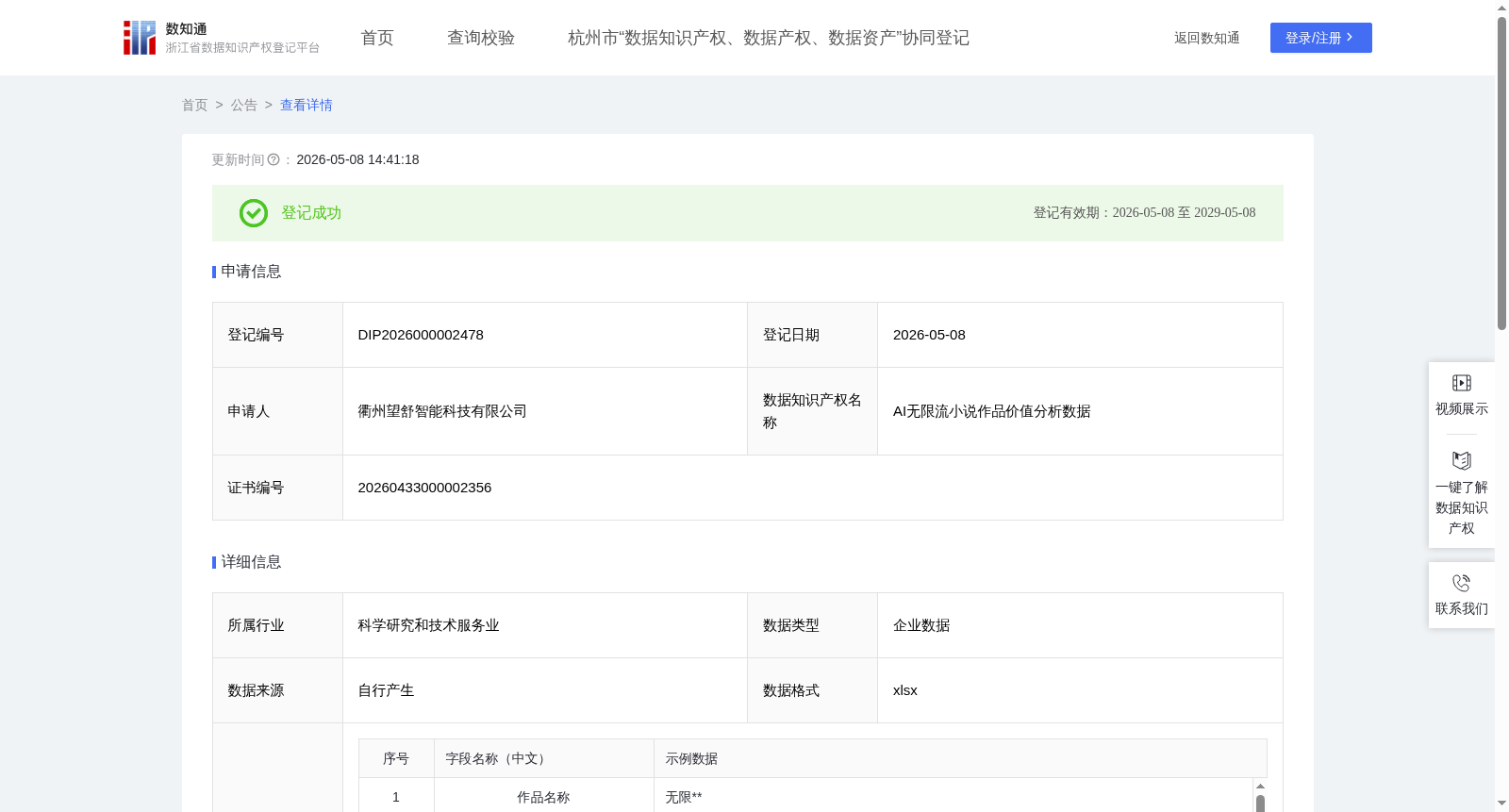
AI无限流小说作品价值分析数据
收藏浙江省数据知识产权登记平台2026-05-08 更新2026-05-09 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8441515
下载链接
链接失效反馈官方服务:
资源简介:
通过分析AI生成的无限流小说在各平台上的阅读数据,构建综合评分模型,对作品的章节触底率、加入书架情况、付费转化收益以及副本吸引力进行深度量化分析,将数据洞察直接反馈到AI创作系统的优化升级中。通过解析高评分无限流作品的特征模式,训练AI学习优质无限流小说的叙事结构(如副本嵌套、主神空间规则、能力成长线与世界观拓展)、节奏把控(危机爆发与喘息间隔的频率、任务推进与奖励释放的节奏)和反转设置技巧(如副本结局反转、队友身份揭露、规则漏洞利用),提升生成内容的质量;其次,针对不同平台读者的偏好差异,调整AI的创作参数,实现题材细分(恐怖副本、科幻副本、武侠副本、生存竞技等)、文风(紧张刺激、冷静算计或热血战斗)和章节长度的自适应优化;同时,利用评分模型为AI创作系统建立效果评估体系,对比不同算法版本生成的无限流内容在副本创新性、逻辑自洽性及生存紧张感等方面的市场表现,驱动核心技术迭代;最终,这套数据驱动的智能创作系统能够持续产出更符合市场需求、更具商业价值的AI无限流小说,降低试错成本,提升内容产能与竞争力,实现从数据洞察到无限流创作优化的价值闭环。加工前的数据说明:本次分析采集2026年1月13日之前公司悬疑小说创作者在各个平台上发布作品的数据,数据从每一位作者的后台收集而来,字段包括:作品名称、统计时间、发布平台、作者、字数、阅读量、加入书架量、15秒阅读人数/人、30秒阅读人数/人、60秒阅读人数/人、触底人数/人、收益/元、小说类型,数据按需进行更新,总计有1074条数据。其中阅读量表示阅读这本小说的总人数;15/30/60秒阅读人数表示用户点进小说阅读的时间;触底人数表示阅读完整本小说的人数;收益表示这本小说上架后产生的整体收益。
