james-burton/OrientalMuseum_min5-mat-text
收藏Hugging Face2024-02-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/james-burton/OrientalMuseum_min5-mat-text
下载链接
链接失效反馈官方服务:
资源简介:
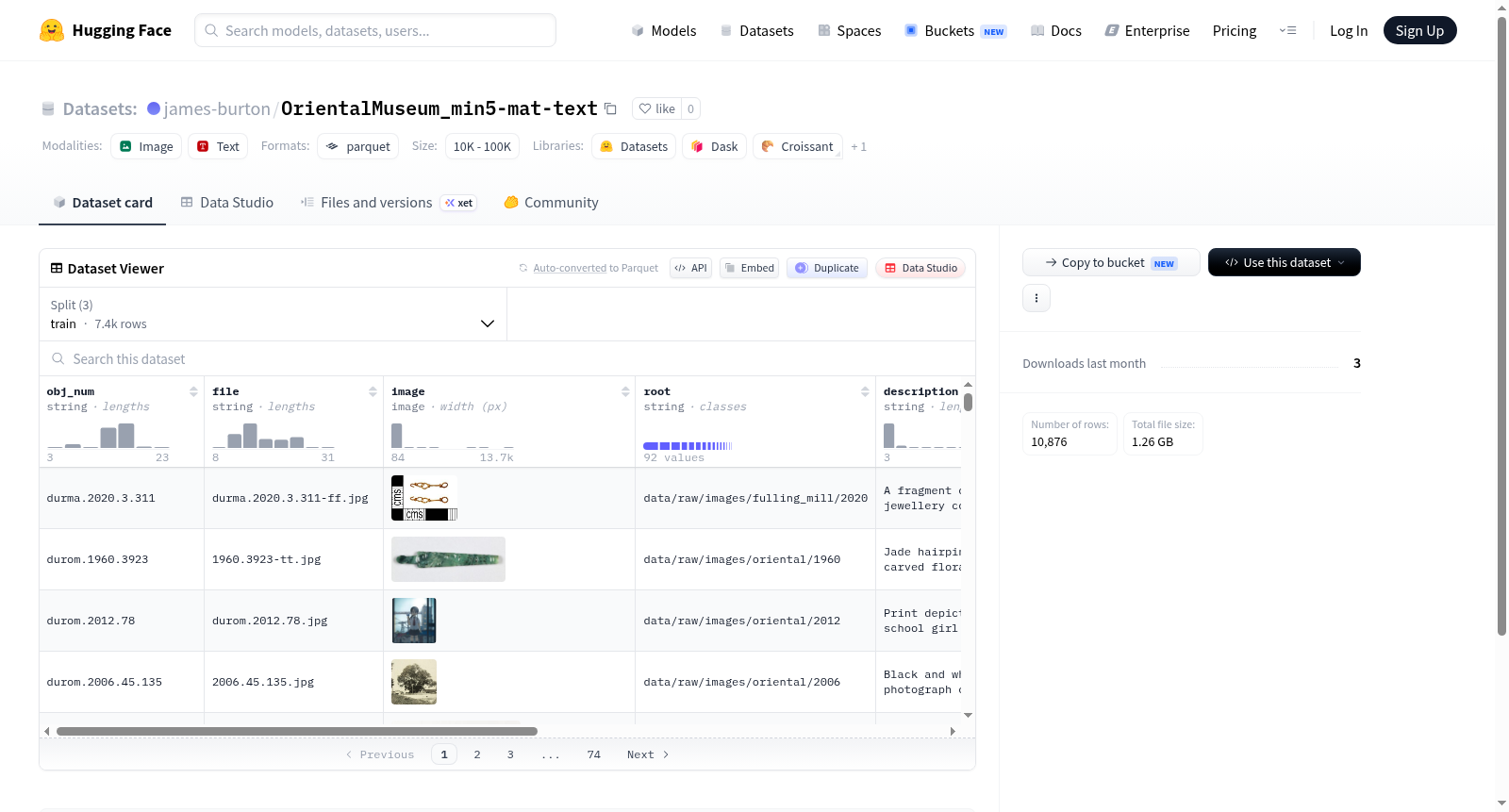
该数据集包含多个特征字段,如obj_num、file、image、root、description、object_name、other_name、label、production.period和production.place。其中label字段是一个分类标签,包含了100个不同的类别,涵盖了从动物木乃伊到各种材料和工艺品的广泛类别。数据集分为train、validation和test三个部分,分别包含7395、1740和1741个样本。数据集的下载大小为1261192796字节,总大小为1308615617.6230001字节。
This dataset contains multiple feature fields, including obj_num, file, image, root, description, object_name, other_name, label, production.period, and production.place. The label field is a classification label that encompasses 100 distinct categories, covering a wide range from animal mummies to various materials and handicrafts. The dataset is divided into three splits: train, validation, and test, which contain 7395, 1740, and 1741 samples respectively. The download size of the dataset is 1261192796 bytes, and the total storage size is 1308615617.6230001 bytes.
