OCR-D-GT-VD-SBB
收藏Hugging Face2025-11-13 更新2025-11-14 收录
下载链接:
https://huggingface.co/datasets/SBB/OCR-D-GT-VD-SBB
下载链接
链接失效反馈官方服务:
资源简介:
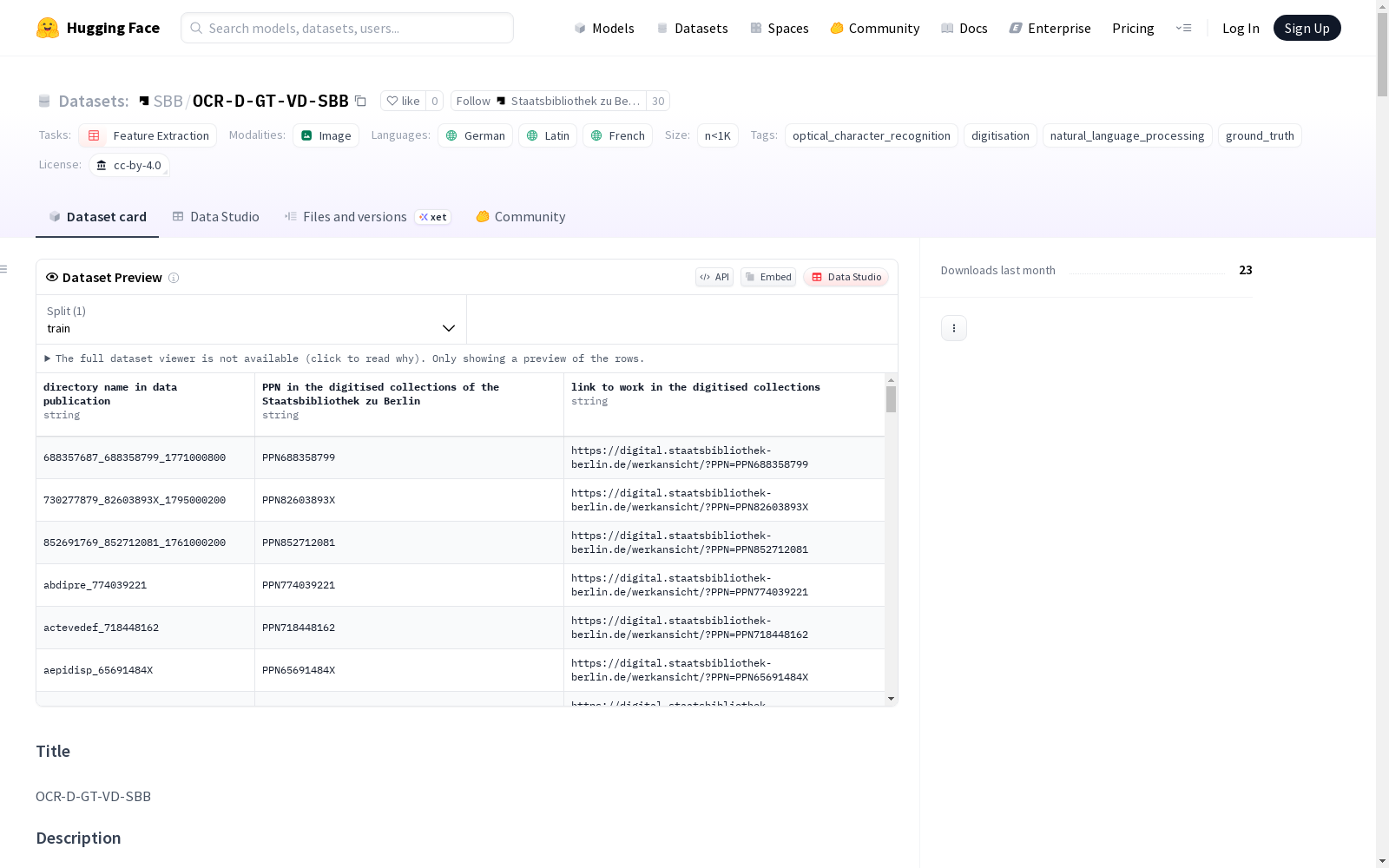
OCR-D-GT-VD-SBB数据集由OCR-D项目创建,包含348页从历史文献中提取的内容,这些文献属于“德国语言地区出现的印刷品目录”(VD),并由柏林国家图书馆数字化。数据集由348个.xml文件组成,这些文件包含了348个.tif图像文件的转录。图像文件来自67个不同的作品,每个作品提取了4个图像,其中两个作品分别提取了49和39个图像以创建地面真值(GT)。数据集还包括一个.csv文件,其中包含了该数据集中使用的标识符与柏林国家图书馆数字化收藏中使用的唯一标识符之间的映射,以及一个.csv格式的文件列表。数据选择是在柏林国家图书馆的[OCR-D](http://ocr-d.de/)项目内进行的。该项目由德国研究基金会DFG资助,项目资助号为460675868。GT数据由数字化服务提供商建立,并由柏林国家图书馆的工作人员进行了后期纠正。数据管理和发布由柏林国家图书馆“人类.机器.文化”研究项目团队的两位成员完成。该研究项目由联邦政府文化媒体专员(BKM)资助,项目资助号为2522DIG002。
The OCR-D-GT-VD-SBB dataset was created by the OCR-D project, containing content extracted from 348 pages of historical documents categorized under the Union Catalogue of Prints Published in the German-speaking Area (VD), which were digitized by the Berlin State Library (Staatsbibliothek zu Berlin, SBB). The dataset comprises 348 .xml files that hold the transcriptions corresponding to 348 .tif image files. These image files are sourced from 67 distinct works: 4 images were extracted from each work, with the exception of two works from which 49 and 39 images were respectively extracted to develop the ground truth (GT). Additionally, the dataset includes a .csv file that maps the identifiers used within this dataset to the unique identifiers employed in the digitized collections of the Berlin State Library, as well as a file list in .csv format. The data selection process was conducted within the framework of the [OCR-D](http://ocr-d.de/) project hosted by the Berlin State