face-od
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/ljnlonoljpiljm/face-od
下载链接
链接失效反馈官方服务:
资源简介:
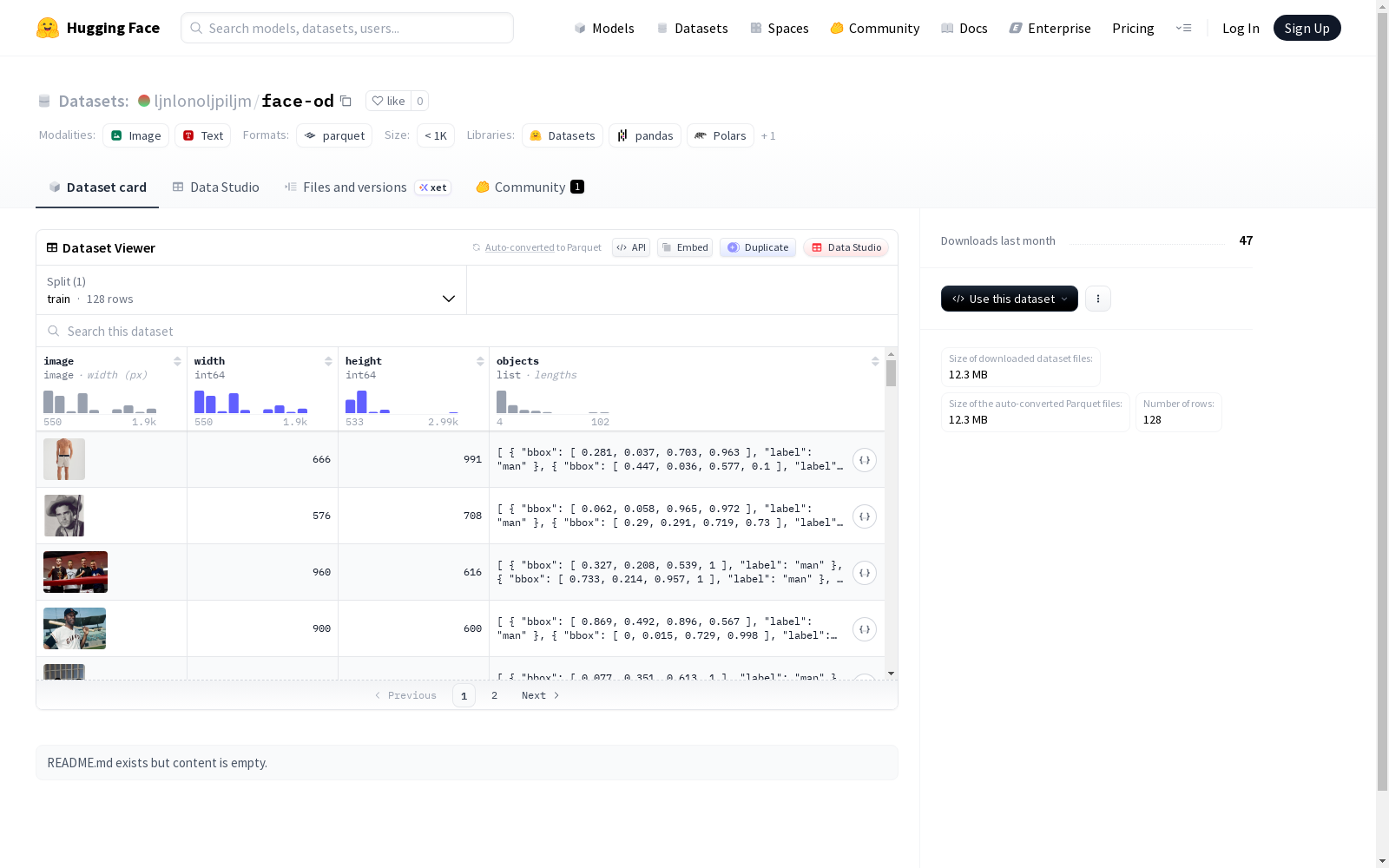
该数据集是一个包含图像及标注信息的计算机视觉数据集。主要特征包括:1) 图像数据(image字段);2) 图像宽高信息(width/height字段);3) 物体标注信息(objects字段),其中每个物体包含边界框坐标(bbox,浮点数列表)和类别标签(label,字符串类型)。数据集仅包含训练集(train split),共128个样本,总大小约12.4MB。数据文件存储格式为train-*的路径模式,适用于目标检测、图像识别等计算机视觉任务。
This dataset is a computer vision dataset containing images and their annotation information. Its main features include: 1) Image data stored in the `image` field; 2) Image width and height information stored in the `width` and `height` fields; 3) Object annotation information stored in the `objects` field, where each object contains bounding box coordinates (bbox, a list of floating-point numbers) and a category label (label, of string type). The dataset only includes the training split, with a total of 128 samples and an approximate total size of 12.4 MB. The data files follow the path pattern of `train-*`, and it is suitable for computer vision tasks such as object detection and image recognition.
