HistoryTrans/Dataset
收藏Hugging Face2024-01-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/HistoryTrans/Dataset
下载链接
链接失效反馈官方服务:
资源简介:
HistoryTrans 是一个古文翻译数据集,旨在通过数据预处理和质量控制提高古文翻译的质量和实用性。数据集来源包括Classical-Modern项目以及《二十四史》和《清史稿》的提取内容。数据集结构包含训练集、验证集和测试集,每个JSON对象包括原始古文和准确翻译。
HistoryTrans is a classical Chinese translation dataset aimed at enhancing the quality and practicality of classical Chinese translation via data preprocessing and quality control. The dataset is sourced from the Classical-Modern Project and extracted content from *Twenty-Four Histories* and *Draft History of Qing*. The dataset structure consists of training, validation, and test sets, with each JSON object containing the original classical Chinese text and its accurate translation.
提供机构:
HistoryTrans
原始信息汇总
古文翻译数据集
概述
HistoryTrans 是一个古文翻译数据集,旨在通过数据预处理和质量控制,提高古文翻译的质量和实用性。
数据集详细信息
数据集来源
- 主体: Classical-Modern
- 额外补充: 《二十四史》和《清史稿》中提取
数据集结构
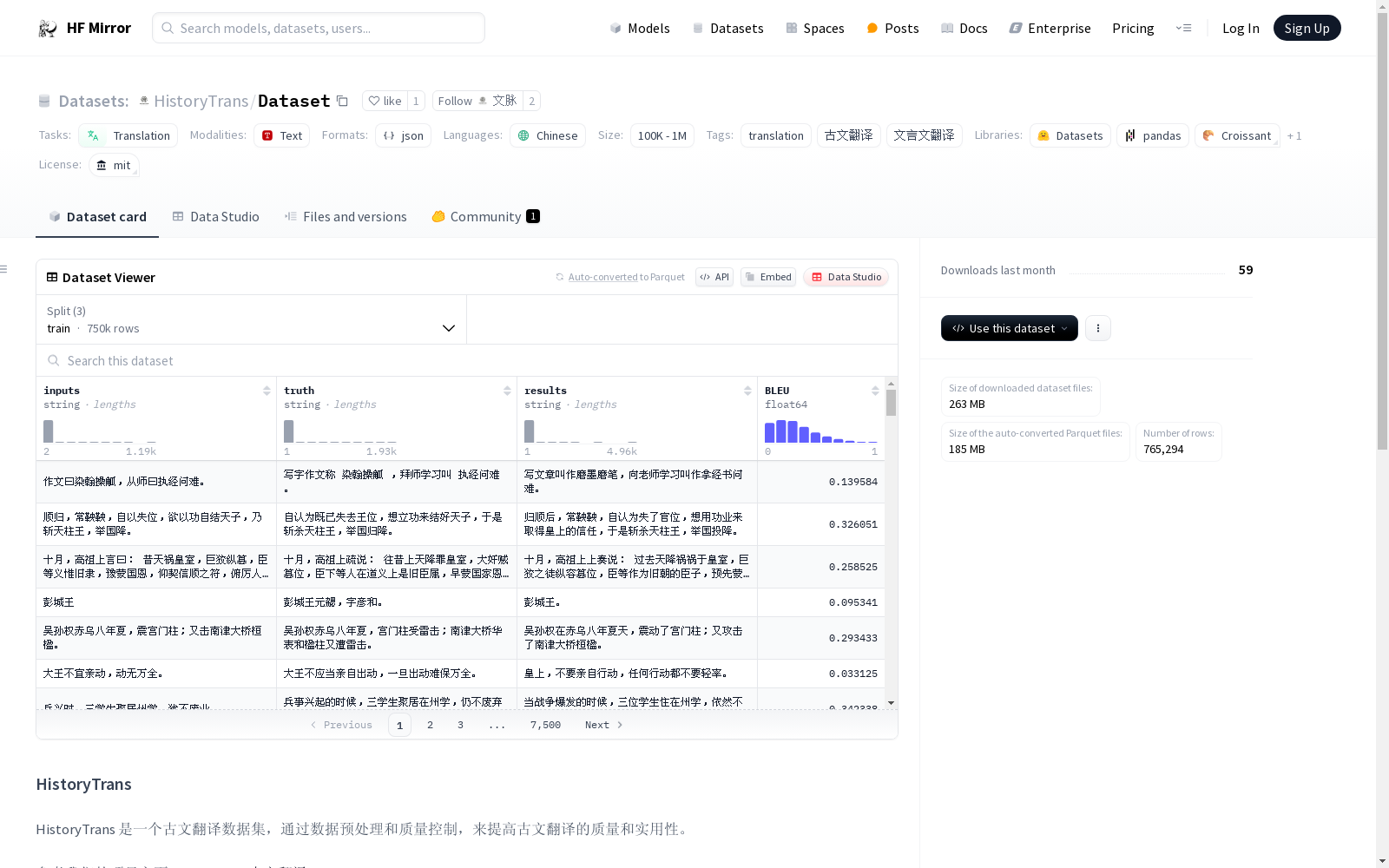
数据集包含以下 JSONL 文件:
train_01_04.jsonl: 训练集,主要用于训练翻译模型。val_01_04.jsonl: 验证集,用于训练过程中的模型微调和评估。test_01_04.jsonl: 测试集,用于评估最终模型性能。
每个 JSON 对象包括:
inputs: 原始古文truth: 准确翻译
示例
json {"inputs": "昕曰: 回纥之功,唐已报之矣。", "truth": "萧昕反驳说: 回纥的功劳,唐朝已经报答了。"} {"inputs": "然县令所犯在恩前,中人所犯在恩后。", "truth": "但是县令所犯罪过在施恩大赦之前,宦官所犯罪过在施恩赦免之后。"}
