fineweb-c-combined-resample
收藏Hugging Face2025-09-14 更新2025-09-15 收录
下载链接:
https://huggingface.co/datasets/tartuNLP/fineweb-c-combined-resample
下载链接
链接失效反馈官方服务:
资源简介:
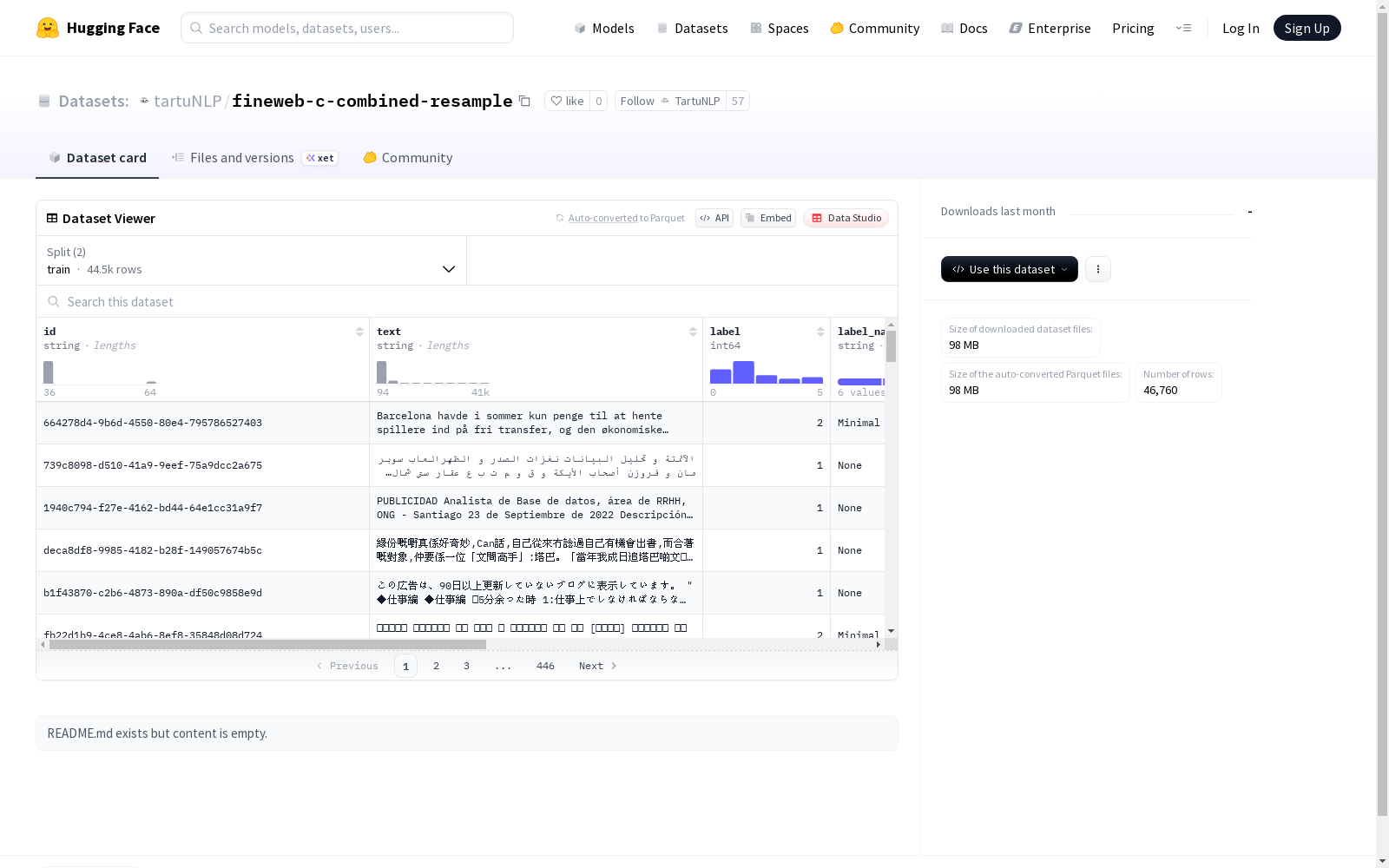
这是一个包含文本和标签的数据集,其中文本字段(text)存储了文本数据,标签字段(label)存储了相应的标签。数据集还包含了其他信息,如每个文本的ID(id)、标签名称(label_name)、预测概率(probs)、单词数量(n_tokens)、语言代码(language_code)、数据来源(source)和原始注释(original_annotation)。数据集分为训练集和验证集,可用于机器学习模型的训练和评估。
This is a dataset containing text and labels. The `text` field stores textual data, while the `label` field holds corresponding labels. Additionally, the dataset includes supplementary information for each text entry, including its ID (`id`), label name (`label_name`), prediction probability (`probs`), number of tokens (`n_tokens`), language code (`language_code`), data source (`source`), and original annotation (`original_annotation`). The dataset is split into a training set and a validation set, which can be utilized for training and evaluating machine learning models.
