OpenMind
收藏Hugging Face2025-03-21 更新2025-03-22 收录
下载链接:
https://huggingface.co/datasets/AnonRes/OpenMind
下载链接
链接失效反馈官方服务:
资源简介:
OpenMind数据集是一个大规模的头颈3D MRI图像数据集,包含114k个MRI图像。该数据集旨在提供大量三维医学成像数据,以加速用于三维医学成像的自监督学习方法的发展。数据来源于OpenNeuro平台的800个数据集,包含来自30多台不同扫描仪的23种不同的MRI模态/技术,是一个高度多样化的预训练数据集。此外,数据集还提供了分层元数据、匿名化掩码和解剖学掩码,以及按照修改后的BIDS格式组织的结构化数据。
The OpenMind dataset is a large-scale 3D head-and-neck MRI image dataset containing 114k MRI images. It is designed to provide abundant 3D medical imaging data to accelerate the development of self-supervised learning methods for 3D medical imaging. The data is sourced from 800 datasets hosted on the OpenNeuro platform, covering 23 distinct MRI modalities and techniques from more than 30 different scanners, rendering it a highly diverse pre-training dataset. Furthermore, the dataset provides hierarchical metadata, anonymization masks, anatomical masks, as well as structured data organized in the modified BIDS format.
创建时间:
2025-03-11
搜集汇总
数据集介绍
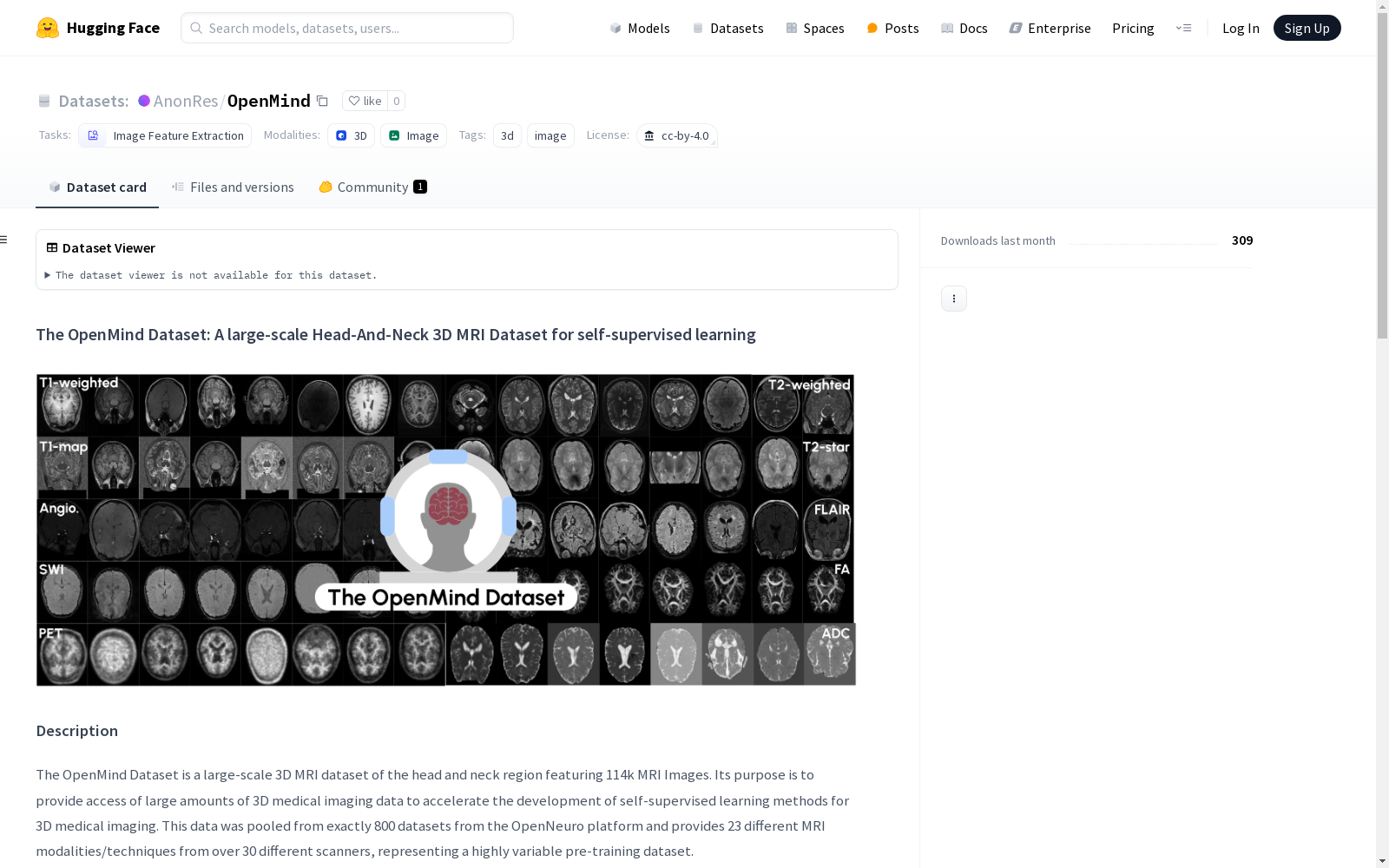
构建方式
OpenMind数据集是一个大规模的头颈部3D MRI数据集,包含了114,000张MRI图像。该数据集通过整合来自OpenNeuro平台的800个数据集构建而成,涵盖了23种不同的MRI模态和技术,涉及超过30种不同的扫描仪。数据集的构建遵循了修改后的BIDS格式,每个数据集存储在单独的文件夹中,文件夹内包含相应的受试者、会话以及每个会话的MRI图像、匿名化掩码和解剖学掩码。
特点
OpenMind数据集的特点在于其多样性和丰富性。数据集不仅提供了大量的3D MRI图像,还包含了分层的元数据,这些元数据以统一的格式呈现。此外,数据集还提供了匿名化掩码和解剖学掩码,前者用于标记去面部区域,后者用于标记解剖区域,这些掩码在开发基于重建的预训练方法时非常有用。数据集的高度可变性使其成为3D医学影像自监督学习方法的理想选择。
