mGeNTE
收藏数据集概述
数据集名称
mGeNTE(Multilingual Gender-Neutral Translation Evaluation)
数据集主页
数据集简介
mGeNTE 是一个多语言语料库,旨在评估性别中立语言和自动翻译。该数据集基于从 Europarl 语料库 中提取的欧洲议会演讲数据,并且是双语 GeNTE 数据集的多语言扩展。
数据集结构
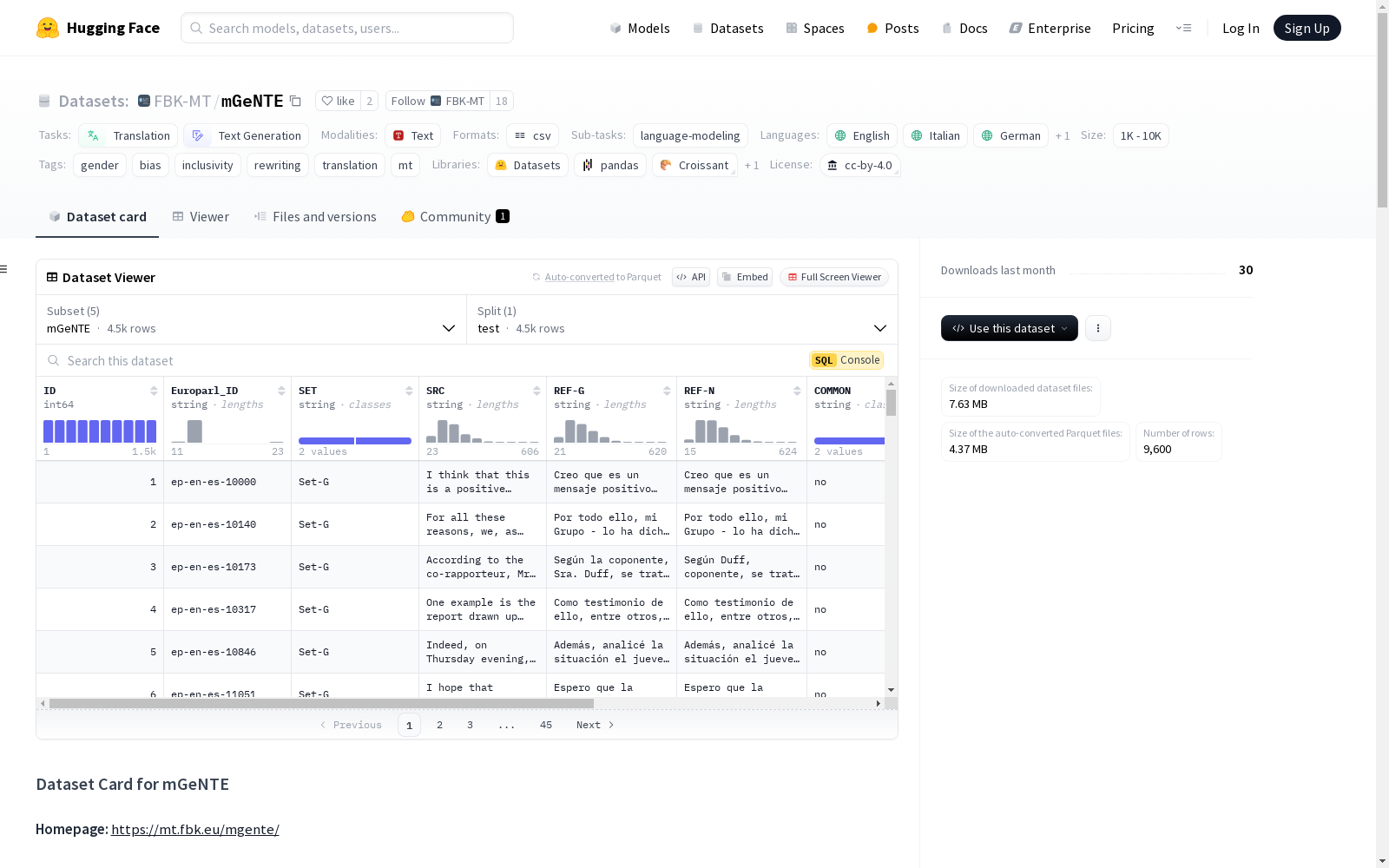
数据实例
数据集包含两种主要配置类型:
mGeNTE:完整的 GeNTE 语料库及其注释,包含每个语言对的 tsv 文件。mGeNTE_common:GeNTE 语料库的子集,包含 3 种替代的性别中立参考翻译。
数据字段
-
mGeNTE中的每个 tsv 文件包含 10 个以制表符分隔的列:- ID: 唯一的 mGeNTE ID。
- Europarl_ID: 来自 Europarl 的 common-test-set 2 的原始句子 ID。
- SET: 指示条目属于 Set-G 还是 Set-N 子集。
- SRC: 英语源句子。
- REF-G: 目标语言中的性别化参考翻译。
- REF-N: 由专业翻译人员生成的性别中立参考翻译。
- COMMON: 指示条目是否属于 GeNTE 公共集(是/否)。
- GENDER: 对于属于 Set-G 的条目,指示条目是女性还是男性(F/M)。
- REF-G_ann: 带有目标性别化单词注释的性别化参考翻译的标记化版本。
- G-WORDS: 以 "&" 分隔的注释目标性别化单词列表。
-
mGeNTE_common中的每个 tsv 文件包含 11 个以制表符分隔的列:- ID: 唯一的 GeNTE ID。
- Europarl_ID: 来自 Europarl 的 common-test-set 2 的原始句子 ID。
- SET: 指示条目属于 Set-G 还是 Set-N 子集。
- SRC: 英语源句子。
- REF-G: 目标语言中的性别化参考翻译。
- REF-N1: 由翻译人员 1 生成的性别中立参考翻译。
- REF-N2: 由翻译人员 2 生成的性别中立参考翻译。