搜集汇总
数据集介绍
构建方式
HistoryTrans数据集的构建,以Classical-Modern数据集为主体,辅以《二十四史》和《清史稿》中的内容进行补充。数据经过精细的预处理和质量控制,确保了古文翻译的质量与实用性。数据集分为训练集、验证集和测试集,每个集合中的数据均以JSONL格式存储,包含原始古文和准确的现代文翻译。
使用方法
用户可以通过访问HistoryTrans项目主页获取数据集,根据具体的翻译任务,利用训练集进行模型训练,验证集进行模型微调和评估,最后使用测试集来评估模型的翻译性能。数据集的JSONL格式易于程序化处理,用户可以根据需要编写脚本以读取和解析数据。
背景与挑战
背景概述
HistoryTrans数据集,作为古文翻译领域的宝贵资源,诞生于对传统文化传承与现代语言技术结合的深切需求。该数据集由Classical-Modern项目主体构建,并汲取了《二十四史》及《清史稿》的丰富内容,旨在提升古文翻译的质量与实用性。自创建以来,HistoryTrans数据集在自然语言处理、历史文献数字化等领域产生了深远影响,为研究者和开发者提供了宝贵的资源。
当前挑战
在数据集构建过程中,研究者面临了诸多挑战。首先,古文的复杂性及多义性使得翻译任务充满困难,其次,确保数据的质量和一致性需要严谨的预处理和质量控制流程。此外,如何平衡数据集中古文与现代文的差异,以及如何客观评估翻译模型的性能,也是构建和利用该数据集时必须克服的关键挑战。
常用场景
经典使用场景
在人工智能领域,尤其是自然语言处理任务中,HistoryTrans数据集被广泛用于训练和评估古文翻译模型。该数据集凭借其丰富的样本资源,使得模型能够学习到古文与白话文之间的对应关系,从而实现高质量的翻译。
解决学术问题
HistoryTrans数据集解决了古文翻译中存在的语义理解和表达准确性问题,为学术界提供了宝贵的资源,推动了古文信息处理技术的发展。它对于理解古代文献、促进历史研究以及语言演变分析等均具有深远意义。
实际应用
在实际应用中,HistoryTrans数据集的应用场景广泛,如古籍数字化、在线教育平台、历史研究领域等,它极大地促进了古文资源的可获取性和利用率,为公众提供了便捷的学习与研究工具。
数据集最近研究
最新研究方向
在自然语言处理领域,古文翻译作为一项挑战性的任务,近年来备受关注。HistoryTrans数据集的构建,为该领域的研究提供了高质量的语料支持。目前,学者们正致力于探索结合深度学习技术的古文翻译方法,以提高翻译的准确性和流畅性。此数据集的最新研究方向聚焦于利用神经机器翻译技术,通过增强模型对古文语言特性的理解和表达,从而推动古文翻译研究的深入。这一研究不仅对文化遗产的保护和传承具有重要意义,也为现代汉语的发展提供了新的视角。
以上内容由遇见数据集搜集并总结生成


