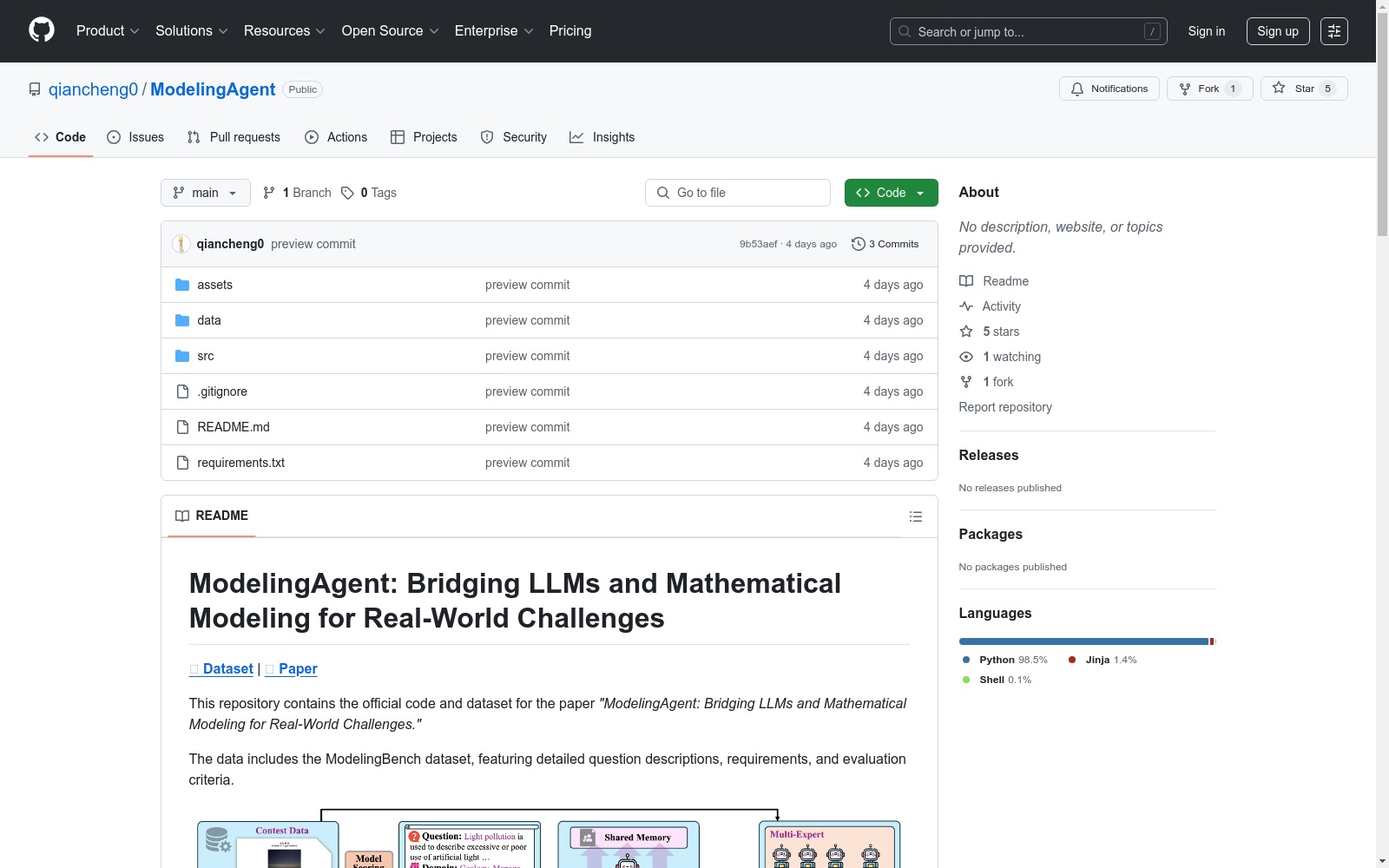
ModelingBench
收藏ModelingAgent数据集概述
数据集基本信息
- 名称:ModelingBench
- 用途:用于连接大型语言模型(LLMs)与数学建模,解决现实世界挑战
- 数据位置:
data目录 - 许可:可自由用于各种用途
数据结构
每个数据点包含以下字段: json { "year": "年份", "title": "标题", "level": "难度级别", "source": "来源", "link": "问题链接", "question": "问题描述", "requirements": [ { "category": "需求类别", "description": "需求描述" } ], "eval_roles": [ { "name": "评估角色名称", "details": "角色详细信息" } ] }
数据集示例
json "2001_Adolescent_Pregnancy": { "year": "2001", "title": "Adolescent Pregnancy", "level": "High School", "source": "HiMCM", "link": "Problems/2001/HIMCM-A-2/index.html", "question": "You are working temporarily for the Department of Health ...", "requirements": [ { "category": "Data Analysis", "description": "Evaluate the accuracy and completeness of the data ..." } ], "eval_roles": [ { "name": "Mathematician", "details": "You are a mathematician with expertise in ..." } ] }
相关资源
- 论文:https://www.arxiv.org/pdf/2505.15068
- 代码结构:
ModelAgent:ModelingAgent方法代码ModelBase:Vanilla Generation基线代码ModelTool:Tool Agent基线代码judger:ModelingJudge评估框架代码tools:沙箱环境中可能调用的工具
引用格式
text @article{qian2025modelingagent, title={ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges}, author={Qian, Cheng and Du, Hongyi and Wang, Hongru and Chen, Xiusi and Zhang, Yuji and Sil, Avirup and Zhai, Chengxiang and McKeown, Kathleen and Ji, Heng}, journal={arXiv preprint arXiv:2505.15068}, year={2025} }