HalluMix
收藏Hugging Face2025-05-02 更新2025-05-03 收录
下载链接:
https://huggingface.co/datasets/quotientai/HalluMix
下载链接
链接失效反馈官方服务:
资源简介:
HalluMix是一个面向现实世界场景的多领域、任务无关的虚构内容检测基准数据集,包含来自医疗、法律、科学和新闻等多个领域的示例,涵盖摘要、问答和自然语言推理等多种任务。
HalluMix is a real-world scenario-oriented, multi-domain, task-agnostic benchmark dataset for fictitious content detection. It includes examples from multiple domains such as healthcare, law, science, and journalism, covering a variety of tasks including summarization, question answering, and natural language inference.
创建时间:
2025-04-28
原始信息汇总
HalluMix 数据集概述
基本信息
- 许可证: Apache-2.0
- 语言: 英语 (en)
- 标签: hallucination-evaluation, benchmark
- 名称: HalluMix
数据集简介
HalluMix 是一个任务无关、多领域的基准数据集,旨在评估真实场景中的幻觉检测。数据集包含来自多个领域(如医疗、法律、科学和新闻)和多个任务(如摘要、问答、自然语言推理)的示例。
数据集内容
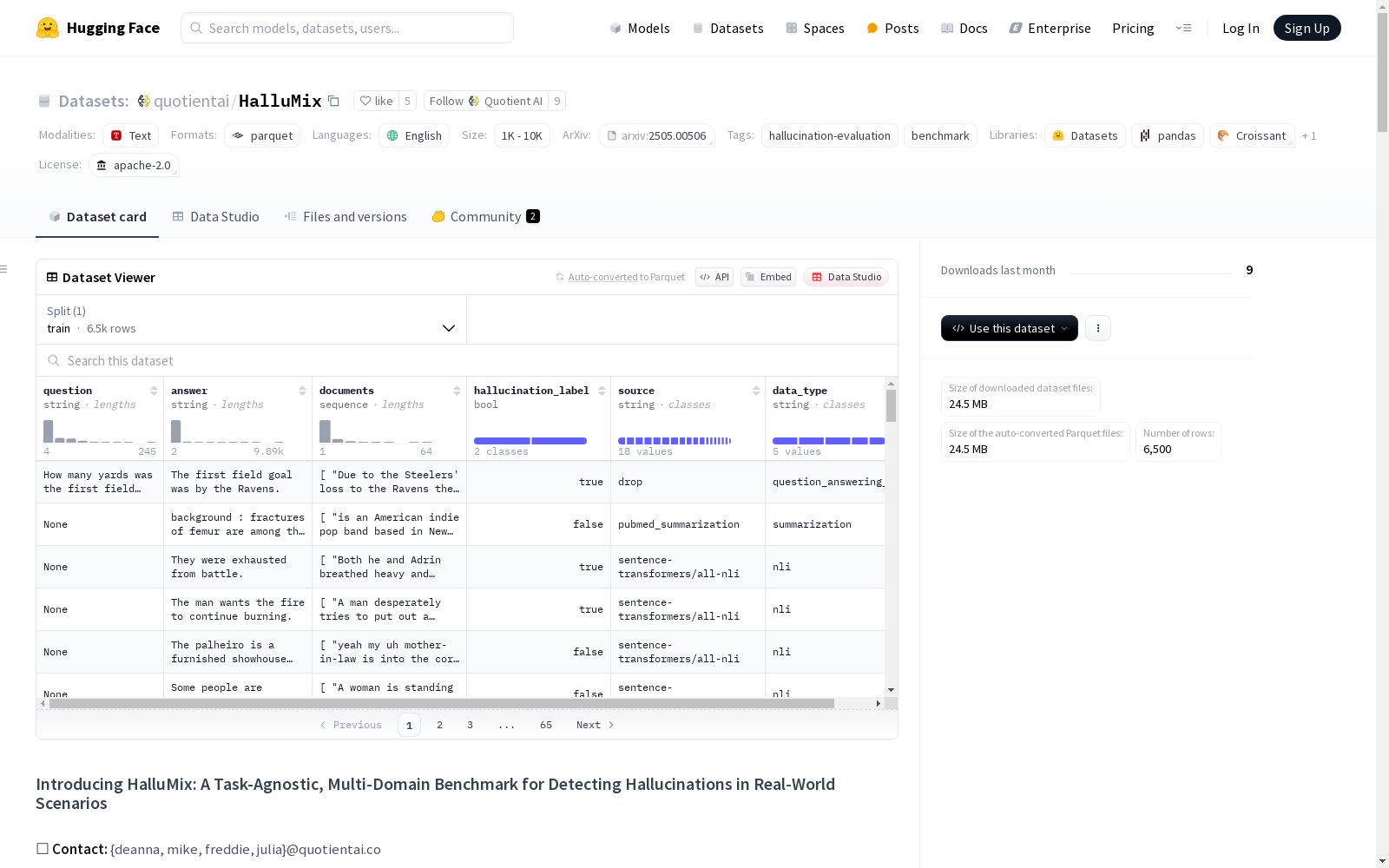
每个示例包含以下部分:
- 文档: 上下文表示为打乱的文本块列表,包含随机无关的文档块,模拟真实世界的检索增强生成(RAG)场景。
- 答案: 需要评估的假设,如摘要句子、答案或声明。
- 幻觉标签: 二元标签,标记响应是否包含幻觉。
- 源标识符: 原始数据集的标签,用于来源追踪。
数据集构建
HalluMix 通过以下方式整合高质量的人工标注数据集:
- 自然语言推理 (NLI) 数据集: 将“蕴含”标签映射为忠实,“中性/矛盾”标签映射为幻觉。
- 摘要数据集: 通过将摘要与不相关的文档匹配生成幻觉实例。
- 问答 (QA) 数据集: 包括上下文-答案不匹配、LLM生成的看似合理但不正确的答案,并将单字答案转换为陈述句。
数据集规模
- 示例数量: 6,500 个
- 领域: 医疗、法律、科学、新闻等
- 任务: 摘要、问答、自然语言推理等
评估结果
使用 HalluMix 评估了七种领先的幻觉检测系统,结果如下:
