lexile_level_logging
收藏Hugging Face2025-10-26 更新2025-10-27 收录
下载链接:
https://huggingface.co/datasets/Toya0421/lexile_level_logging
下载链接
链接失效反馈官方服务:
资源简介:
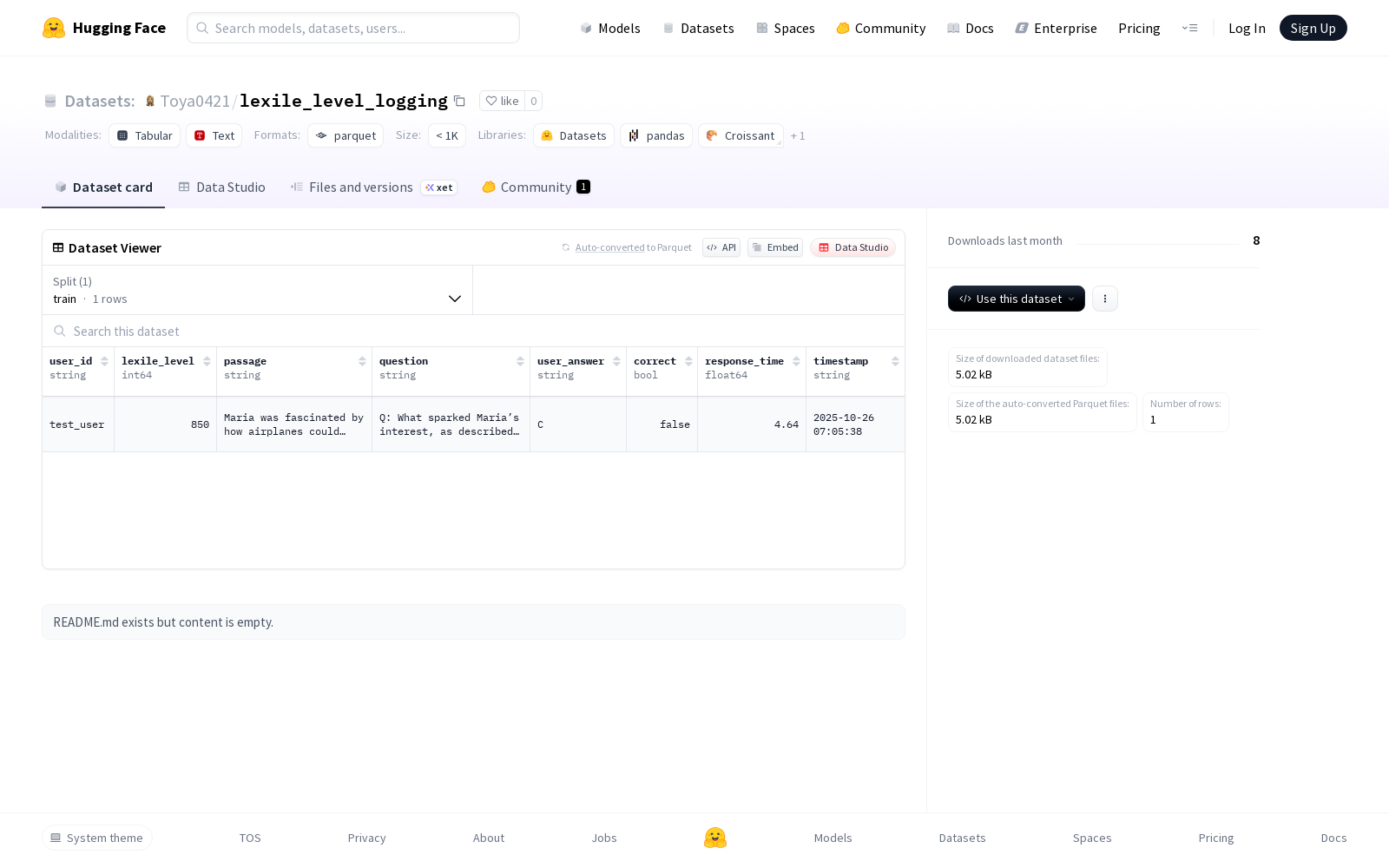
该数据集包含了用户ID、阅读能力等级、文章段落、问题、用户答案、是否正确、响应时间和时间戳等字段。数据集被划分为训练集,其中包含1个示例,数据集大小为335字节。数据集通过默认配置进行组织,训练数据文件以train-*模式命名。
This dataset includes fields such as user ID, reading proficiency level, article paragraphs, questions, user answers, correctness status, response time, and timestamp. The dataset is split into a training set which contains 1 sample, with a total size of 335 bytes. The dataset is organized via the default configuration, and the training data files follow the train-* naming pattern.
