PersianSciQA-Extractive
收藏Hugging Face2025-08-28 更新2025-08-29 收录
下载链接:
https://huggingface.co/datasets/safora/PersianSciQA-Extractive
下载链接
链接失效反馈官方服务:
资源简介:
PersianSciQA-Extractive数据集是一个大规模资源,包含超过10,000个波斯语问题-答案对,专为科学领域的提取式问题回答任务而设计。该数据集基于safora/PersianSciQA数据集构建,并使用Gemini 2.5 Pro模型生成答案。数据集分为训练集、验证集和测试集。
PersianSciQA-Extractive is a large-scale resource containing over 10,000 Persian question-answer pairs, specifically designed for extractive question answering tasks in the scientific domain. This dataset is constructed based on the safora/PersianSciQA dataset, with its answers generated using the Gemini 2.5 Pro model. The dataset is split into training, validation, and test sets.
创建时间:
2025-08-28
原始信息汇总
PersianSciQA-Extractive 数据集概述
数据集简介
PersianSciQA-Extractive 是一个大规模波斯语问答数据集,包含超过10,000个问答对,专门用于科学领域的抽取式问答任务。
基本属性
- 许可证:CC BY-SA 4.0
- 语言:波斯语 (fa)
- 任务类型:抽取式问答、科学文本处理
数据来源
基于 safora/PersianSciQA 原始数据集构建,仅选择相关性评分最高(3分)的样本。
答案生成方法
使用 Gemini 2.5 Pro 模型通过程序化方式生成答案,模型被要求仅基于提供的上下文回答问题,若上下文无相关信息则输出 "CANNOT_ANSWER"。
数据集结构
数据格式
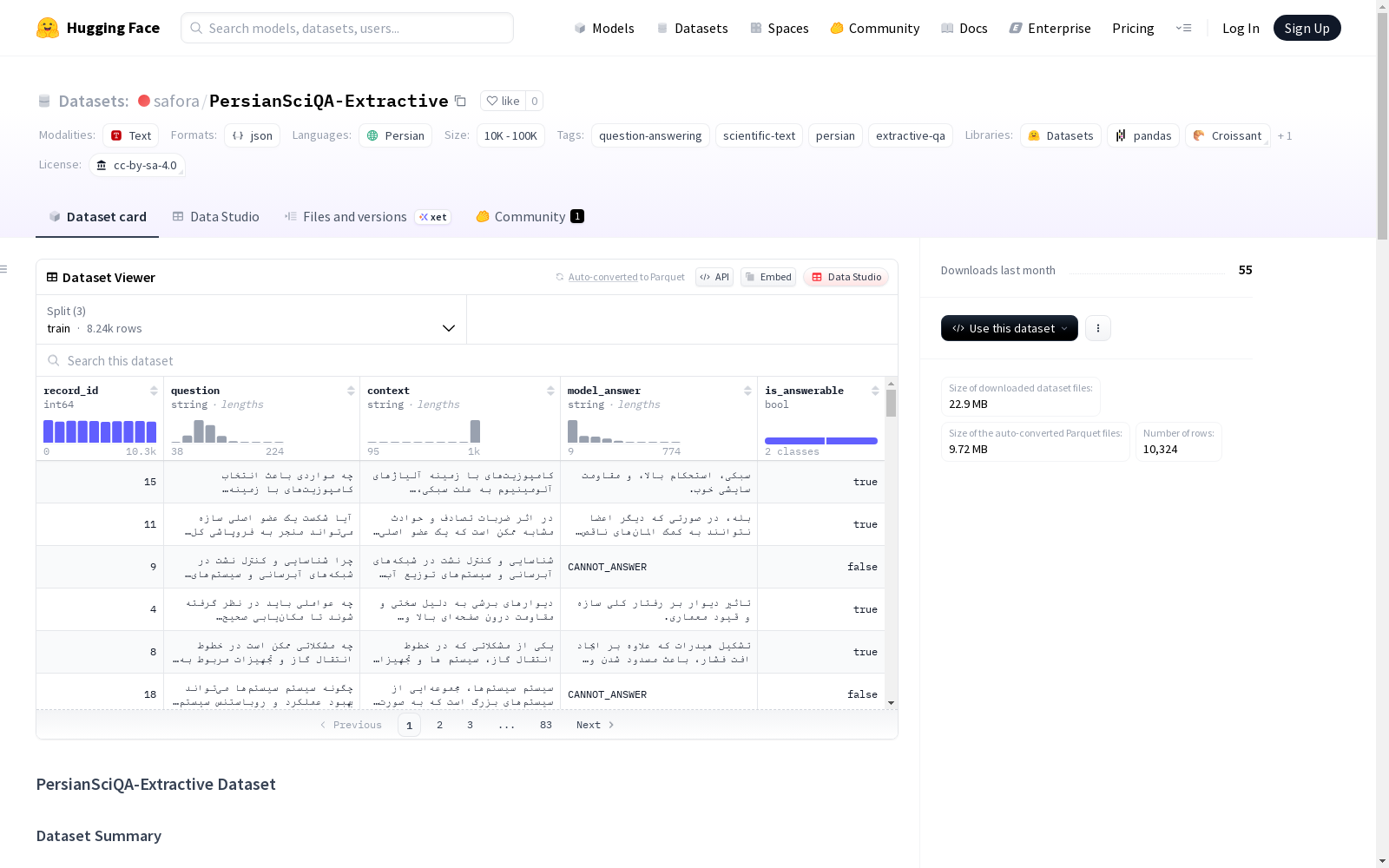
每个样本为 JSON 对象,包含以下字段:
record_id:唯一标识符(整数)question:波斯语问题(字符串)context:波斯语科学摘要(字符串)model_answer:AI生成的答案或 "CANNOT_ANSWER"(字符串)is_answerable:是否可回答的标志(布尔值)
数据划分
采用基于源摘要的分组划分方法:
- 训练集:80% 的记录
- 验证集:10% 的记录
- 测试集:10% 的记录
引用信息
如需使用本数据集,请引用原始论文和本仓库:
@misc{safora2025persiansciqa_extractive, author = {Aghadavoud Jolfaei, Safoura}, title = {PersianSciQA-Extractive}, year = {2025}, publisher = {Hugging Face}, journal = {Hugging Face repository}, howpublished = {https://huggingface.co/datasets/safora/PersianSciQA-Extractive}, }
搜集汇总
数据集介绍
构建方式
