fishkinet-posts
收藏Hugging Face2024-08-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nyuuzyou/fishkinet-posts
下载链接
链接失效反馈官方服务:
资源简介:
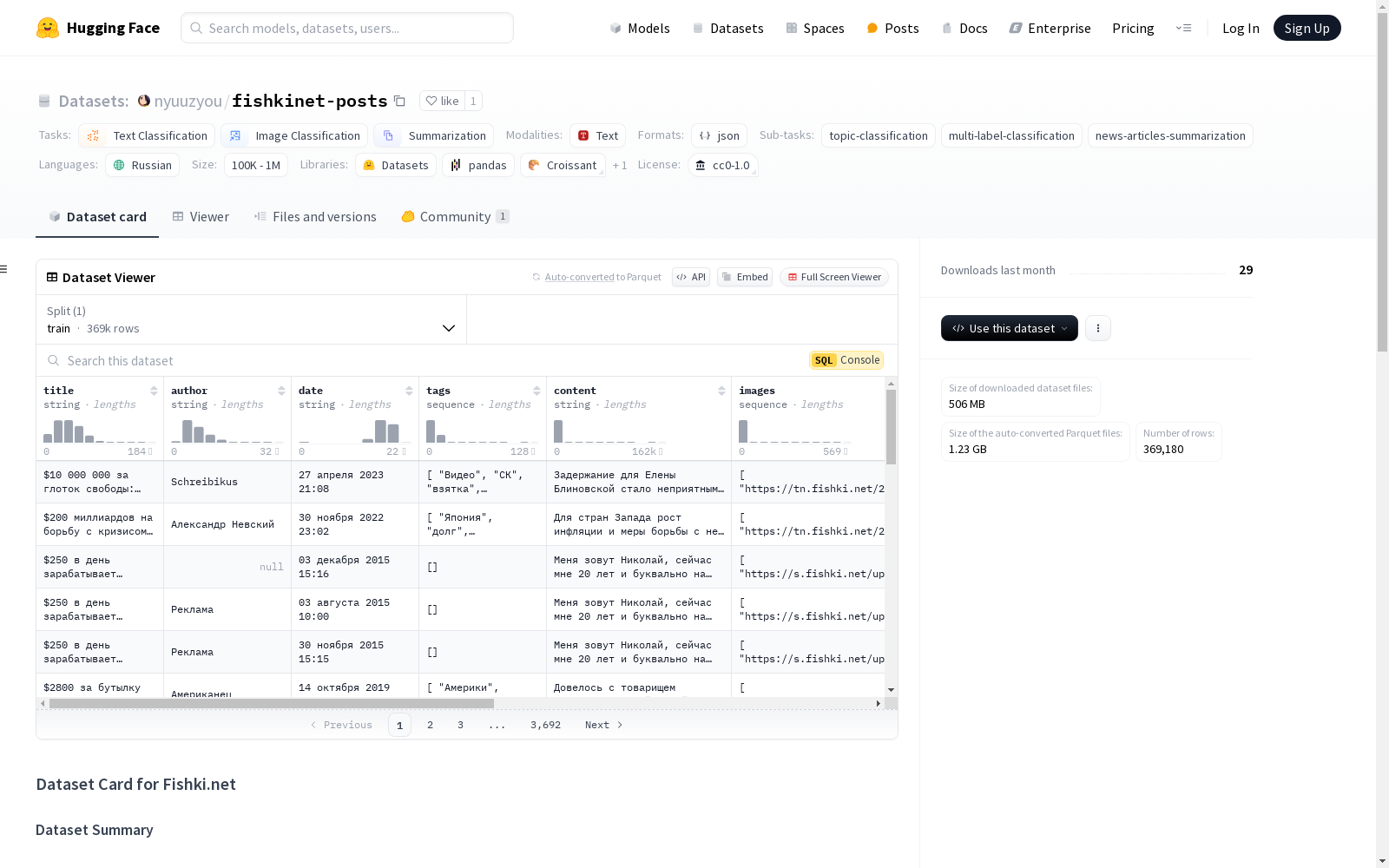
该数据集包含从俄罗斯娱乐和新闻网站Fishki.net抓取的帖子。每个条目代表网站上的一个帖子,包括标题、内容、作者、发布日期、标签、图片和URL。数据集包含369,180个独特的帖子,涵盖娱乐、新闻和社会媒体内容的各个主题。数据集主要使用俄语,适用于文本分类、图像分类和摘要生成等任务。该数据集采用CC0许可,允许无限制使用。
This dataset comprises posts scraped from the Russian entertainment and news website Fishki.net. Each entry corresponds to a single post on the platform, including its title, content, author, publication date, tags, images, and URL. The dataset contains 369,180 unique posts covering a wide range of topics across entertainment, news, and social media content. Primarily written in Russian, this dataset is suitable for tasks such as text classification, image classification, and abstractive summarization. It is released under the CC0 license, permitting unrestricted use.