提供机构:
TartuNLP创建时间:
2025-09-14
原始信息汇总
FineWeb-C-Combined-Resample 数据集概述
数据集基本信息
- 数据集名称:FineWeb-C-Combined-Resample
- 下载大小:97.96 MB
- 数据集大小:170.76 MB
- 总样本数:46,760
数据特征
- id:字符串类型,样本唯一标识
- text:字符串类型,文本内容
- label:整型,类别标签
- label_name:字符串类型,类别名称
- probs:浮点数列表,概率分布
- n_tokens:整型,令牌数量
- language_code:字符串类型,语言代码
- source:字符串类型,数据来源
- original_annotation:字符串列表,原始标注
数据划分
- 训练集(train)
- 样本数量:44,547
- 数据大小:162.69 MB
- 开发集(dev)
- 样本数量:2,213
- 数据大小:8.07 MB
数据文件
- 训练集文件路径:
data/train-* - 开发集文件路径:
data/dev-*
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,大规模高质量数据集的构建对模型性能至关重要。fineweb-c-combined-resample数据集通过多源数据整合与重采样技术构建,原始文本经过严格的质量筛选和去重处理,每个样本均包含文本内容、语言标签及概率分布标注,并采用标准化流程进行特征提取和格式统一,最终形成包含训练集和开发集的完整语料库。
特点
该数据集具备多维特征标注体系,不仅包含原始文本和基础语言标签,还提供每个样本的概率分布向量和词汇数量统计,支持多语言文本处理任务。数据集样本规模适中且分布均衡,文本来源清晰可溯,标注信息丰富完整,为模型训练提供了高质量的监督信号和细粒度的语言特征表示。
使用方法
研究人员可直接加载数据集进行监督学习任务,利用文本字段作为输入特征,结合标签字段进行文本分类或质量评估模型训练。概率分布字段可用于不确定性建模或集成学习,语言代码和来源信息则支持多语言和跨域分析。建议按照标准训练-开发集划分进行模型验证,确保评估结果的可靠性。
背景与挑战
背景概述
随着大规模语言模型研究的深入,高质量训练数据的需求日益凸显。fineweb-c-combined-resample数据集应运而生,由专业研究机构基于CommonCrawl网络文本构建,专注于多语言文本分类任务。该数据集通过精密采样与标注技术,为自然语言处理领域提供了标准化评估基准,显著推动了文本分类模型的可解释性与泛化能力研究。其结构化特征设计体现了当代语言数据工程的前沿理念,成为语言智能发展的重要基础设施。
当前挑战
在文本分类领域,模型面临语义粒度划分与跨语言泛化的双重挑战,fineweb-c-combined-resample需解决标注一致性与噪声过滤问题。数据构建过程中,原始网络文本存在格式异构与语言混杂现象,需通过多轮清洗和概率标注确保质量。同时,平衡类别分布与保持文本语义完整性之间存在张力,需设计精密采样策略以兼顾数据多样性与分类任务需求。
常用场景
经典使用场景
在自然语言处理领域,fineweb-c-combined-resample数据集作为高质量文本语料库,主要应用于大规模语言模型的预训练任务。其多语言文本特征与精细化标注体系,为研究者提供了丰富的语义理解与生成训练素材,尤其在跨语言文本表征学习中展现出显著价值。该数据集通过结构化采样策略,有效支撑了Transformer架构下自监督学习的参数优化过程。
实际应用
实际应用中,该数据集服务于智能搜索引擎的语义匹配模块,通过其高质量文本训练的语言模型能精准理解多语言查询意图。在内容审核系统中,基于该数据集训练的模型可有效识别跨语言违规文本,其概率标注机制更为风险内容的分级处理提供了量化依据。此外,教育科技领域利用其多语言特性开发智能翻译辅助工具。
衍生相关工作
基于该数据集衍生的经典工作包括多语言BERT的扩展训练框架XLM-R,其利用数据集的跨语言特性实现了零样本迁移突破。后续研究如mT5多任务预训练模型同样借鉴了其重采样策略,在机器翻译与文本生成任务中取得了显著进展。近期出现的跨语言对比学习框架CoCoLM,亦通过该数据集的概率标注实现了更精细的语义对齐。
以上内容由遇见数据集搜集并总结生成