提供机构:
james-burton
原始信息汇总
数据集概述
数据集特征
- obj_num: 字符串类型
- file: 字符串类型
- image: 图像类型
- root: 字符串类型
- description: 字符串类型
- object_name: 字符串类型
- other_name: 字符串类型
- label: 分类标签类型,包含以下类别:
- 0: Animal Mummy
- 1: Batik
- 2: Colour on Paper
- 3: Flint/Chert
- 4: Gouache on Paper
- 5: Ink and Colour on Paper
- 6: Ink and Colours on Silk
- 7: Ink and Opaque Watercolour on Paper
- 8: Ink on Paper
- 9: Japanese paper
- 10: Opaque Watercolour on Paper
- 11: Opaque Watercolour or Gouache on Mica
- 12: Pith
- 13: Pith Paper
- 14: Plant Product
- 15: Resin/Plastic
- 16: Rhinoceros Horn
- 17: Steatite/Soap Stone
- 18: Watercolour on Rice Paper
- 19: agate
- 20: alabaster
- 21: aluminum
- 22: amber
- 23: bamboo
- 24: basalt
- 25: bone
- 26: brass
- 27: bronze
- 28: canvas
- 29: cardboard
- 30: cards
- 31: carnelian
- 32: ceramic
- 33: clay
- 34: copper
- 35: copper alloy
- 36: cotton
- 37: diorite
- 38: earthenware
- 39: enamel
- 40: faience
- 41: flax
- 42: flint
- 43: gauze
- 44: glass
- 45: gold
- 46: granite
- 47: gray ware
- 48: hardwood
- 49: horn
- 50: ink
- 51: iron
- 52: ivory
- 53: jade
- 54: jasper
- 55: lacquer
- 56: lapis lazuli
- 57: lead
- 58: lead alloy
- 59: leather
- 60: limestone
- 61: linen
- 62: metal
- 63: mother of pearl
- 64: nephrite
- 65: nylon
- 66: organic material
- 67: paint
- 68: paper
- 69: papyrus
- 70: photographic paper
- 71: plaster
- 72: plastic
- 73: plate
- 74: polyester
- 75: porcelain
- 76: pottery
- 77: rattan
- 78: rice paper
- 79: sandstone
- 80: satin
- 81: schist
- 82: serpentine
- 83: shell
- 84: silk
- 85: silver
- 86: slate
- 87: soapstone
- 88: steel
- 89: stone
- 90: stoneware
- 91: stucco
- 92: sycamore
- 93: terracotta
- 94: textiles
- 95: tortoise shell
- 96: travertine
- 97: velvet
- 98: wood
- 99: wool
- production.period: 字符串类型
- production.place: 字符串类型
数据集划分
- train: 包含7395个样本,大小为890032569.7199836字节
- validation: 包含1740个样本,大小为192798286.96940786字节
- test: 包含1741个样本,大小为225784760.93360865字节
数据集大小
- 下载大小: 1261192796字节
- 数据集大小: 1308615617.6230001字节
配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
- data_files:
搜集汇总
数据集介绍
构建方式
