code-contests-plus-verl
收藏Hugging Face2025-11-05 更新2025-11-06 收录
下载链接:
https://huggingface.co/datasets/sungyub/code-contests-plus-verl
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了8,432个从Code-Contests-Plus数据集转换成VERL格式的编程竞赛问题,用于强化学习应用。每个问题都包括通过沙盒执行验证的测试用例。
This dataset contains 8,432 programming contest problems converted from the Code-Contests-Plus dataset into the VERL format, intended for reinforcement learning applications. Each problem includes test cases validated via sandbox execution.
创建时间:
2025-11-03
原始信息汇总
Code Contests Plus (VERL Format) 数据集概述
数据集基本信息
- 数据源:ByteDance-Seed/Code-Contests-Plus (1x配置)
- 数据量:8,432个竞争性编程问题
- 格式:VERL格式(用于强化学习应用)
- 许可证:MIT
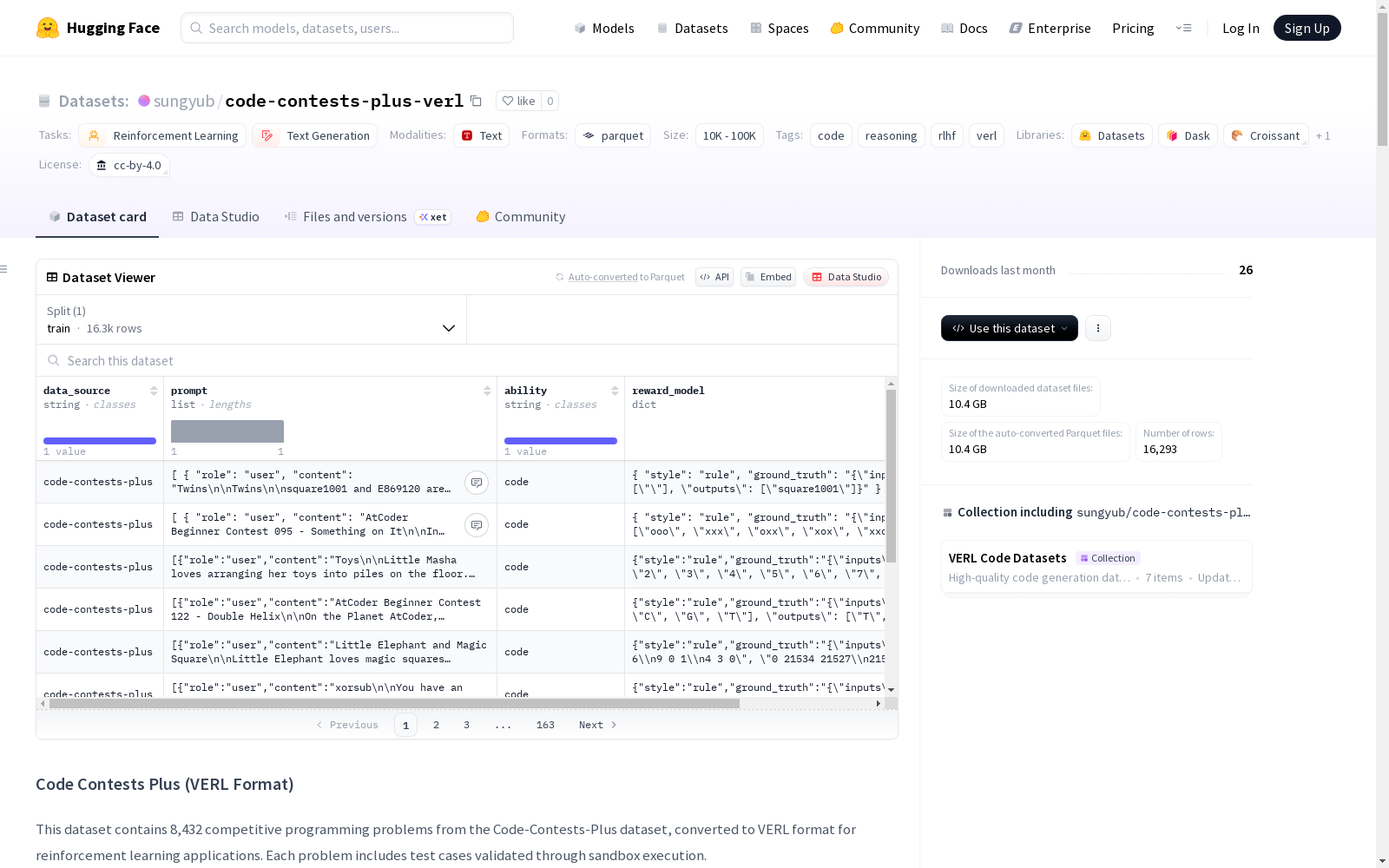
数据结构
- data_source:数据集源标识符("code-contests-plus")
- prompt:包含编程问题的聊天模板格式(角色/内容结构)
- ability:任务类别("code")
- reward_model:评估信息
- style:评估方法("rule")
- ground_truth:JSON编码的输入/输出对测试用例
- extra_info:附加元数据
- index:原始数据集中的示例索引
测试用例格式
json { "inputs": ["3 1 2 3 "], "outputs": ["6 "] }
- 包含两个并行数组:inputs(输入字符串数组)和outputs(预期输出字符串数组)
- 每个问题包含1-32个测试用例
- 在数据集创建过程中通过沙箱执行验证
数据处理统计
- 总输入示例:11,690
- 成功处理:8,432(72.1%成功率)
- 总过滤:3,258(27.9%)
- 无测试用例:54(0.5%)
- 大小过滤(>10MB):3,204(27.4%)
- 处理时间:69分钟
数据集规格
- 总示例数:8,432
- 平均测试用例数:约10-15个/问题
- 测试用例范围:1-32个/问题
- 数据集大小:约10GB(未压缩),约10GB(压缩)
- 格式:Parquet(11个分片,每个约1GB)
- 数据拆分:训练集(8,432个示例)
数据质量保证
- 有效测试用例:每个问题至少有一个有效测试用例
- 正确输入/输出对:通过沙箱执行验证测试用例
- 大小约束:测试用例在合理大小限制内(≤10MB)
- 格式一致性:所有示例遵循相同的模式结构
相关数据集
- Code Contests Plus (Original):https://huggingface.co/datasets/ByteDance-Seed/Code-Contests-Plus
