Twitter/TwitterFollowGraph
收藏Hugging Face2022-10-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Twitter/TwitterFollowGraph
下载链接
链接失效反馈官方服务:
资源简介:
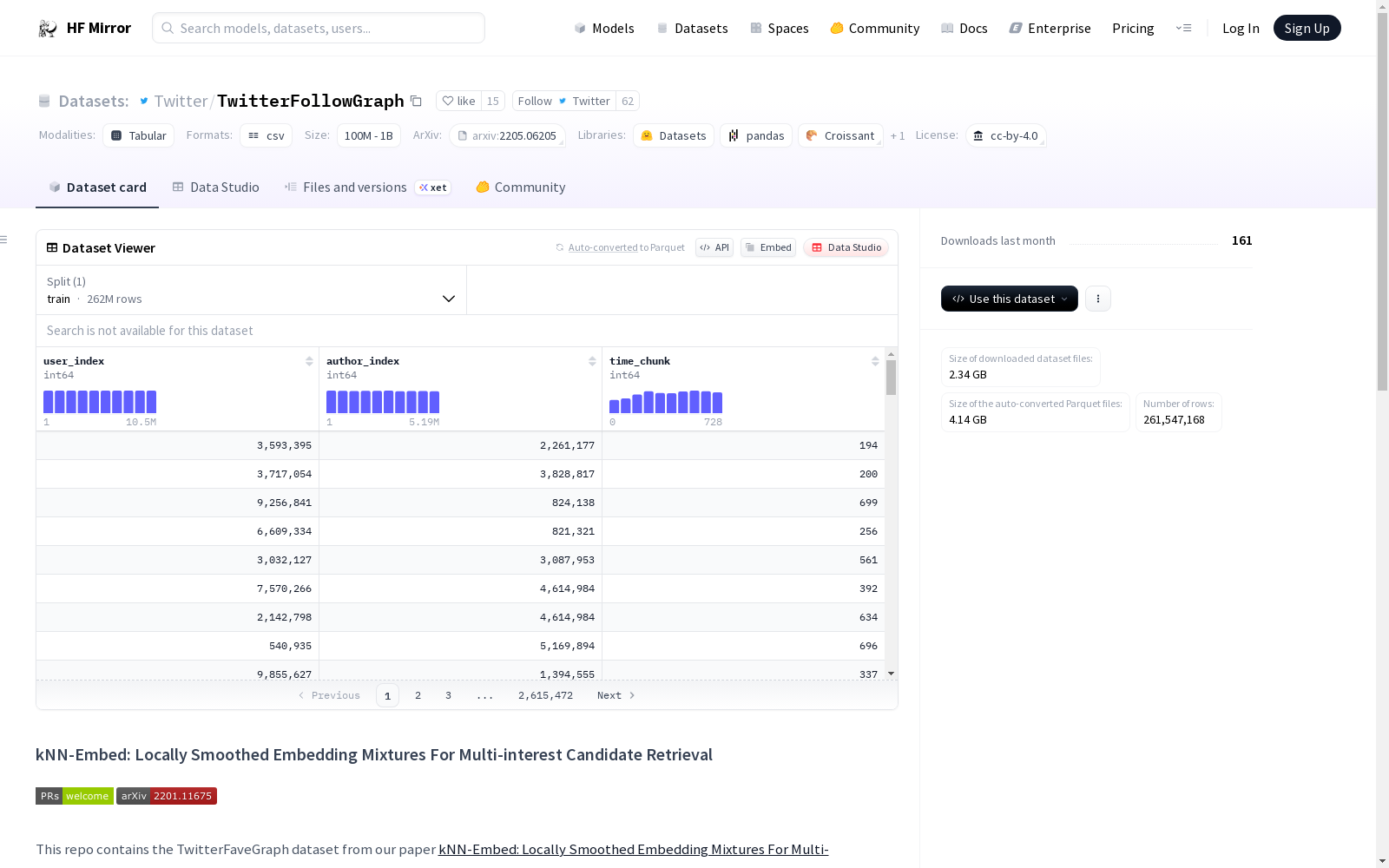
TwitterFollowGraph是一个二部有向图,包含用户(消费者)节点和作者(生产者)节点,其中边表示用户“关注”作者的互动。每条边都被分配到预定义的时间块中,这些时间块用序数表示,序数是连续的并尊重互动的时间顺序。TwitterFollowGraph总共有261M条边和15.5M个顶点,最大度为900K,最小度为5。数据格式如下表所示:| user_index | author_index | time_chunk |
TwitterFollowGraph是一个二部有向图,包含用户(消费者)节点和作者(生产者)节点,其中边表示用户“关注”作者的互动。每条边都被分配到预定义的时间块中,这些时间块用序数表示,序数是连续的并尊重互动的时间顺序。TwitterFollowGraph总共有261M条边和15.5M个顶点,最大度为900K,最小度为5。数据格式如下表所示:| user_index | author_index | time_chunk |
提供机构:
Twitter
原始信息汇总
数据集概述
数据集名称
- TwitterFollowGraph
数据集描述
- TwitterFollowGraph 是一个二分有向图,包含用户(消费者)节点和作者(生产者)节点,其中边代表用户“关注”作者的行为。每个边被划分到预定的时隙中,这些时隙用序数表示,且序数连续并遵循时间顺序。
数据集规模
- 总共有 261百万 条边和 15.5百万 个节点。
- 最大度为 90万,最小度为 5。
数据格式
| 字段 | 描述 |
|---|---|
| user_index | 用户索引 |
| author_index | 作者索引 |
| time_chunk | 时间块序号 |
许可证
- 本数据集遵循 Creative Commons Attribution 4.0 International License。
引用信息
bib @article{el2022knn, title={kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval}, author={El-Kishky, Ahmed and Markovich, Thomas and Leung, Kenny and Portman, Frank and Haghighi, Aria and Xiao, Ying}, journal={arXiv preprint arXiv:2205.06205}, year={2022} }
