PhyGround
收藏arXiv2026-05-12 更新2026-05-13 收录
下载链接:
https://phyground.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
PhyGround是由东北大学等机构联合构建的用于评估生成世界模型中物理推理能力的基准数据集。该数据集包含250个精心策划的提示词,每个提示词均附有明确的预期物理结果,并涵盖固体力学、流体动力学和光学三大领域的13条物理定律,数据来源于现有视频语料库的提取与人工验证。数据集的创建过程涉及从多源收集提示词、进行预期结果增强、以及基于社会科学实验设计原则的大规模质量控制标注,最终获得了来自459名标注者提供的37,400多个细粒度标签。该数据集旨在解决生成视频中物理合理性评估的挑战,通过提供细粒度、可诊断的评分框架,支持视频生成模型在物理推理能力上的可靠评测与改进,适用于人工智能、计算机视觉和物理模拟等领域。
PhyGround is a benchmark dataset jointly constructed by Northeastern University (China) and other institutions for evaluating physical reasoning capabilities in generative world models. This dataset contains 250 carefully curated prompts, each paired with a clear expected physical outcome, covering 13 physical laws spanning three core domains: solid mechanics, fluid dynamics, and optics. The dataset's data is extracted from existing video corpora and manually verified. The construction of this dataset involves collecting prompts from diverse sources, enhancing the expected outcomes, and performing large-scale quality control annotations based on the principles of social science experimental design, ultimately yielding over 37,400 fine-grained labels from 459 annotators. This dataset aims to address the challenge of assessing physical plausibility in generated videos; by providing a fine-grained and diagnosable scoring framework, it enables reliable evaluation and enhancement of physical reasoning capabilities for video generation models, and is applicable to research fields including artificial intelligence, computer vision, and physical simulation.