- Skywork-OR1-Code-VERL:https://huggingface.co/datasets/sungyub/skywork-or1-code-verl
搜集汇总
数据集介绍
构建方式
在编程竞赛领域,该数据集通过严谨的多阶段处理流程构建而成。从原始数据集中提取公开测试用例后,采用沙箱环境对每个问题的输入输出对进行验证,确保其可执行性与正确性。通过设定10MB的JSON编码大小限制,有效过滤了规模过大的问题,最终从11690个初始样本中筛选出8432个高质量编程问题,成功率达到72.1%。
特点
该数据集以VERL格式精心组织,每个样本包含结构化的提示模板与评估信息。其独特之处在于每个编程问题均配备经过沙箱验证的测试用例,这些测试用例以JSON格式存储输入输出对,数量范围控制在1至32个之间。数据集涵盖8432个竞技编程问题,采用分片存储机制,11个分片各约1GB,总容量达10GB,为强化学习研究提供了标准化的数据基础。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,利用标准接口获取编程问题描述与测试用例。具体操作时,从提示字段解析问题陈述,通过反序列化奖励模型中的地面真值字段获取验证数据。该设计支持批量处理与流式读取,便于集成到强化学习训练流程中,为代码生成模型的评估与优化提供完整的数据支撑。
背景与挑战
背景概述
在人工智能编程辅助研究领域,code-contests-plus-verl数据集由ByteDance-Seed团队于2024年构建,旨在为强化学习场景提供结构化编程问题资源。该数据集源自经典编程竞赛题库,通过VERL标准化格式重构了8432道经过沙箱验证的题目,每条数据包含完整的题目描述、测试用例及评估框架。其核心价值在于将传统编程问题转化为适合策略优化的交互环境,为代码生成模型的奖励机制设计提供了重要基准,显著推进了智能编程助手在复杂逻辑推理方向的发展进程。
当前挑战
构建过程中面临测试用例完整性与执行验证的双重挑战:原始题库中27.9%的样本因缺失有效测试用例或数据体积超限被过滤,需通过沙箱环境逐条验证输入输出对的有效性。领域层面需解决编程问题的形式化表示难题,既要保持自然语言描述的语义完整性,又需确保测试用例能精准映射到强化学习的奖励信号。数据规模与质量平衡亦构成关键制约,10MB的编码体积限制虽保障了处理效率,但可能损失部分具有复杂边界条件的典型题目。
常用场景
经典使用场景
在强化学习驱动的代码生成领域,该数据集通过精心设计的VERL格式为智能体训练提供了标准化环境。其核心价值在于将8432个竞技编程问题转化为包含沙盒验证测试用例的交互式任务,使得模型能够通过试错机制学习算法逻辑与代码规范。每个问题配备的输入输出对构成了动态奖励信号,为策略优化奠定了数据基础。
衍生相关工作
该数据集的发布催生了多项代码智能领域的创新研究。基于其VERL格式构建的强化学习框架已在代码修复、算法优化等方向取得突破,相关成果发表于顶级学术会议。与Skywork-OR1-Code-VERL等姊妹数据集的协同发展,共同推动了面向复杂编程任务的智能体训练范式演进,形成了代码强化学习领域的重要技术脉络。
数据集最近研究
最新研究方向
在代码生成与强化学习交叉领域,code-contests-plus-verl数据集正推动着程序合成技术的革新。该数据集将8432个竞技编程问题转化为VERL格式,为基于人类反馈的强化学习提供了结构化训练基础。前沿研究聚焦于利用其沙盒验证的测试用例构建高效奖励模型,探索多模态推理与代码生成的协同优化。随着大语言模型在编程任务中的广泛应用,此类数据集成为评估模型逻辑严谨性与泛化能力的关键基准,显著促进了自主代码生成系统在复杂算法场景下的稳健发展。
以上内容由遇见数据集搜集并总结生成