- Quotient Detections: 最佳整体性能(准确率: 0.82,F1分数: 0.84)。
- Azure Groundedness: 高精度但召回率较低。
- Ragas Faithfulness: 高召回率但精度较低。
关键发现
- 子源过拟合: 部分检测系统对特定数据集过拟合,泛化能力有限。
- 内容长度挑战: 幻觉检测的有效性高度依赖于上下文长度和句子间连贯性。
- 架构权衡: 连续上下文方法在长文本上表现良好,而句子级方法在短文本上表现优异。
引用
如需引用 HalluMix,请使用以下 BibTeX 条目: bibtex @article{emery2025hallumix, title={HalluMix: A Task-Agnostic, Multi-Domain Benchmark for Real-World Hallucination Detection}, author={Deanna Emery and Michael Goitia and Freddie Vargus and Iulia Neagu}, year={2025}, journal={arXiv preprint arXiv:2505.00506}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.00506}, }
示例
幻觉响应示例
- 文档: 描述了一场橄榄球比赛的详细过程。
- 响应: "第一个射门是由乌鸦队完成的。"
- 标签: 幻觉
忠实响应示例
- 文档: 包含多个无关文本块,其中一个提到“最终幻想”由坂口博信创建。
- 响应: "最终幻想由坂口博信创建。"
- 标签: 忠实
搜集汇总
数据集介绍
构建方式
HalluMix数据集的构建过程体现了对现实场景中语言模型幻觉问题的深刻洞察。研究团队通过精心整合多个高质量人工标注数据集,采用创新的数据转换策略,构建了这一跨领域、任务无关的基准测试集。具体而言,团队将自然语言推理数据集中的'蕴含'标签映射为忠实生成,'中性/矛盾'标签映射为幻觉;在摘要数据集中通过故意错配摘要与无关文档生成幻觉实例;在问答数据集中引入上下文-答案错配和模型生成的似是而非答案。这种严谨的方法论最终形成了一个包含6,500个样本的平衡数据集,覆盖多个任务领域。
使用方法
使用HalluMix数据集进行评测时,研究人员可以全面评估各类幻觉检测系统的性能表现。该数据集特别适合用于测试系统在处理不同长度文本、跨领域内容和多样化任务时的稳健性。评测指标包括准确率、F1值等传统分类指标,同时也能分析系统在精确率和召回率之间的权衡关系。数据集的设计还支持研究者探索连续上下文处理方法与句子级检测方法各自的优势,为开发更强大的幻觉检测算法提供了理想平台。
背景与挑战
背景概述
