snigenigmatic/math500-bon-qwen2.5-1.5b
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/snigenigmatic/math500-bon-qwen2.5-1.5b
下载链接
链接失效反馈官方服务:
资源简介:
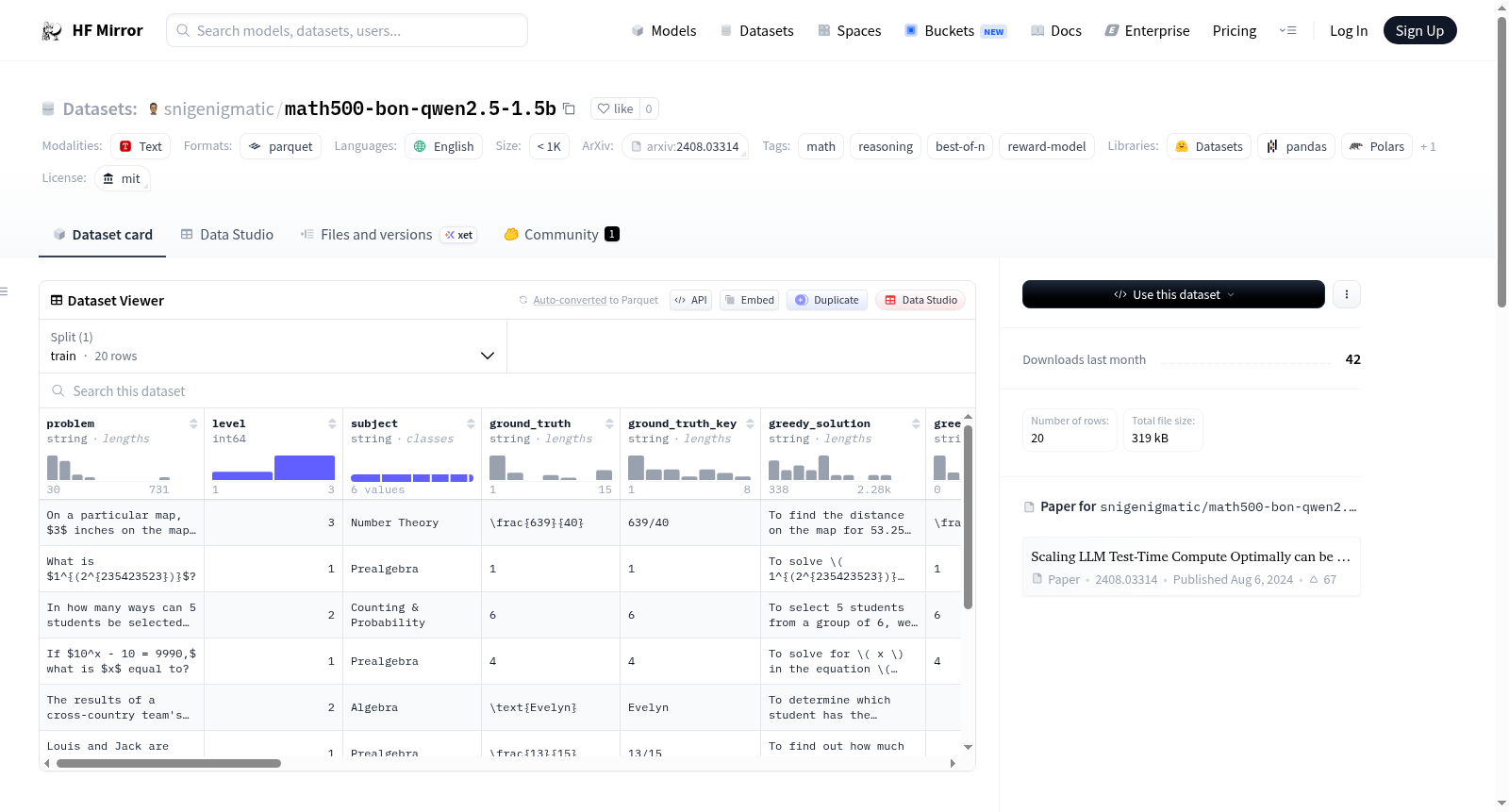
该数据集是一个小规模的数学推理和奖励模型评估实验,基于HuggingFaceH4/MATH-500数据集中的20个问题样本(难度级别1-3)。实验使用了Qwen2.5-1.5B模型和Skywork PRM进行测试,比较了贪婪方法、多数投票、奖励最大化以及加权Best-of-N等不同方法的准确率。数据集包含问题、级别、主题、真实答案、模型生成的解决方案和答案等列。
This dataset is a small-scale replication experiment for math reasoning and reward model evaluation, based on 20 problem samples (levels 1-3) from the HuggingFaceH4/MATH-500 dataset. The experiment uses the Qwen2.5-1.5B model and Skywork PRM for testing, comparing the accuracy of different methods including greedy, majority vote, argmax reward, and weighted Best-of-N. The dataset includes columns such as problem, level, subject, ground truth, model-generated solutions and answers.