处理规则:数据清洗,对缺失值进行删除,去除异常值影响,对作品名称和作者信息进行匿名处理,用*表示;消除时间影响:计算触底率=触底人数/阅读量,表示阅读完这本小说的人占阅读本书人数的比例;入架率=加入书架量/阅读量,表示阅读这本小说的人将书加入书架的数量;人均阅读收益=收益/阅读量,消除时间影响,表示阅读这本小说的人平均对这本书的产生的费用;开篇吸引力=触底人数/60秒阅读人数,表示阅读完60秒之后,还愿意将整本书读完的概率,体现小说的吸引力。标准化处理:由于触底率、入架率、人均阅读收益、开篇吸引力所表示的量纲不同,进行标准化处理。标准化触底率=(单次触底率-min(触底率))/(max(触底率)-min(触底率)),其他三个维度的指标都按照这个公式进行处理,分别储存在标准化入架率、标准化人均阅读收益、标准化开篇吸引力字段当中。
数据内容:根据加权评价模型计算AI悬疑小说作品价值得分 = 标准化悬念章节留存率 × 0.35 + 标准化加入书架率 × 0.25 + 标准化人均阅读收益 × 0.3 + 标准化开篇悬念指数 × 0.1。这种量化评估体系使AI悬疑创作从主观经验判断转向数据驱动优化,持续提升生成内容的市场竞争力与读者沉浸感。
提供机构:
衢州望舒智能科技有限公司
创建时间:
2026-04-08
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集记录了1074条AI无限流小说在各平台(如七猫小说)上的阅读表现数据,包含作品名称、字数、阅读量、触底率、入架率、收益等22个字段。通过加权评分模型计算作品价值得分(维度包括标准化触底率、入架率等),旨在量化分析小说吸引力与商业潜力,并将洞察反馈至AI创作系统,优化叙事结构与市场适应性,形成从数据到创作升级的价值闭环。
以上内容由遇见数据集搜集并总结生成