搜集汇总
数据集介绍
构建方式
TwitterFollowGraph数据集的构建,是通过采集Twitter用户间的关注关系形成的二分有向图。在该图中,用户节点与作者节点之间的边表示用户对作者的‘关注’行为。每条边都被划分到预定的时段桶中,并使用序数来表示,这些序数是连续的,且遵循着互动的时间顺序。该数据集总计包含了2.61亿条边和1550万个顶点,其中最大度数为90万,最小度数为5,体现了社交网络中的关注多样性。
特点
TwitterFollowGraph数据集的特点在于,它详细记录了Twitter用户与作者之间的关注行为,并且按照时间顺序进行了划分。这种结构为研究社交网络中的信息传播、用户行为模式以及网络演化提供了丰富的素材。数据集的规模之大,以及节点度数的分布范围,使其成为分析和理解大规模社交网络动态的有力工具。
使用方法
使用TwitterFollowGraph数据集时,研究者可以依据数据格式中的用户索引、作者索引以及时间桶,进行社交网络分析、图计算等研究。数据集遵循Creative Commons Attribution 4.0国际许可,允许用户在遵守许可协议的前提下,自由使用和分享数据。此外,使用该数据集的研究者应参照指定文献进行引用,以尊重数据集的原创作者权益。
背景与挑战
背景概述
TwitterFollowGraph数据集源于对社交网络中用户互动模式的研究,由Ahmed El-Kishky等研究人员于2022年提出。该数据集以Twitter平台上的用户关注关系为研究对象,构建了一个双边的有向图,其中节点分为用户节点和作者节点,边代表用户对作者的关注行为。该数据集总计包含2.61亿条边和15.5百万个顶点,是研究社交网络结构和用户互动模式的重要资源,对社交网络分析、推荐系统设计等领域产生了显著影响。
当前挑战
TwitterFollowGraph在构建过程中面临的主要挑战包括:如何准确捕捉并表示用户的动态关注行为,以及如何在保持数据规模的同时确保数据的时间连续性和有序性。此外,数据集所解决的领域问题,即用户多兴趣点候选检索,面临的挑战包括如何有效地处理用户兴趣的多样性和动态变化,以及如何在海量的社交网络数据中提取有价值的信息。
常用场景
经典使用场景
在社交媒体网络分析领域,TwitterFollowGraph数据集以其独特的双向有向图结构,成为研究用户兴趣模型和社交网络嵌入的重要资源。该数据集通过记录用户对作者的关注行为,为构建多兴趣点的候选检索系统提供了丰富的实证基础。
实际应用
实际应用中,TwitterFollowGraph数据集被广泛应用于社交媒体平台的内容推荐、用户行为分析以及社交网络服务的设计,对提升用户体验和平台服务质量具有显著影响。
衍生相关工作
基于TwitterFollowGraph数据集,研究者们衍生出一系列经典工作,包括用户行为预测模型、社交网络影响力分析工具,以及多模态信息融合的嵌入算法,推动了社交网络分析领域的发展。
以上内容由遇见数据集搜集并总结生成


