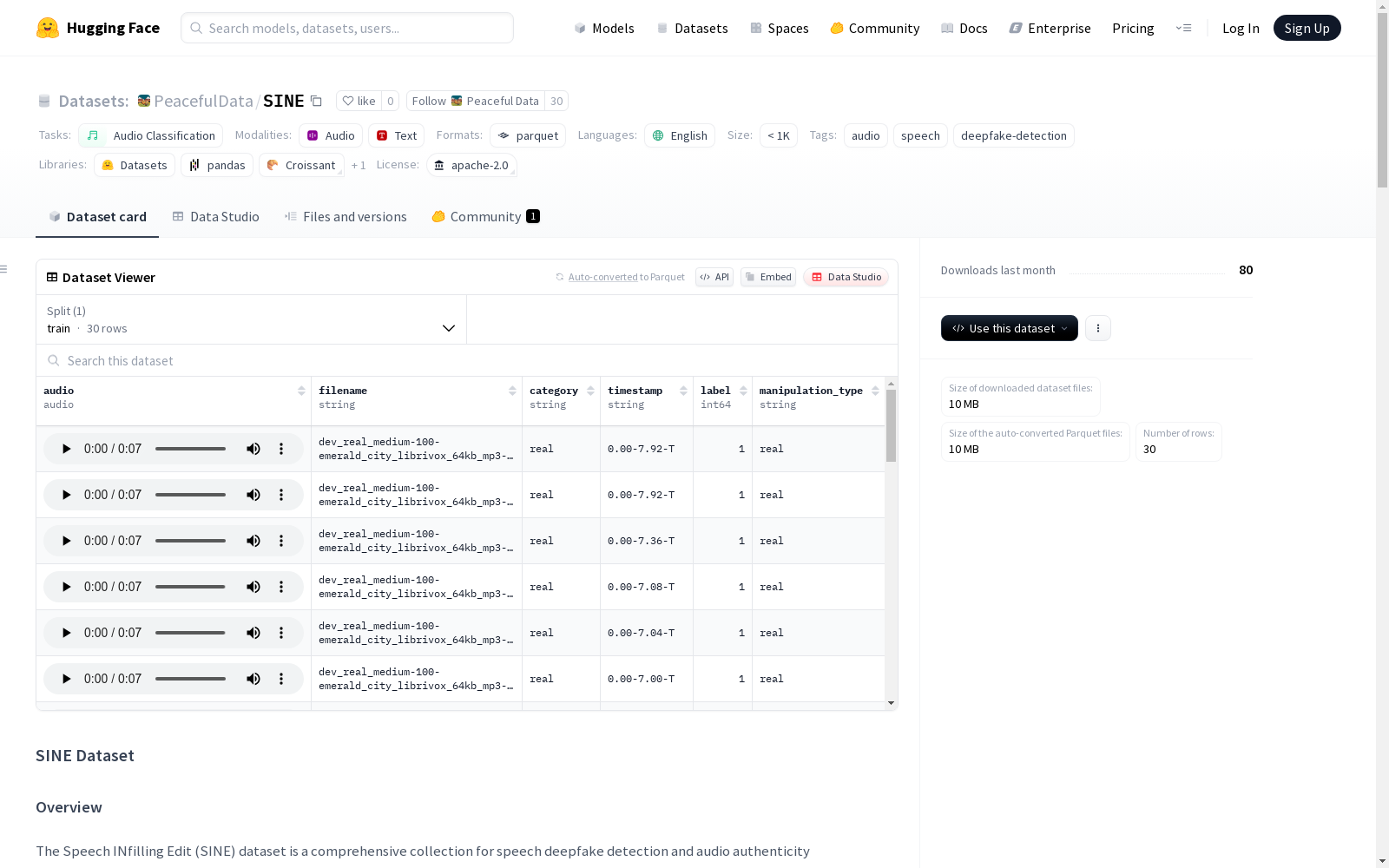
SINE
收藏SINE数据集概述
基本信息
- 语言:英语
- 许可证:Apache 2.0
- 数据规模:10K<n<100K
- 任务类型:音频分类
- 标签:音频、语音、深度伪造检测
- 数据集名称:SINE: Speech INfilling Edit Dataset
数据集详情
- 配置名称:preview
- 特征:
- audio:音频,采样率16000Hz
- filename:文件名,字符串类型
- category:类别,字符串类型
- timestamp:时间戳,字符串类型
- label:标签,int64类型
- manipulation_type:操作类型,字符串类型
- 数据分割:
- train:10,309,938字节,30个样本
- 下载大小:10,039,423字节
- 数据集大小:10,309,938字节
数据集统计
- 总大小:约87GB
- 分割数量:32个(split-0.tar.gz到split-31.tar.gz)
- 音频格式:WAV文件
- 来源:基于LibriLight数据集的语音编辑,转录文本来自LibriHeavy
音频统计
| 音频类型 | 子集 | 样本数 | 说话人数 | 时长(h) | 音频长度(s) |
|---|---|---|---|---|---|
| Real/Resyn | train | 26,547 | 70 | 51.82 | 6.00-8.00 |
| Real/Resyn | val | 8,676 | 100 | 16.98 | 6.00-8.00 |
| Real/Resyn | test | 8,494 | 900 | 16.60 | 6.00-8.00 |
| Infill/CaP | train | 26,546 | 70 | 51.98 | 5.40-9.08 |
| Infill/CaP | val | 8,686 | 100 | 16.99 | 5.45-8.76 |
| Infill/CaP | test | 8,493 | 903 | 16.64 | 5.49-8.85 |
数据结构
每个分割(如split-0/)包含:
split-X/ ├── combine/ # 包含所有音频文件的目录(约11,076个文件) │ ├── dev_real_medium-.wav # 真实音频样本 │ ├── dev_edit_medium-.wav # 编辑音频样本 │ ├── dev_cut_paste_medium-.wav # 剪切粘贴操作样本 │ └── dev_resyn_medium-.wav # 重新合成音频样本 ├── medium_real.txt # 真实音频标签(2,769个条目) ├── medium_edit.txt # 编辑音频标签(2,769个条目) ├── medium_cut_paste.txt # 剪切粘贴音频标签(2,769个条目) └── medium_resyn.txt # 重新合成音频标签(2,769个条目)
