MessIRve
收藏Dataset Card for MessIRve
Dataset Details
Dataset Description
- Language(s) (NLP): Spanish
- License: CC BY-NC 4.0
Dataset Sources
- Repository: TBA
- Paper: MessIRve: A Large-Scale Spanish Information Retrieval Dataset
Dataset Structure
Data Instances
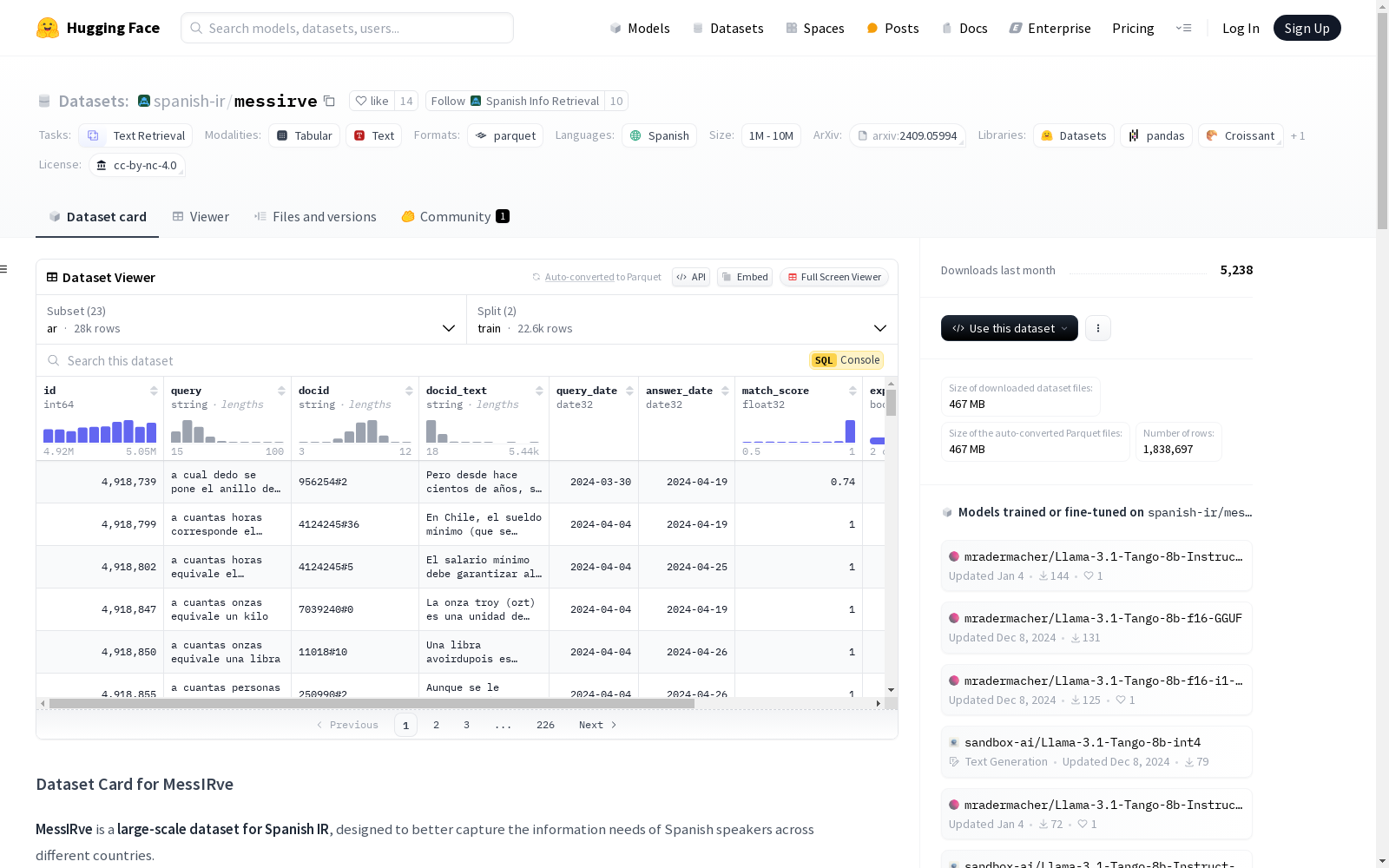
A typical instance of one subset of the dataset looks like:
json { "id": 4918739, "query": "a cual dedo se pone el anillo de compromiso", "docid": "956254#2", "docid_text": "Pero desde hace cientos de años, se dice que la vena amoris pasa por el dedo anular izquierdo que conecta directamente al corazón (téngase en cuenta que la vena amoris no existe realmente). Tradicionalmente, es ofrecido por el hombre como regalo a su novia mientras o cuando ella accede a la proposición de matrimonio. Representa una aceptación formal del futuro compromiso.", "query_date": "2024-03-30", "answer_date": "2024-04-19", "match_score": 0.74, "expanded_search": false, "answer_type": "feat_snip" }
Data Fields
id: query idquery: query textdocid: relevant document id in the corpusdocid_text: relevant document textquery_date: date the query was extractedanswer_date: date the answer was extractedmatch_score: the longest string in the SERP answer that is a substring of the matched document text, as a ratio of the length of the SERP answerexpanded_search: if the SERP returned a message indicating that the search was "expanded" with additional results ("se incluyen resultados de...")answer_type: type of answer extracted (feat_snippet, featured snippets, are the most important)
Data Splits
The dataset is split into multiple configurations, each corresponding to a different country or a combination of countries. Each configuration has a train and test split.
Configurations
- ar: Argentina
- bo: Bolivia
- cl: Chile
- co: Colombia
- cr: Costa Rica
- cu: Cuba
- do: Dominican Republic
- ec: Ecuador
- es: Spain
- full: Full dataset combining all countries
- general: General dataset
- gt: Guatemala
- hn: Honduras
- mx: Mexico
- ni: Nicaragua
- no_country: Queries not specific to any country
- pa: Panama
- pe: Peru
- pr: Puerto Rico
- py: Paraguay
- sv: El Salvador
- us: United States
- uy: Uruguay
- ve: Venezuela
Split Details
- train: Training set
- test: Test set
Example Configurations
- ar:
- train: 22,261 examples, 12.75 MB
- test: 5,780 examples, 3.35 MB
- bo:
- train: 25,015 examples, 14.64 MB
- test: 4,707 examples, 2.77 MB
- full:
- train: 571,120 examples, 333.36 MB
- test: 160,099 examples, 95.64 MB
Uses
The dataset is meant to be used to train and evaluate Spanish IR models.
- 1MessIRve: A Large-Scale Spanish Information Retrieval DatasetCONICET-UBA. Instituto de Ciencias de la Computación. Buenos Aires, Argentina · 2024年