提供机构:
东北大学; 杜兰大学; 华盛顿大学; 卡内基梅隆大学
创建时间:
2026-05-12
原始信息汇总
根据您提供的HTML文本内容,以下是对数据集详情页的总结:
数据集概述
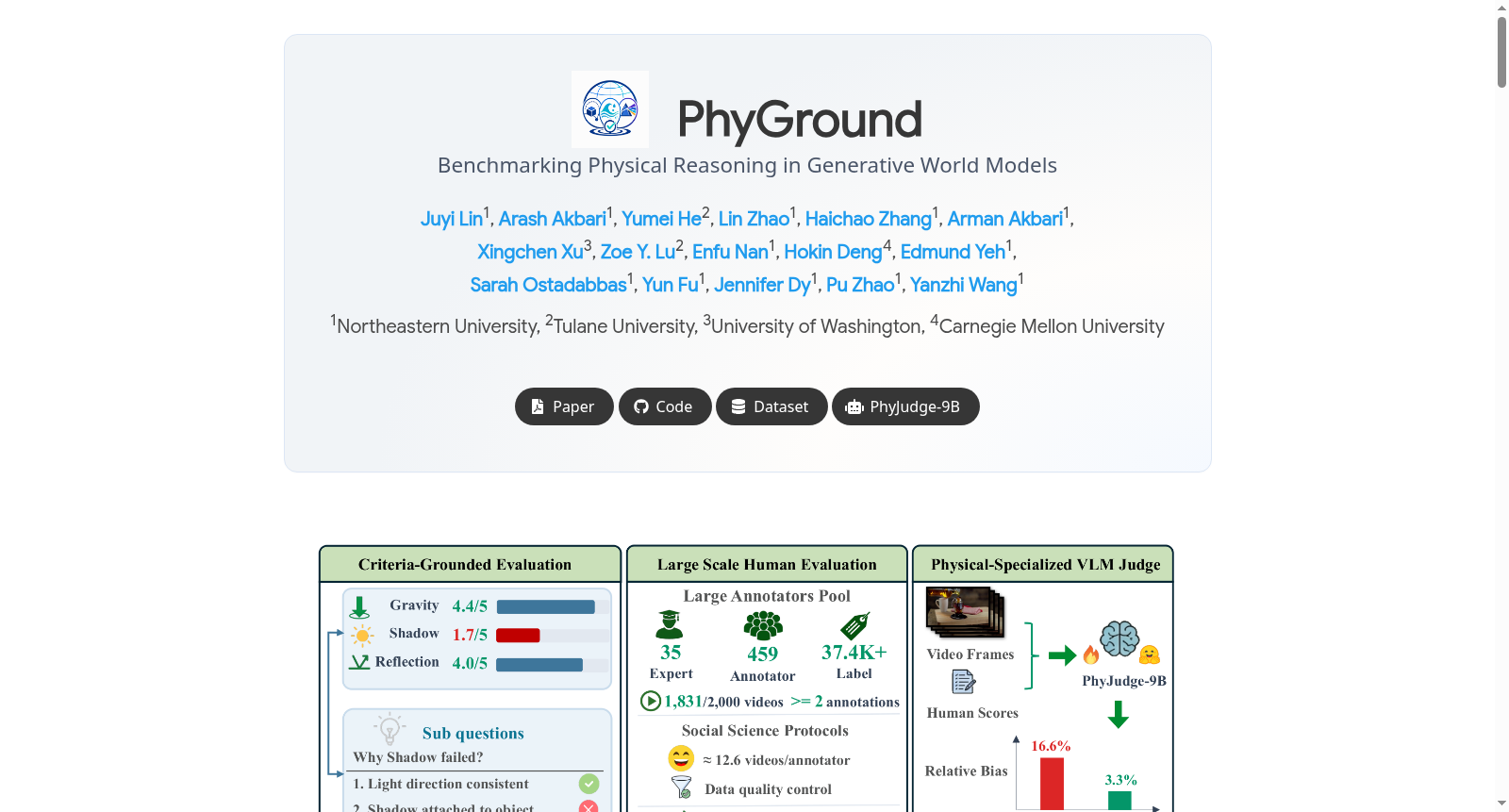
PhyGround 是一个用于评估视频生成模型中物理推理能力的基准测试集。它通过将模型的整体物理推理得分分解到13个物理定律上,实现细粒度的诊断性评估。
核心特点
- 基准规模:包含 250个精心设计的提示(prompts),每个提示都附带预期的物理结果。
- 物理定律分类:涵盖 13个物理定律,涉及刚体力学、流体动力学和光学三个领域。
- 人类评估:招募了 459名标注员,进行了大规模、质量受控的人类研究,共获得 5,796份完整标注 和 超过37,400个细粒度标签。质量控制的标注在分半模型排名相关性上表现出高一致性(Spearmans ρ > 0.90)。
- 自动化评估器:发布 PhyJudge-9B,一个开源的、专门针对物理学的视觉语言模型(VLM)评判器。其聚合相对偏差(3.3%)显著低于Gemini-3.1-Pro(16.6%)。
数据集组成
- 提示集:250个提示,每个提示对应一个预期的物理结果。
- 物理定律分类:13个物理定律,每个定律通过可观察的子问题进行操作化定义,支持按定律进行诊断。
- 人类标注:大规模人工评分结果。
- 模型检查点:PhyJudge-9B的模型权重。
- 评估代码:用于复现评估的代码。
评估模型
该基准测试评估了以下8个现代视频生成模型:
- Wan2.2-27B-A14B
- Veo-3.1 (closed)
- OmniWeaving
- Cosmos-14B
- LTX-2.3-22B
- Wan2.2-TI2V-5B
- Cosmos-2B
- LTX-2-19B
评估维度
评估使用1-5分制,包括以下维度:
- General quality: 总体质量
- Physical reasoning by domain:
- SA (具体指标未在文本中展开)
- PTV (具体指标未在文本中展开)
- Persist. (具体指标未在文本中展开)
- Solid-Body: 刚体物理
- Fluid: 流体物理
- Optical: 光学物理
- Overall: 综合得分
示例物理定律
基准测试涵盖的13个物理定律包括:
- 碰撞 (Collision)
- 动量 (Momentum)
- 重力 (Gravity)
- 不可穿透性 (Impenetrability)
- 材质 (Material)
- 惯性 (Inertia)
- 边界交互 (Boundary Interaction)
- 流动力学 (Flow Dynamics)
- 阴影 (Shadow)
- 流体连续性 (Fluid Continuity)
