BBBP-V-Train
收藏Hugging Face2025-10-22 更新2025-10-22 收录
下载链接:
https://huggingface.co/datasets/molvision/BBBP-V-Train
下载链接
链接失效反馈官方服务:
资源简介:
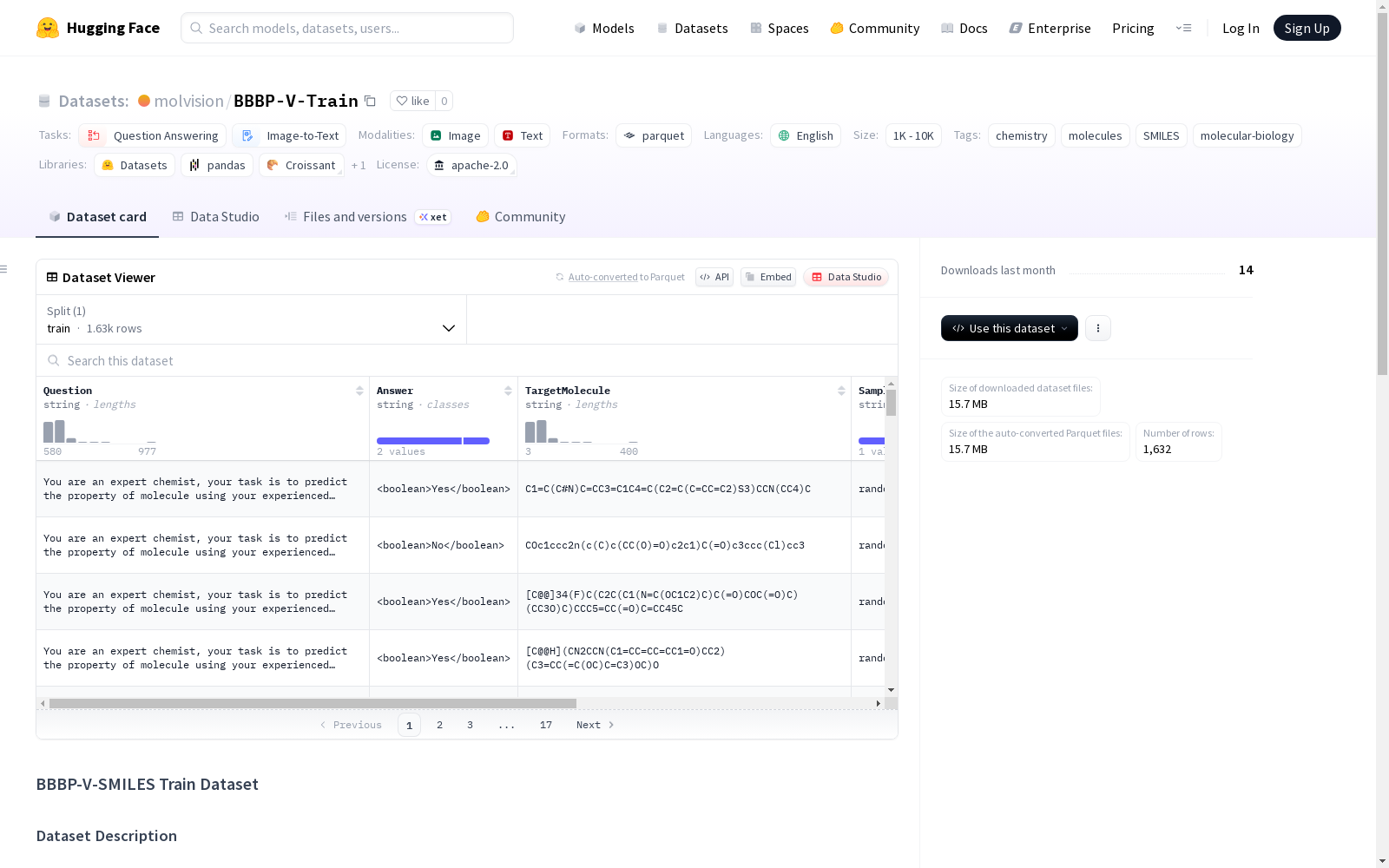
BBBP-V-SMILES训练数据集包含与BBBP相关化合物的分子数据和视觉表示。数据集中的特征包括与分子相关的问题和答案、目标分子的SMILES表示、采样方法、样本编号、样本重复次数以及由SMILES生成的分子结构图像。数据集共有1632个样本,图像格式为PIL Image(RGB),大小为300x300像素。
The BBBP-V-SMILES training dataset encompasses molecular data and visual representations of compounds associated with BBBP. The features included in the dataset are molecular-related questions and answers, SMILES representations of target molecules, sampling methods, sample indices, sample repetition counts, and molecular structure images generated from SMILES strings. The dataset contains a total of 1632 samples, with the images in PIL Image (RGB) format and sized at 300×300 pixels.