创建时间:
2024-08-24
原始信息汇总
数据集卡片 - Fishki.net
数据集概述
该数据集包含从Fishki.net抓取的帖子,这是一个俄罗斯娱乐和新闻网站。每个条目代表网站上的一个帖子,包括标题、内容、作者、发布日期、标签、图片和URL。数据集包含369,180个独特的帖子,涵盖娱乐、新闻和社交媒体内容的各个主题。
语言
数据集主要使用俄语。
数据集结构
数据字段
该数据集包括以下字段:
url:帖子的URL(字符串)title:帖子的标题(字符串)author:帖子的作者(字符串)date:帖子的发布日期(字符串)tags:与帖子关联的标签列表(字符串列表)content:帖子的主要内容(字符串)images:与帖子关联的图片URL列表(字符串列表)comments:帖子的评论列表(列表,目前在示例中为空)
数据分割
所有示例都在一个分割中。
附加信息
许可证
该数据集根据Creative Commons Zero (CC0) 许可证公开到公共领域。这意味着您可以:
- 将其用于任何目的,包括商业项目。
- 随意修改。
- 无需请求许可即可分发。
不需要署名,但总是受到欢迎!
CC0许可证:https://creativecommons.org/publicdomain/zero/1.0/deed.en
要了解更多关于CC0的信息,请访问Creative Commons网站:https://creativecommons.org/publicdomain/zero/1.0/
数据集策展人
搜集汇总
数据集介绍
构建方式
Fishki.net Posts数据集通过从俄罗斯娱乐和新闻网站Fishki.net抓取数据构建而成。该数据集包含了369,180个独特的帖子,涵盖了娱乐、新闻和社交媒体内容的多个主题。每个帖子条目包括标题、内容、作者、发布日期、标签、图片和URL等信息。数据的抓取过程确保了信息的完整性和多样性,为研究者提供了丰富的文本和图像资源。
特点
Fishki.net Posts数据集以其广泛的覆盖范围和多样化的内容著称。数据集中的帖子不仅包含文本信息,还附带了相关的图片和评论,形成了一个多模态的数据集合。此外,数据集的俄语特性为研究俄语自然语言处理任务提供了宝贵的资源。每个帖子都带有详细的元数据,如作者、发布日期和标签,这些信息为数据分析和分类任务提供了丰富的上下文。
使用方法
Fishki.net Posts数据集适用于多种自然语言处理和计算机视觉任务,如文本分类、多标签分类和新闻摘要生成。研究者可以利用该数据集进行俄语文本的分析和处理,探索多模态数据(文本与图像)的联合应用。数据集的结构清晰,字段包括URL、标题、作者、日期、标签、内容、图片和评论,便于直接加载和使用。由于数据集采用CC0许可证,用户可以自由地用于商业或非商业项目,无需担心版权问题。
背景与挑战
背景概述
Fishki.net Posts数据集源自俄罗斯娱乐与新闻网站Fishki.net,由用户nyuuzyou于2023年构建并发布。该数据集包含369,180条独特的帖子,涵盖了娱乐、新闻和社交媒体内容等多个主题。每条记录包括标题、内容、作者、发布日期、标签、图片及URL等信息。作为俄语单语数据集,Fishki.net Posts为文本分类、图像分类和摘要生成等任务提供了丰富的多模态数据资源。该数据集的发布填补了俄语多任务学习领域的数据空白,为自然语言处理和计算机视觉研究提供了重要的实验基础。
当前挑战
Fishki.net Posts数据集在构建与应用过程中面临多重挑战。首先,数据来源的多样性与复杂性使得数据清洗与预处理成为关键难题,尤其是俄语文本的语法结构与语义理解对模型提出了较高要求。其次,多标签分类任务中,标签的多样性与不平衡性增加了模型的训练难度。此外,图像分类任务中,图片质量参差不齐且与文本内容的关联性较弱,这对多模态模型的融合能力提出了更高要求。最后,数据集的规模虽大,但其领域覆盖范围有限,可能限制了模型在更广泛场景下的泛化能力。
常用场景
经典使用场景
Fishki.net Posts数据集广泛应用于文本分类、图像分类以及新闻摘要生成等任务。由于其包含大量俄语娱乐和新闻内容,研究人员常利用该数据集进行多标签分类和主题分类实验,以探索俄语文本的语义特征和分类模型的表现。此外,数据集中的图像和文本结合也为多模态学习提供了丰富的实验素材。
实际应用
在实际应用中,Fishki.net Posts数据集可用于构建俄语新闻推荐系统、社交媒体内容分析工具以及多模态内容生成平台。例如,新闻机构可以利用该数据集训练模型,自动生成新闻摘要或分类新闻主题,从而提高内容分发的效率。此外,娱乐平台也可通过分析用户对特定标签的偏好,优化内容推荐算法。
衍生相关工作
基于Fishki.net Posts数据集,研究人员已开展了多项经典工作,包括俄语文本分类模型的优化、多模态学习框架的开发以及新闻摘要生成算法的改进。这些工作不仅提升了俄语NLP领域的技术水平,也为其他语言的多模态数据处理提供了参考。例如,一些研究利用该数据集探索了文本与图像的联合表示学习方法,为跨模态内容理解开辟了新的研究方向。
以上内容由遇见数据集搜集并总结生成