创建时间:
2026-02-11
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称:face-od
- 托管平台:Hugging Face Datasets
- 数据集地址:https://huggingface.co/datasets/ljnlonoljpiljm/face-od
数据内容与结构
- 数据类型:图像数据集,包含目标检测标注信息。
- 数据特征:
image:图像数据,格式为image。width:图像宽度,数据类型为int64。height:图像高度,数据类型为int64。objects:目标对象列表,每个对象包含:bbox:边界框坐标列表,数据类型为float64。label:目标标签,数据类型为string。
数据集划分与规模
- 数据划分:仅包含训练集(
train)。 - 训练集规模:128个样本。
- 训练集大小:约12.44 MB(12,436,989字节)。
- 下载大小:约12.27 MB(12,272,038字节)。
- 数据集总大小:约12.44 MB(12,436,989字节)。
配置信息
- 默认配置名称:
default。 - 数据文件路径:
data/train-*。
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,人脸检测数据集对于推动目标检测算法的进步至关重要。face-od数据集的构建过程体现了系统化的数据采集与标注方法,其核心在于通过精心设计的流程收集图像样本,并采用边界框标注技术对图像中的人脸目标进行精确标记。每张图像均附带宽度与高度信息,确保空间维度的准确性,同时标注对象包含边界框坐标及对应的类别标签,形成了结构化的目标检测数据格式。这种构建方式不仅保证了数据的规范性与一致性,也为后续的模型训练提供了可靠的基础。
特点
face-od数据集展现出若干显著特点,使其在目标检测研究中具有独特价值。数据集以图像为主要载体,每张图像均包含详细的元数据,如宽度与高度,这有助于算法在处理时保持原始比例。标注信息以对象列表形式组织,每个对象涵盖浮点型边界框坐标和字符串型类别标签,支持多目标检测任务。数据规模适中,包含128个训练样本,文件大小约12.4MB,便于快速加载与实验。整体结构清晰,特征定义明确,为研究人员提供了高效且易于使用的视觉数据资源。
使用方法
使用face-od数据集时,研究人员可遵循标准的目标检测工作流程。数据集以HuggingFace平台兼容的格式提供,用户可通过配置默认设置直接加载训练分割,路径指向data/train-*文件。加载后,数据以图像与标注对象的形式呈现,其中标注包含边界框和标签,便于直接用于模型输入。由于数据集规模较小,适合用于快速原型验证、算法调试或教学演示。在实际应用中,用户可结合深度学习框架,如PyTorch或TensorFlow,将数据转换为张量格式,进而训练或评估人脸检测模型,推动相关技术的实践探索。
背景与挑战
背景概述
人脸检测作为计算机视觉领域的基础任务,其发展历程与数据集构建紧密相连。face-od数据集应运而生,旨在提供精确标注的人脸边界框数据,以支持目标检测模型的训练与评估。该数据集由相关研究团队构建,聚焦于解决复杂场景下的人脸定位与识别问题,其创建反映了学术界对提升模型鲁棒性与泛化能力的持续追求。通过提供结构化的图像与标注信息,face-od为后续研究奠定了数据基础,推动了人脸分析技术在安防、人机交互等领域的应用进展。
当前挑战
人脸检测领域面临多重挑战,包括遮挡、光照变化、姿态多样性以及小尺度人脸识别等难题,这些因素直接影响模型的准确性与可靠性。在构建face-od数据集过程中,研究人员需应对数据采集的多样性需求,确保样本涵盖不同环境、人群与场景;同时,标注工作涉及高精度边界框的定义,要求处理模糊边界或部分可见人脸的复杂情况,这对标注一致性与质量提出了严格要求。此外,数据平衡与隐私保护也是构建过程中不可忽视的挑战。
常用场景
经典使用场景
在计算机视觉领域,face-od数据集作为人脸检测任务的基准资源,其经典使用场景聚焦于训练和评估目标检测模型。该数据集包含标注精确的人脸边界框与标签,使得研究人员能够系统地探索人脸定位与识别算法。通过利用这些标注数据,模型可以学习从复杂背景中准确检测并框定人脸区域,为后续的人脸分析任务奠定基础。
解决学术问题
face-od数据集主要解决了人脸检测中因遮挡、光照变化或姿态多样性导致的模型鲁棒性不足问题。它提供了多样化的样本,有助于推动算法在真实世界场景下的泛化能力研究。该数据集的意义在于为学术界建立了标准化的评估框架,促进了人脸检测技术的量化比较与理论进展,对提升自动化视觉系统的可靠性具有深远影响。
衍生相关工作
围绕face-od数据集,衍生了一系列经典研究工作,包括基于深度学习的人脸检测器优化、多尺度检测框架设计以及轻量化模型部署策略。这些工作不仅提升了检测精度与速度,还促进了如YOLO、SSD等通用目标检测算法在人脸特定任务上的适配与创新。相关成果进一步推动了人脸分析技术的整体发展,为后续大规模数据集构建与应用拓展提供了理论借鉴。
以上内容由遇见数据集搜集并总结生成