创建时间:
2025-10-21
原始信息汇总
BBBP-V-SMILES Train Dataset 概述
数据集基本信息
- 许可证: Apache-2.0
- 任务类别: 问答、图像到文本
- 语言: 英语
- 领域标签: 化学、分子、SMILES、分子生物学
- 规模分类: 1K<n<10K
数据集描述
该数据集包含与BBBP相关化合物的分子数据和视觉表示。
数据特征
- 问题: 与分子相关的问题
- 答案: 对应的答案
- 目标分子: 目标分子的SMILES表示
- 采样方法: 使用的采样方法
- 样本编号: 样本编号
- 样本重复: 样本重复
- 图像: 从SMILES生成的分子结构图像
数据集统计
- 总样本数: 1632
- 图像格式: PIL图像(RGB)
- 图像尺寸: 300x300像素
使用方法
python from datasets import load_dataset dataset = load_dataset("molvision/BBBP-V-Train")
数据字段说明
Question(字符串): 问题文本Answer(字符串): 答案文本TargetMolecule(字符串): SMILES表示SampleMethod(字符串): 采样方法SampleNum(整数): 样本编号SampleRep(字符串): 样本重复image(PIL.Image): 分子结构可视化
引用要求
如在研究中使用本数据集,请引用该数据集。
搜集汇总
数据集介绍
构建方式
在分子生物学与化学信息学领域,BBBP-V-Train数据集通过系统化的数据采集流程构建而成。其核心基于化合物SMILES表示法,将分子结构转化为标准字符串格式,并利用算法生成对应的二维结构可视化图像。采样过程采用多种方法确保数据多样性,每条记录均包含目标分子的问答对、采样参数及图像数据,最终形成包含1632个样本的标准化集合。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,使用标准接口调用load_dataset函数即可获取完整数据。数据字段包含问答文本、SMILES序列及分子图像,支持端到端的多模态模型训练。典型应用场景包括分子性质预测、视觉问答任务,以及化学语言模型与图像生成模型的联合优化,为药物发现领域的算法开发提供标准化实验平台。
背景与挑战
背景概述
在计算化学与药物发现领域,分子性质预测始终是核心研究议题之一。BBBP-V-Train数据集由Molvision团队构建,聚焦于血脑屏障穿透性(Blood-Brain Barrier Penetration)这一关键生物医学问题,通过结合分子结构图像与SMILES序列表示,为多模态机器学习模型提供训练基础。该数据集通过视觉化分子结构与问答对形式,深化了对化合物跨膜转运机制的理解,推动了药物设计智能化进程。
当前挑战
血脑屏障穿透性预测需克服分子构效关系建模的复杂性,包括立体构型对生物活性的影响及数据稀疏性问题。数据集构建过程中面临多模态对齐挑战:SMILES序列与二维结构图像的语义一致性保障、分子可视化标准化,以及小规模样本下对化学空间多样性的覆盖不足,均对模型泛化能力提出更高要求。
常用场景
经典使用场景
在计算化学与药物发现领域,BBBP-V-Train数据集作为分子性质预测的关键资源,广泛应用于跨模态学习任务中。该数据集通过整合SMILES序列与分子结构图像,支持模型从文本和视觉双重角度理解分子特性,尤其在血脑屏障渗透性预测方面,为多模态神经网络提供了标准化的训练基准。
解决学术问题
该数据集有效解决了分子表示学习中单一模态的局限性问题,通过融合符号化SMILES与结构化图像数据,显著提升了模型对分子空间构象与生物活性关联的解析能力。其多模态特性为药物毒性筛选和生物利用度预测提供了新范式,推动了计算化学与人工智能的交叉研究进展。
实际应用
在制药工业实践中,该数据集被用于构建智能药物设计平台,辅助研究人员快速评估候选化合物的血脑屏障穿透潜力。通过自动化分析分子结构与渗透性的关联,显著缩短了中枢神经系统药物研发周期,为临床前研究的决策优化提供了数据支撑。
数据集最近研究
最新研究方向
在药物发现与化学生物学领域,BBBP-V-Train数据集正推动多模态分子表征学习的前沿探索。研究者们聚焦于融合SMILES序列与分子结构图像的双模态数据,通过视觉-语言预训练技术突破传统分子属性预测的局限。这一方向紧密关联AI驱动的药物设计热点,尤其在血脑屏障渗透性预测任务中展现出变革潜力,为加速中枢神经系统药物研发提供了可解释的计算范式。
以上内容由遇见数据集搜集并总结生成


