sileod/movie_recommendation
收藏Hugging Face2023-05-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sileod/movie_recommendation
下载链接
链接失效反馈官方服务:
资源简介:
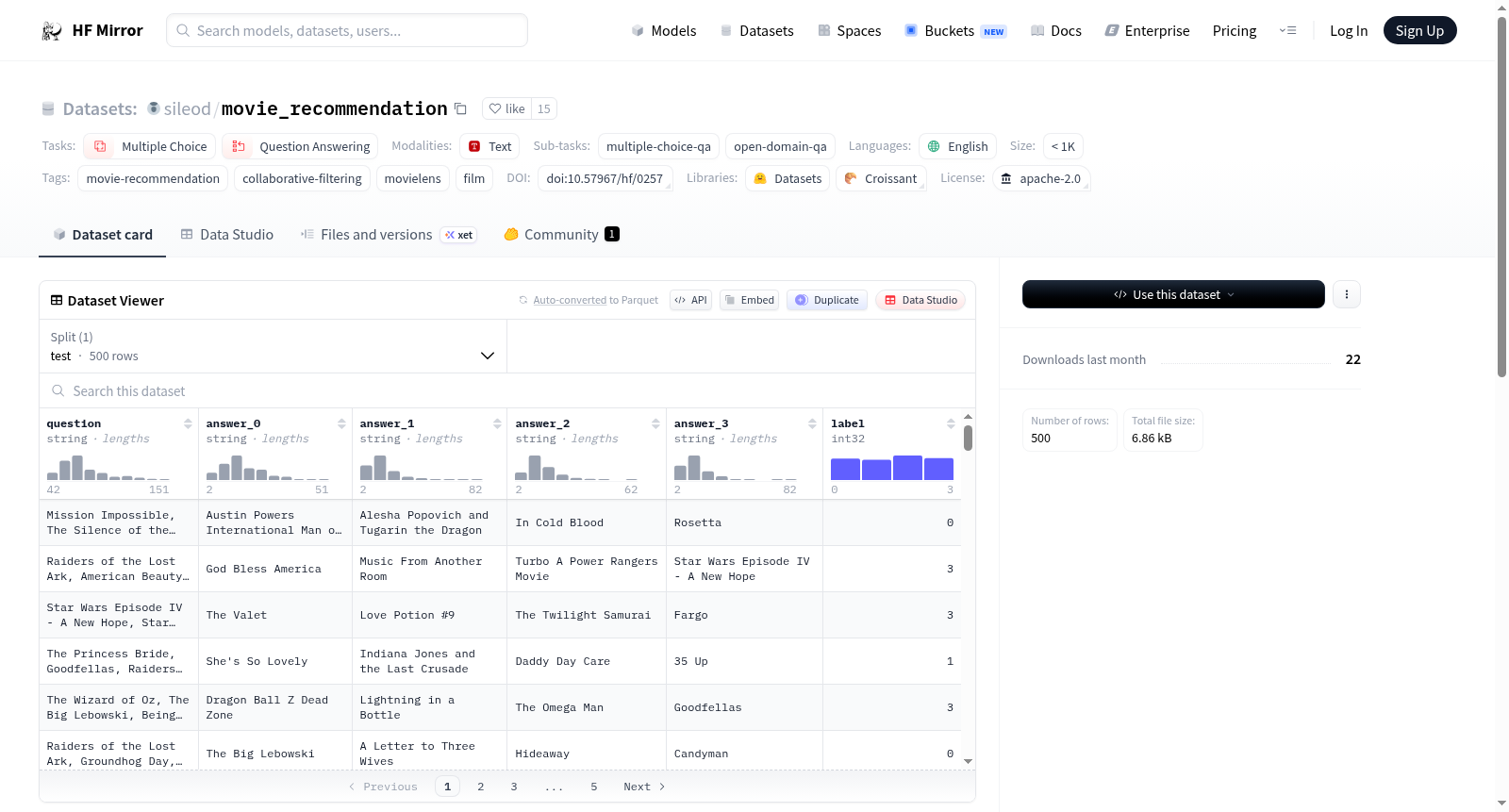
该数据集用于评估(零样本)推荐与语言模型的性能,展示了预训练的大型语言模型可以作为推荐系统,并与矩阵分解基线进行比较。这是基于语言的电影推荐数据集的BIG-Bench版本。GPT-2在该数据集上的准确率为48.8%,随机猜测的准确率为25%,而人类的准确率为60.4%。
This dataset is intended to evaluate the performance of zero-shot recommendation systems and large language models (LLMs), demonstrating that pretrained large language models can serve as recommendation systems, with comparisons made against matrix factorization baselines. This is the BIG-Bench variant of the language-based movie recommendation dataset. GPT-2 achieves an accuracy of 48.8% on this dataset, with random guessing achieving 25% accuracy and human performance reaching 60.4%.
提供机构:
sileod
原始信息汇总
数据集概述
基本信息
- 名称: movie_recommendation
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 多语言性: 单语种 (monolingual)
- 数据集大小: 小于1千条记录 (n<1K)
- 数据来源: 原始数据 (original)
创建者信息
- 标注创建者: 专家生成 (expert-generated)
- 语言创建者: 众包 (crowdsourced)
任务类型
- 任务类别: 多选题 (multiple-choice), 问答 (question-answering)
- 任务ID: 多选题问答 (multiple-choice-qa), 开放领域问答 (open-domain-qa)
标签
- 标签: 电影推荐 (movie-recommendation), 协同过滤 (collaborative-filtering), Movielens, 电影 (film)
数据集用途
- 用于评估基于语言模型的零样本推荐系统,比较少量样本学习结果与矩阵分解基线。
搜集汇总
数据集介绍
背景与挑战
背景概述
sileod/movie_recommendation是一个用于评估语言模型在零样本电影推荐任务中表现的数据集,包含500个多选问题,旨在比较GPT-2等模型与人类推荐准确率的差异。数据集基于BIG-Bench任务,支持多选问答和开放域问答任务。
以上内容由遇见数据集搜集并总结生成