音频类别
-
真实语音(
dev_real_medium-*)- 原始未修改的语音录音
- 标签为
1(真实) - 简单时间注释格式:
filename start-end-T label
-
重新合成语音(
dev_resyn_medium-*)- 使用HiFi-GAN声码器从梅尔频谱图重新生成的语音
- 标签为
1(真实) - 简单时间注释格式
-
编辑语音(
dev_edit_medium-*)- 经过人工修改/编辑的音频样本
- 标签为
0(操作) - 复杂时间注释,包含真实/伪造部分
-
剪切粘贴语音(
dev_cut_paste_medium-*)- 通过剪切和粘贴不同来源的片段创建的音频
- 标签为
0(操作) - 复杂时间注释,显示拼接片段
标签格式
简单格式(Real/Resyn)
filename start_time-end_time-T label
示例:
dev_real_medium-100-emerald_city_librivox_64kb_mp3-emeraldcity_02_baum_64kb_21 0.00-7.92-T 1
复杂格式(Edit/Cut-Paste)
filename time_segment1-T/time_segment2-F/time_segment3-T label
示例:
dev_edit_medium-100-emerald_city_librivox_64kb_mp3-emeraldcity_02_baum_64kb_21 0.00-4.89-T/4.89-5.19-F/5.19-8.01-T 0
T= 真实片段F= 伪造片段label:1= 真实,0= 操作
应用场景
- 语音深度伪造检测:真实与操作语音的二元分类
- 时间定位:识别包含操作的特定时间段
- 操作类型分类:区分不同类型的音频操作
- 鲁棒性测试:评估检测系统在不同操作技术上的表现
引用
bibtex @inproceedings{huang2024detecting, title={Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits}, author={Huang, Sung-Feng and Kuo, Heng-Cheng and Chen, Zhehuai and Yang, Xuesong and Yang, Chao-Han Huck and Tsao, Yu and Wang, Yu-Chiang Frank and Lee, Hung-yi and Fu, Szu-Wei}, booktitle={2024 IEEE Spoken Language Technology Workshop (SLT)}, pages={652--659}, year={2024}, organization={IEEE} }
许可证
Apache 2.0许可证