- REF-N3: 由翻译人员 3 生成的性别中立参考翻译。
- GENDER: 对于属于 Set-G 的条目,指示条目是女性还是男性(F/M)。
- REF-G_ann: 带有目标性别化单词注释的性别化参考翻译的标记化版本。
- G-WORDS: 以 "&" 分隔的注释目标性别化单词列表。
数据集创建
创建动机
GeNTE 旨在测试性别中立语言建模,并评估模型在理想情况下执行性别中立翻译的能力。数据集包含平行句子,这些句子涉及人类指称,并平等地代表两种翻译场景:
Set-N:包含性别模糊的源句子,需要在翻译中以中立方式呈现。Set-G:包含性别明确的源句子,应在翻译中正确呈现为性别化(男性或女性)形式。
数据来源
数据集包含从 Europarl 语料库(common test set 2)中提取和编辑的文本数据,所有数据权利归欧盟和/或相应的版权持有者所有。
注释
对于从 Europarl 中提取的每个句子对(src, ref),mGeNTE 包括目标语言中的额外参考翻译,该翻译仅在指称人类实体时使用中性表达。
数据集维护者
mGeNTE 的作者是数据集的维护者。协调维护工作请联系 Beatrice Savoldi (FBK) bsavoldi@fbk.eu。
许可证信息
mGeNTE 语料库根据 Creative Commons Attribution 4.0 International 许可证(CC BY 4.0)发布。
引用
bibtex @misc{savoldi-etal-2025-mgente, title = {{mGeNTE: A Multilingual Resource for Gender-Neutral Language and Translation}}, author = "Savoldi, Beatrice and Cupin, Eleonora and Manjinder, Thind and Lauscher, Anne and Bentivogli, Luisa", month = jan, year = "2025", publisher = "arxiv", url = " " }
贡献者
感谢 @BSavoldi 添加此数据集。