Library. This project is funded by the German Research Foundation (DFG) under grant number 460675868. The GT data was established by a digitization service provider and post-corrected by staff of the Berlin State Library. Data management and release were undertaken by two members of the research project team "Humans. Machines. Culture" at the Berlin State Library. This research project is funded by the Federal Government Commissioner for Culture and the Media (BKM) under grant number 2522DIG002.
创建时间:
2025-10-31
原始信息汇总
OCR-D-GT-VD-SBB 数据集概述
数据集基本信息
- 标题:OCR-D-GT-VD-SBB
- 描述:在OCR-D项目中创建的真实标注数据集,包含从"Verzeichnis der im deutschen Sprachraum erschienenen Drucke"历史文献中提取的348页内容,所有资料均由柏林国家图书馆数字化
- 许可证:CC BY 4.0
- 版本:1.0
- 发布日期:2025年10月31日
数据集组成
- 数据量:348页
- 文件格式:
- 348个XML转录文件
- 348个TIFF图像文件
- 2个CSV映射文件
- 数据来源:67部独立作品(1509-1827年间出版)
- 字符数量:486,098个字符
语言分布
- 主要语言:德语(40部)、拉丁语(23部)、法语(2部)
- 其他语言:拉丁语和德语混合(1部)、低地德语(1部)
主题分类
- 作品类型:专著、葬礼书籍、论文、大幅面印刷品
- 主题领域:神学、语言文学、法学、历史、民族志、地理、科学数学、医学
技术规格
- 数据标准:符合PAGE-XML模式
- 字符准确率:99.95%
- 维护级别:有限维护(仅解决技术问题)
应用领域
- 主要应用:光学字符识别
- AI类别:自然语言处理、特征提取
- 文化遗产应用:数字化
数据访问
- 访问地址:https://doi.org/10.5281/zenodo.17395956
- 校验和:
- MD5:757b1fb86979b97847ef86795f06d660
- SHA256:19490ee8b2f945d44bbbca053f931c0e18678513838f486184e4a325c3223975
引用信息
bibtex @dataset{baierer_2025_17395956, author = {Baierer, Konstantin and Federbusch, Maria and Gerber, Mike and Lehmann, Jörg and Neudecker, Clemens}, title = {OCR-D-GT-VD-SBB}, month = oct, year = 2025, publisher = {Staatsbibliothek zu Berlin – Berlin State Library}, version = 1, doi = {10.5281/zenodo.17395956}, url = {https://doi.org/10.5281/zenodo.17395956}, }