该数据集以东方博物馆藏品为根基,精心构建了一个多模态文物图像与文本描述库。数据采集自博物馆的数字化档案,涵盖编号(obj_num)、文件路径(file)、图像(image)及藏品来源(root)等基础字段。尤为重要的是,数据集通过专家标注为每件文物赋予了精细的材质标签(label),涵盖从动物木乃伊、蜡染布到犀角、玉石等100种材质类别,并附有详细描述(description)、对象名称(object_name)及别名(other_name),同时记录了生产时期(production.period)与产地(production.place)信息。数据划分为训练集(7395例)、验证集(1740例)和测试集(1741例),总规模逾1.3GB,确保了模型训练的充分性与评估的可靠性。
特点
此数据集最显著的特点在于其材质的极端多样性与细粒度分类能力。100种材质标签覆盖了天然材料(如燧石、象牙、丝绸)、人造物(如塑料、聚酯)及复合材质(如铜合金),堪称一部微型的材料考古学图谱。图像与文本描述的深度耦合,使得每一件文物不仅拥有视觉表征,还承载着历史语境与工艺信息。此外,数据集中包含大量稀有材质(如皂石、蛇纹石、青金石),为长尾分布下的模型鲁棒性提供了天然挑战。这种跨文化、跨时代的材质标注体系,使得模型在识别东方文物时能够同时感知艺术风格与物质属性,为文化遗产数字化保护开辟了新路径。
使用方法
研究者可通过HuggingFace Datasets库直接加载该数据集,指定配置为'default'后自动获取训练、验证与测试分片。在模型应用层面,数据集支持多任务学习范式:可基于图像字段训练材质分类器,利用description字段进行图文检索或图像描述生成,亦可结合production.period与production.place实现时空维度的文物溯源。推荐在加载时启用流式模式以处理大规模图像数据,并利用torchvision或timm库对图像进行标准化预处理。对于材质标签,需注意其作为类别特征(class_label)的整数编码,可借助datasets库的int2str方法映射回原始名称,以提升模型输出的可解释性。
背景与挑战
背景概述
东方博物馆多模态数据集(OrientalMuseum_min5-mat-text)由james-burton及其团队构建,旨在为文化遗产数字化与人工智能交叉领域提供高质量的训练资源。该数据集收录了来自东方博物馆的7395件训练样本、1740个验证样本及1741个测试样本,涵盖从动物木乃伊、蜡染布到犀角、玉器等100种精细材质分类,并附有对象编号、图像、描述、制作时期与地点等结构化信息。其核心研究问题聚焦于如何通过多模态数据(文本描述与视觉图像)自动识别文物材质,以解决传统博物馆藏品管理中依赖专家人工标注的瓶颈。自发布以来,该数据集为计算机视觉、自然语言处理及数字人文领域的学者提供了基准测试平台,推动了少样本学习、跨模态检索等方向在文化遗产保护中的应用,尤其对东亚文物材质分类的标准化研究产生了深远影响。
当前挑战
该数据集所面临的挑战体现在双重维度:首先,在领域问题层面,文物材质识别不同于自然图像分类,需应对材质间视觉相似性(如‘皂石’与‘滑石’的质地接近)、光照与拍摄角度导致的纹理歧义,以及某些材质(如‘纸莎草’、‘生漆’)随时间老化的外观变化,这要求模型具备跨域泛化能力。其次,在构建过程中,团队遭遇了类别不均衡难题——如‘青铜’样本远超‘琥珀’或‘龟甲’,需通过数据增强或重采样策略缓解;同时,文物描述文本存在多语言混杂(如中文名称‘青花瓷’与英文‘porcelain’并存)、历史时期标注模糊(如‘不详’字段占比显著)等噪声,增加了多模态对齐的难度。此外,原始馆藏图像的分辨率差异与背景干扰(如玻璃展柜反光)进一步提升了特征提取的鲁棒性要求。
常用场景
经典使用场景
在文化遗产数字化与智能分析领域,OrientalMuseum_min5-mat-text数据集以其丰富的多模态信息(图像与文本描述)和精细的材质分类体系(涵盖100种材质标签,如丝绸、青铜、象牙等),成为训练与评估跨模态检索、零样本分类及细粒度视觉识别模型的核心基准。研究者常利用该数据集探索如何从文物图像中自动辨识材质属性,结合文本描述进行语义对齐,从而推动博物馆藏品自动化编目与知识图谱构建。其标签体系覆盖有机与无机材质,为研究材质在光照、老化等条件下的视觉不变性表征提供了独特实验平台。
实际应用
在实际应用中,OrientalMuseum_min5-mat-text数据集赋能了博物馆智慧管理系统的核心模块。例如,通过集成训练后的材质识别模型,可快速对海量藏品图像进行自动分类与标签补充,大幅降低编目人力成本。此外,该技术被用于在线展览的智能导览场景,用户上传文物照片即可获取材质、产地及历史背景信息,提升观展互动性。在文物保护领域,模型还能辅助监测材质退化趋势,为预防性保护策略提供数据支撑。
衍生相关工作
该数据集衍生了一系列经典工作,包括基于对比学习的跨模态文物检索模型(如利用图像与文本匹配实现“以图搜文”),以及针对不平衡材质类别设计的少样本学习框架。部分研究将其作为预训练数据,迁移至其他文化遗存材质识别任务(如欧洲油画基底材料分类)。此外,融合该数据集与生成对抗网络的工作,探索了虚拟文物修复中的材质纹理合成,为数字孪生博物馆的构建奠定了算法基础。这些成果已在ACM MM、CVPR等顶会发表,推动了计算文化遗产领域的范式革新。
以上内容由遇见数据集搜集并总结生成