创建时间:
2025-10-24
原始信息汇总
数据集概述
基本信息
- 数据集名称: lexile_level_logging
- 存储位置: https://huggingface.co/datasets/Toya0421/lexile_level_logging
- 下载大小: 5022字节
- 数据集大小: 335字节
数据特征
- 字段结构:
- user_id (字符串类型)
- lexile_level (整数类型)
- passage (字符串类型)
- question (字符串类型)
- user_answer (字符串类型)
- correct (布尔类型)
- response_time (浮点数类型)
- timestamp (字符串类型)
数据划分
- 训练集:
- 样本数量: 1
- 数据大小: 335字节
配置信息
- 默认配置:
- 数据文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在语言能力评估领域,lexile_level_logging数据集通过系统化采集学习者与阅读材料的交互行为构建而成。该数据集整合了用户身份标识、蓝思阅读指数、文本段落、对应问题及用户回答等关键维度,并精确记录了答题准确率、响应时长与时间戳等多模态学习轨迹。数据采集过程严格遵循教育测量学规范,确保了学习行为数据的真实性与时序完整性。
特点
该数据集最显著的特征在于其多维度的认知能力表征体系。蓝思指数的引入为文本复杂度与学习者能力匹配提供了量化基准,而用户答案与标准答案的二元标注则构建了动态的能力评估框架。响应时间与时间戳的连续记录形成了细粒度的学习行为画像,这种融合静态能力指标与动态交互特征的设计,为教育数据挖掘提供了立体化的分析视角。
使用方法
研究者可基于该数据集开展教育认知诊断模型的训练与验证。通过解析用户答题序列与响应模式,能够构建个性化的能力增长曲线。在具体应用中,建议将用户历史答题记录作为时序输入,联合文本语义特征与元数据构建端到端的预测模型。该数据集支持教育干预效果评估、自适应学习路径推荐等典型场景,为智慧教育研究提供实证基础。
背景与挑战
背景概述
Lexile_level_logging数据集聚焦于教育技术领域的个性化学习评估,由研究机构在数字教育蓬勃发展的背景下构建。该数据集通过记录学习者的阅读能力等级、答题行为及响应时间等多元特征,旨在量化分析学生的认知负荷与学习效率。其核心价值在于为自适应学习系统提供实证基础,推动阅读教学从统一范式向精准干预转型,对教育数据挖掘领域产生深远影响。
当前挑战
该数据集需解决阅读能力动态评估中的时序建模挑战,包括如何从稀疏交互数据中推断认知发展轨迹,以及跨用户行为差异对模型泛化能力的制约。构建过程中面临多源日志融合的复杂性,例如原始数据中时间戳异构性处理、用户隐私信息脱敏与数据标注一致性保障等问题,这些因素共同增加了高质量教育数据集的构建难度。
常用场景
经典使用场景
在自适应学习系统中,lexile_level_logging数据集通过记录学生的阅读能力级别、答题表现及响应时间,为个性化教育路径的构建提供了实证基础。该数据集常用于训练机器学习模型,以动态调整学习材料的难度,确保内容与学生当前的阅读水平相匹配,从而优化学习效率。
实际应用
在实际教育场景中,该数据集被广泛应用于智能辅导系统的开发,帮助教师识别学生的知识薄弱点并实施针对性教学。此外,它还可用于教育机构的质量监控,通过分析学生答题模式与时间消耗,优化课程设计并提升整体教学成效。
衍生相关工作
基于lexile_level_logging数据集,研究者衍生出多项经典工作,如基于时序行为的遗忘曲线建模、结合深度学习的知识追踪框架构建等。这些研究不仅扩展了教育数据挖掘的方法论,还为开发更智能的自适应学习平台奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