- 位移 (Displacement)
- 浮力 (Buoyancy)
- 反射 (Reflection)
搜集汇总
数据集介绍
构建方式
PhyGround的构建从四类互补来源中精心筛选了250条提示词,每条提示词均通过预期物理结果扩充,明确指定了视频中应发生的物理现象(例如“球滚过桌子”被扩充为“球滚到边缘后掉落并在地板上弹跳”),从而杜绝了模糊的多种可能结局。所有提示词均采用首帧作为图像条件的统一文字加图像到视频格式,进一步确保了跨模型评测的公平性。基于这些提示词,研究者定义了横跨固体力学、流体动力学和光学三大领域的13条物理定律,每条定律又被操作化为2至3个可观察的子问题,并采用1至5分的李克特量表进行评分,从而构建出细粒度、可诊断的物理推理基准。
使用方法
在使用PhyGround时,研究者需基于提供的250条包含预期物理结果的提示词,使用首帧作为图像条件生成视频。每个生成视频需由自动裁判模型(如开源的PhyJudge-9B)或人工标注员,根据数据集中预设的物理定律子问题进行逐一评分。每个视频通常只评估2至4条适用的物理定律,每条定律单独评分,从而输出一张详细的、涵盖各物理维度的模型能力诊断图。研究者还可利用其提供的开源裁判模型、人类标注数据及评测代码,对新一代视频生成模型进行可重复、可审计的物理真实性评估,并识别模型在特定物理规律上的短板。
背景与挑战
背景概述
生成式世界模型在视频生成领域展现出巨大潜力,其理想目标在于精确模拟真实世界的物理规律。然而,当前模型生成的视频常违背基础物理原理,例如物体悬浮、流体质量不守恒、阴影方向与光源矛盾等现象频发,严重制约了其在可靠仿真与视觉推理等下游任务中的应用。为系统评估与诊断生成视频的物理合理性,来自东北大学、杜兰大学、华盛顿大学与卡内基梅隆大学的研究团队于2026年提出了PhyGround基准数据集。该数据集由Juyi Lin、Arash Akbari、Yumei He等研究者构建,核心研究问题是建立一个细粒度、可诊断且可复现的物理推理评估框架。PhyGround包含250个精心设计的提示词,覆盖固体力学、流体动力学与光学三大领域的13条物理定律,并通过大规模受控人工实验(459名标注员、逾37,000条标签)支撑可靠评估,最终推出了开源物理专用评估模型PhyJudge-9B,为领域内提供了坚实的基准基石。
当前挑战
PhyGround所应对的领域挑战集中于三大核心难题:其一,现有评估框架多停留在宏观域级层面,生成单一整体评分,掩盖了特定物理定律的失败模式——例如流体场景中可能同时存在流动动态合理与质量不守恒等相互独立的问题,笼统的评分无法暴露关键缺陷;其二,人工评估易受响应偏差与疲劳效应侵蚀,标注员在有限时间内需区分“视觉上看似合理”与“实际符合物理约束”的细微差异,小规模标注池更会放大个体偏见,损害评估稳定性;第三,自动化评估器普遍缺乏物理感知能力且难以审计,主流指标(如FVD、SSIM)无法检测物理违规,闭源VLM评估则面临可复现性危机。此外,构建过程中亦面临严峻挑战:如何将抽象物理定律操作化为可观测的子问题,确保标注界面清晰、工作量可控,并设计多信号质量控制流水线(如评分一致性、维度可区分性、同伴一致性、行为投入度)以剔除劣质标注,最终实现分割半模型排序相关性Spearman ρ > 0.90的高可靠性,均是PhyGround团队在工程与实验设计层面攻克的关键难关。