HalluMix数据集由QuotientAI团队于2025年推出,旨在解决大语言模型(LLMs)在关键行业应用中产生的幻觉问题。随着LLMs的广泛应用,确保其输出内容基于事实且可靠成为重要课题。传统幻觉检测基准多局限于特定任务或合成数据,难以应对现实场景的复杂性。HalluMix填补了这一空白,作为一个任务无关、多领域的基准,覆盖医疗、法律、科学和新闻等多个领域,支持摘要、问答和自然语言推理等多种任务。该数据集通过整合高质量人工标注数据,并引入干扰项以模拟真实检索场景,为幻觉检测提供了全面且现实的评估平台。
当前挑战
HalluMix数据集面临的主要挑战包括:1) 领域问题的复杂性,即如何在多领域、多任务场景中准确识别幻觉内容,尤其是处理长文本和跨句子依赖关系;2) 构建过程中的数据多样性问题,需平衡不同领域和任务的数据分布,同时确保干扰项的引入不影响数据有效性;3) 评估系统的泛化能力,现有检测系统在特定数据集上表现良好,但在面对新领域或长文本时性能下降,显示出泛化能力的不足。这些挑战突显了开发鲁棒幻觉检测方法的必要性。
常用场景
经典使用场景
在自然语言处理领域,HalluMix数据集被广泛应用于评估大语言模型生成内容的真实性。该数据集通过模拟真实场景中的多文档上下文和噪声干扰,为研究者提供了一个全面检测模型幻觉现象的平台。特别是在医疗、法律、科学和新闻等关键领域,HalluMix能够有效测试模型在不同任务(如摘要生成、问答和自然语言推理)中保持事实一致性的能力。
解决学术问题
HalluMix数据集解决了当前幻觉检测研究中存在的三个核心问题:传统基准测试难以捕捉真实场景复杂性、现有方法局限于特定任务、以及缺乏跨领域的统一评估标准。通过整合多个高质量数据集并引入干扰文档,该数据集为研究者提供了一个标准化工具,用以衡量模型在复杂上下文环境中保持事实准确性的能力,推动了可信AI系统的发展。
实际应用
在实际应用中,HalluMix数据集被企业和技术团队用于优化检索增强生成(RAG)系统的性能。例如,在医疗咨询和法律文件分析等场景中,基于该数据集开发的检测系统能够有效识别模型生成的错误信息,显著提升了AI辅助决策的可靠性。多家科技公司已将其纳入产品开发流程,以确保输出内容的事实准确性。
数据集最近研究
最新研究方向
在大型语言模型(LLMs)日益广泛应用于医疗、法律等关键领域的背景下,确保模型输出的真实性成为研究重点。HalluMix作为首个任务无关、多领域的幻觉检测基准,通过整合自然语言推理、摘要生成和问答系统等多种任务数据,模拟真实场景中的检索噪声,为幻觉检测研究提供了全面评估平台。当前研究聚焦于解决长文本上下文连贯性保持、跨领域泛化能力提升等核心挑战,探索分层或滑动窗口等混合架构,以平衡短文本精确检测与长文档上下文理解之间的性能差异。该数据集的发布推动了可信赖AI系统的开发,为缓解LLMs在实际部署中的幻觉问题提供了重要技术支撑。
以上内容由遇见数据集搜集并总结生成


