floschne/xgqa
收藏Hugging Face2024-05-23 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/floschne/xgqa
下载链接
链接失效反馈官方服务:
资源简介:
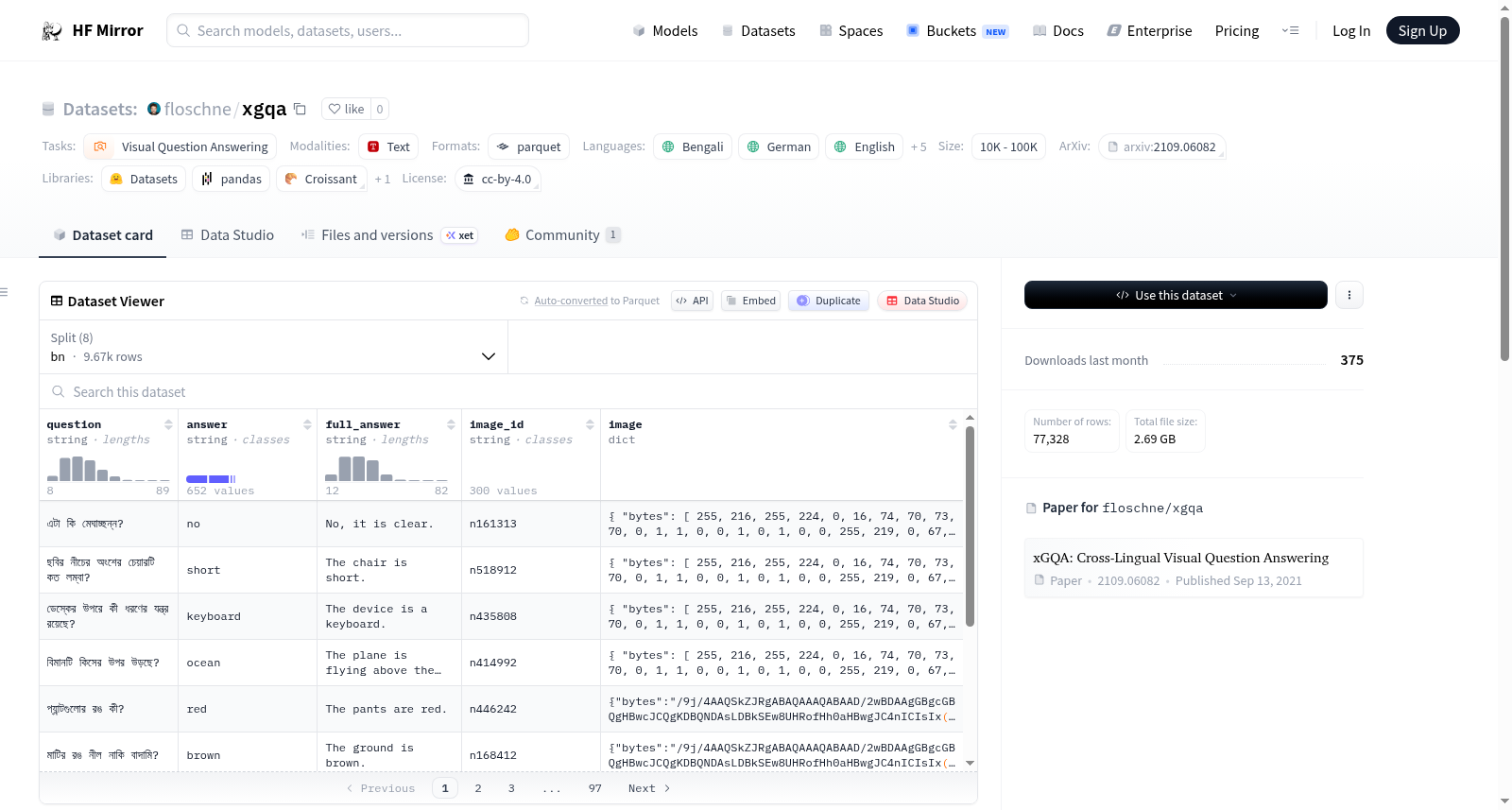
xGQA数据集是一个跨语言视觉问答数据集,包含多种语言的问题、答案、完整答案、图像ID和图像。数据集被分割为多种语言,每种语言都有相应的字节数和示例数。数据集的任务类别是视觉问答,支持多种语言。由于一个bug,图像不能直接存储为PIL.Image.Images,需要转换为dataset.Images-。
xGQA数据集是一个跨语言视觉问答数据集,包含多种语言的问题、答案、完整答案、图像ID和图像。数据集被分割为多种语言,每种语言都有相应的字节数和示例数。数据集的任务类别是视觉问答,支持多种语言。由于一个bug,图像不能直接存储为PIL.Image.Images,需要转换为dataset.Images-。
提供机构:
floschne
原始信息汇总
xGQA 数据集概述
数据集特征
- question: 数据类型为字符串
- answer: 数据类型为字符串
- full_answer: 数据类型为字符串
- image_id: 数据类型为字符串
- image: 结构化数据,包含以下子特征:
- bytes: 数据类型为二进制
- path: 数据类型为空
数据集分割
- bn: 9666个样本,总字节数498517814
- de: 9666个样本,总字节数498108367
- en: 9666个样本,总字节数498078827
- id: 9666个样本,总字节数498180441
- ko: 9666个样本,总字节数498157980
- pt: 9666个样本,总字节数498078408
- ru: 9666个样本,总字节数498298164
- zh: 9666个样本,总字节数498005624
数据集大小
- 下载大小: 2692912777字节
- 数据集大小: 3985425625字节
配置
- config_name: default
- data_files:
- split: bn, de, en, id, ko, pt, ru, zh
- path: data/bn-, data/de-, data/en-, data/id-, data/ko-, data/pt-, data/ru-, data/zh-
许可证
- license: cc-by-4.0
任务类别
- task_categories: visual-question-answering
语言
- language: bn, de, en, id, ko, pt, ru, zh
数据集名称
- pretty_name: xGQA
大小类别
- size_categories: 10K<n<100K
搜集汇总
数据集介绍
背景与挑战
背景概述
floschne/xgqa是一个跨语言视觉问答数据集,包含约77,328个样本,支持包括孟加拉语、德语、英语在内的8种语言,每个语言子集约有9.67k行数据。该数据集基于arXiv论文2109.06082,采用cc-by-4.0许可证,格式为parquet,主要用于训练和评估多语言视觉问答模型,但用户需注意图像数据需要特殊处理才能正确加载。
以上内容由遇见数据集搜集并总结生成