常用场景
经典使用场景
在视频生成与物理推理的交叉领域中,PhyGround被广泛应用于对生成式世界模型进行细粒度的物理合理性诊断。该基准通过精心设计的250条提示词,每条均附有明确的预期物理结果,并依据13条物理定律(涵盖固体力学、流体动力学与光学)构建了分层评估体系。研究者利用PhyGround对八种主流视频生成模型进行大规模人类评估与自动评判,从而揭示模型在不同物理约束下的优势与短板。其最经典的使用场景在于替代传统粗粒度的整体评分,实现对重力、碰撞、流体连续性等具体物理定律的独立诊断,为模型改进提供精确的定位依据。
解决学术问题
PhyGround有效解决了现有物理视频基准中存在的三大核心学术问题:其一,粗粒度评估框架掩盖了特定物理定律的失败模式,PhyGround通过每定律细粒度分解与子问题设计,实现了对物理违反的精准诊断;其二,人类评估常受响应偏差与疲劳效应影响,PhyGround借鉴社会科学实验设计,招募459名标注者并实施质量控制,显著提升了评估稳定性和可靠性;其三,自动化评估器缺乏物理感知或难以审计,PhyGround通过开源微调专用VLM评判器PhyJudge-9B,将相对偏差降低至3.3%,为可复现、可审计的物理视频评估奠定了坚实基础。
实际应用
PhyGround的实际应用场景广泛渗透于视频生成模型研发与部署的全链条。在模型选型阶段,开发者可利用其每定律诊断分数对比不同模型的物理性能,例如揭示某模型在固体力学表现优异但流体动力学薄弱的特点,从而指导模型选择。在模型迭代优化中,PhyGround的细粒度评分可作为针对性后训练的目标函数,用于强化特定物理定律的遵守能力。此外,内容生成平台可借助PhyJudge-9B自动筛选符合物理规律的视频片段,提升生成内容的真实感与用户信任度,尤其适用于需要可靠物理仿真的游戏、虚拟现实及教育模拟领域。
数据集最近研究
最新研究方向
当前,随着生成式世界模型在视频生成领域的广泛应用,如何确保生成内容遵循真实世界的物理规律成为核心挑战。PhyGround基准的提出,标志着物理推理评估从粗粒度的整体评分向细粒度、可诊断的逐物理定律分析转变,代表了该领域的前沿研究方向。该基准通过构建涵盖固体力学、流体动力学与光学三大领域的13种物理定律分类体系,并引入基于社会科学实验设计的大规模、质量控制人体标注流程,解决了现有评估框架中定律特异性失败被掩盖、标注偏差以及自动化评估者物理感知不足等关键问题。PhyGround不仅揭示了当前主流视频生成模型在物理合理性上的显著短板——例如接触动力学(动量与碰撞)仍是普遍瓶颈,且不同模型在固体、流体与光学域展现出迥异的能力轮廓,还发布了开源的物理专用视觉语言模型裁判PhyJudge-9B。该裁判在聚合相对偏差上显著优于闭源模型(3.3%对16.6%),为可复现、可审计的物理视频评估提供了坚实的基础设施,对推动生成式世界模型向更可靠、更接近物理真实的仿真能力演进具有里程碑式的意义。
相关研究论文
- 1PhyGround: Benchmarking Physical Reasoning in Generative World Models东北大学; 杜兰大学; 华盛顿大学; 卡内基梅隆大学 · 2026年
以上内容由遇见数据集搜集并总结生成


