器数据与小型语言模型结合,自动生成面向操作人员的自然语言报告与决策建议,推动了人本计算在工业物联网中的融合应用。
以上内容由遇见数据集搜集并总结生成