搜集汇总
数据集介绍
构建方式
在历史文献数字化研究领域,OCR-D-GT-VD-SBB数据集的构建体现了系统化的工程流程。该数据集从柏林国家图书馆的VD系列数字化馆藏中精选67部1509至1827年间出版的文献,涵盖专著、悼亡书、学位论文等类型。通过专业数字化服务商按OCR-D项目三级转录规范生成初始标注,字符级准确率达99.95%,再经图书馆专家团队使用专用脚本修复数据不一致性,并逐页人工校验区域标签与文本行对齐,最终形成包含348对TIFF图像与PAGE-XML标注文件的结构化数据集。
特点
该数据集在历史文献光学字符识别领域具有显著特征。其内容跨越三个世纪德语区出版文化,包含德语、拉丁语、法语等多语言文献,文本总量达48万余字符。数据结构严格遵循PRImA研究实验室开发的PAGE-XML标准,确保标注格式的规范性与互操作性。特别值得关注的是其样本选取策略:从65部著作各抽取4页,另两部著作分别抽取49页和39页,既保证文献类型的广泛覆盖,又兼顾OCR技术处理难点的代表性。
使用方法
该数据集主要服务于历史文献数字化研究中的光学字符识别任务。研究者可通过Zenodo平台获取数据包,其中包含按著作分列的目录结构,每个子目录均包含OCR-D-IMG图像文件夹与对应的XML标注文件。使用时应先通过配套的CSV映射表理解数据集标识与原始馆藏编号的对应关系,结合OCR-D项目提供的修复脚本进行数据预处理。由于未预设机器学习数据划分,建议用户根据具体研究需求先行分析文献特征,再制定适当的数据划分方案。
背景与挑战
背景概述
在文化遗产数字化研究领域,德国国家图书馆联合OCR-D项目于2025年推出OCR-D-GT-VD-SBB数据集,旨在构建十六至十八世纪德语区历史印刷品的精准标注资源。该数据集由柏林国家图书馆主导,得到德国研究基金会与文化媒体事务专员联合资助,涵盖348页来自《德意志语区印刷品目录》的手稿图像与转录文本。通过系统化采集1509至1827年间出版的67部著作,涵盖神学、法学、科学等多学科内容,该资源为古文书光学字符识别技术提供了关键训练基准,推动了数字人文研究中对多语言历史文献的自动化处理进程。
当前挑战
历史文献数字化面临字体变异、版面腐蚀与多语言混杂的核心难题,该数据集通过严格遵循PAGE-XML标注规范与99.95%字符级精度标准予以应对。在构建过程中,团队需克服早期印刷体连字符识别、拉丁语与古德语混合排版解析等技术障碍,同时通过脚本辅助修复区域标注不一致性问题。此外,从数万件馆藏中筛选代表性文献时,需平衡文档类型多样性与非标准版面结构对OCR模型的挑战,这一过程依赖专业文献学知识与人机协同的质控机制。
常用场景
经典使用场景
在历史文献数字化领域,OCR-D-GT-VD-SBB数据集作为光学字符识别技术的重要基准,其348页涵盖16至19世纪德语区出版物的高质量标注数据,为古籍数字化研究提供了标准化的评估框架。该数据集通过PAGE-XML格式的文本与图像对应文件,支持对多语言混合文本的识别模型训练,尤其适用于处理早期印刷品中常见的字体变形、版面复杂等挑战。
实际应用
在文化遗产保护实践中,该数据集被广泛应用于图书馆数字化工作流,支持对VD16/VD17/VD18等珍本目录的自动化文本提取。通过提供高精度标注样本,显著提升了历史文献全文检索系统的构建效率,使研究者能快速定位特定时期的学术著作。其标注规范更为其他机构建立同类数据集提供了可复用的技术标准。
衍生相关工作
基于该数据集衍生的研究已拓展至多模态文档分析领域,例如结合版面结构与文本内容的联合建模方法。在相关工作中,研究者利用其多语言标注特性开发了混合语言识别模型,并借鉴其质量控制流程优化了古籍数字化的标注标准。这些成果进一步推动了文化遗产计算领域的技术标准化进程。
以上内容由遇见数据集搜集并总结生成