使用方法
OpenMind数据集的使用方法主要围绕自监督学习展开。研究人员可以利用数据集中的3D MRI图像进行预训练,开发新的图像特征提取方法。数据集提供的匿名化掩码和解剖学掩码可以帮助研究人员在重建过程中忽略特定区域,或在对比学习方法中避免采样到空区域。此外,数据集的结构化元数据文件(metadata.csv)为研究人员提供了丰富的上下文信息,便于进行更深入的分析和模型优化。
背景与挑战
背景概述
OpenMind数据集是一个大规模的头颈部3D MRI数据集,包含114,000张MRI图像,旨在为3D医学影像的自监督学习方法提供丰富的数据支持。该数据集由OpenNeuro平台上的800个数据集整合而成,涵盖了23种不同的MRI模态和技术,涉及超过30种不同的扫描仪,具有高度的数据多样性。OpenMind数据集的创建旨在加速3D医学影像领域的研究,特别是在自监督学习方法的开发方面。通过提供匿名化掩码和解剖学掩码,该数据集为重建和对比学习方法的开发提供了重要支持。其结构遵循修改后的BIDS格式,便于研究人员快速访问和使用。
当前挑战
OpenMind数据集在解决3D医学影像自监督学习问题时面临多重挑战。首先,数据的高度多样性虽然为模型训练提供了丰富的样本,但也带来了数据分布不一致的问题,可能导致模型泛化能力下降。其次,尽管数据集提供了丰富的元数据,但部分关键信息(如体重、BMI、种族等)的缺失率较高,限制了某些特定研究方向的应用。此外,数据集的构建过程中,如何有效整合来自不同来源的数据并确保其格式统一,也是一个技术难点。最后,匿名化和解剖学掩码的生成与处理需要精确的算法支持,以确保数据的隐私保护和模型训练的有效性。
常用场景
经典使用场景
OpenMind数据集在医学影像领域中被广泛应用于自监督学习算法的开发与验证。该数据集包含了114k个头颈部的3D MRI图像,涵盖了23种不同的MRI模态和技术,来自30多种不同的扫描仪。这种多样性和规模使得OpenMind成为训练和测试3D医学影像处理模型的理想选择,尤其是在缺乏大量标注数据的情况下,自监督学习方法能够通过该数据集进行有效的预训练。
解决学术问题
OpenMind数据集解决了医学影像领域中自监督学习算法开发中的数据稀缺问题。传统的监督学习方法依赖于大量标注数据,而医学影像的标注成本高昂且耗时。通过提供大规模的未标注3D MRI数据,OpenMind使得研究人员能够开发出更高效的自监督学习模型,从而在图像分割、重建和分类等任务中取得更好的性能。此外,数据集中的匿名化和解剖学掩码进一步支持了重建和对比学习方法的开发。
衍生相关工作
OpenMind数据集的出现催生了一系列经典的研究工作,尤其是在3D医学影像的自监督学习领域。许多研究团队利用该数据集开发了新的预训练模型,如基于对比学习的3D卷积神经网络和生成对抗网络。这些模型在图像分割、病变检测和影像重建等任务中表现出色,推动了医学影像分析技术的进步。此外,OpenMind还为跨模态医学影像分析提供了新的研究方向,促进了多模态数据融合算法的发展。
以上内容由遇见数据集搜集并总结生成