在科学文献处理领域,波斯语资源相对稀缺,PersianSciQA-Extractive数据集的构建采用了严谨的多阶段流程。该数据集基于safora/PersianSciQA源数据集,首先筛选出相关性评分最高的样本确保数据质量。随后采用Gemini 2.5 Pro大语言模型进行程序化答案生成,通过特定提示模板严格控制模型仅基于给定科学摘要生成抽取式答案,当上下文缺乏相关信息时输出特定标识符。最后采用基于原文摘要的分组分割方法,将数据划分为训练集、验证集和测试集,确保同一摘要的所有问题被完整保留在同一数据子集中。
特点
该数据集最显著的特征在于其专业领域针对性和语言独特性,作为波斯语科学文本问答领域的大规模资源,包含超过10,000个高质量问答对。每个样本均包含波斯语问题、科学摘要上下文以及模型生成的精确答案,特别设置了布尔型可回答标志和无法回答的特定标签。数据集采用分组分割策略保持了原文单元的完整性,避免了同一摘要内容在不同数据子集间泄露,从而提升了模型评估的可靠性。其科学文本特性为自然语言处理模型提供了专业领域的测试平台。
使用方法
研究人员可通过Hugging Face数据集库直接加载该数据集,其标准化的JSONL格式确保了易用性。每个数据样本包含唯一标识符、波斯语问题、科学摘要上下文、模型生成答案及可回答标志。数据集已预先分割为训练集、验证集和测试集,适用于端到端的抽取式问答模型训练与评估。在使用过程中,建议特别注意波斯语文本的特殊处理要求,并充分利用分组分割特性进行交叉验证。该数据集主要用于科学领域问答系统的性能评测,也可用于跨语言自然语言处理研究的对比分析。
背景与挑战
背景概述
波斯语科学问答抽取式数据集(PersianSciQA-Extractive)由Safoura Aghadavoud Jolfaei于2025年构建,旨在填补波斯语科学文本处理领域的资源空白。该数据集基于safora/persian-scientific-qa原始数据集扩展而成,专门针对科学领域的抽取式问答任务设计,包含超过10,000个高质量问答对。其构建背景源于全球自然语言处理研究中对低资源语言科学文本理解能力的迫切需求,通过系统化整理波斯语科学文献摘要与对应问题,为跨语言科学知识检索与智能问答系统提供了关键数据支撑。
当前挑战
该数据集核心挑战在于解决波斯语科学文本的复杂语言现象与专业术语理解问题,包括科学概念的多义性解析、长距离语义依赖捕捉以及低资源语言模型对学术文本的适应性。构建过程中面临双重挑战:一是需要确保生成答案的准确性与科学性,通过严格筛选高相关性样本并采用Gemini 2.5 Pro模型生成可靠答案;二是维护数据分割的严谨性,采用基于原文摘要的组级分割方法防止数据泄露,同时处理模型在遇到无解问题时精确输出CANNOT_ANSWER标签的稳定性问题。
常用场景
经典使用场景
在波斯语自然语言处理研究中,该数据集被广泛用于训练和评估抽取式问答模型。研究者通过构建基于科学文献摘要的问答对,能够有效测试模型在特定领域文本中定位精确答案的能力。这种设置特别适合评估模型对波斯语科学术语和复杂句法的理解水平,为跨语言科学知识检索提供了标准化的评估基准。
衍生相关工作
基于该数据集衍生的经典工作包括跨语言科学问答模型的对比研究,以及多模态科学文献理解系统的开发。研究者通过迁移学习技术,将在此数据集上训练的模型适配到其他低资源科学领域,推动了小语种科学文本处理技术的发展。这些工作为构建更包容的多语言学术生态系统奠定了重要基础。
数据集最近研究
最新研究方向
波斯语科学文本问答领域正迎来跨语言预训练模型的技术革新,PersianSciQA-Extractive作为首个大规模波斯语科学领域抽取式问答数据集,为低资源语言的自然语言处理研究提供了关键支撑。该数据集通过基于抽象级别的分组分割策略,有效避免了数据泄露问题,推动了跨语言科学文献理解模型的发展。当前研究热点集中于多语言大模型在波斯语科学QA任务中的零样本迁移性能优化,以及结合检索增强生成技术提升模型对专业知识的捕捉能力。这一数据资源的建立不仅填补了波斯语科学问答评估体系的空白,更为中东地区人工智能技术的本土化应用提供了重要基础设施。
以上内容由遇见数据集搜集并总结生成