提供机构:
snigenigmatic
搜集汇总
数据集介绍
构建方式
本数据集基于MATH-500原始数据中的20道难度等级为1至3的数学问题构建,采样种子固定为42。求解过程采用Qwen2.5-1.5B-Instruct模型作为生成器,在贪心解码(N=1)与最佳N采样(N=16,温度0.8,top_p 0.95)两种策略下分别生成解答。奖励信号由Skywork-o1-Open-PRM-Qwen-2.5-1.5B过程奖励模型提供,通过将解答格式化为包含换行步骤标记的文本,并取最终步骤logit的Sigmoid函数值作为得分。最终答案选择采用加权最佳N方法:解析每个解答中的\boxed{}结果,进行轻量级规范化(如分数、小数、带分数等形式的统一),按答案分组并累加奖励值,取总分最高的答案。
使用方法
研究者可直接加载该数据集用于测试或微调数学推理模型,尤其适合评估测试时计算扩展策略的效果。通过访问'problem'字段获取题目内容,结合'ground_truth'进行答案验证;利用'bon_samples'与'bon_rewards'字段可复现或改进加权投票机制。数据集中预计算了多种选择策略的结果,如'bon_majority_correct'和'bon_argmax_reward_correct',便于快速对比多数投票、奖励最大值与加权最佳N方法的性能差异。此外,'bon_weighted_groups'字段提供了分组聚合的详细信息,支持深入分析奖励分布与答案选择间的关联。
背景与挑战
背景概述
近年来,大语言模型在数学推理任务上取得了显著进展,然而,如何有效利用测试时计算资源以提升模型性能仍是该领域的热点问题。math500-bon-qwen2.5-1.5b数据集由Hugging Face团队于2025年构建,旨在探索加权最佳采样策略在数学推理中的适用性。该数据集基于MATH-500中的20个难度等级为1-3的数学问题,采用Qwen2.5-1.5B-Instruct模型作为求解器,并结合Skywork过程奖励模型进行评分,系统比较了贪婪解码、多数投票、奖励最大化及加权最佳采样四种策略。该工作复现了《Scaling Test-Time Compute with Open Models》中的基准方法,为后续研究提供了可复现的实验框架与数据支撑,对推理时计算扩展策略的实证研究具有重要参考价值。
当前挑战
数据集构建与研究所面临的挑战主要体现在以下方面。首先,数学推理任务本质复杂,模型需理解问题语义、执行多步运算并准确格式化答案,对推理能力要求极高。其次,在构建过程中,最佳采样策略面临样本效率与奖励模型可靠性的双重考验:仅依赖16个样本进行加权选择可能引入方差,而Skywork过程奖励模型的评分质量直接影响最终结果。此外,答案等效性通过轻量级规范化处理,但受限于未采用全量SymPy等价性验证,可能存在误判。最后,当前数据规模较小(20个样本),统计推断能力有限,难以全面评估不同策略在更广泛数学问题上的泛化性能。
常用场景
经典使用场景
该数据集MATH-500-BoN-Qwen2.5-1.5B聚焦于数学推理领域的加权最佳N采样(Weighted Best-of-N)方法验证。基于HuggingFaceH4/MATH-500子集的20道难度等级1至3的数学题,研究者可系统比较贪婪解码(Greedy)、多数投票(Majority Vote)、最大奖励(Argmax Reward)以及加权BoN四种策略的推理准确率。经典使用场景包括评估过程奖励模型(Process Reward Model, PRM)在数学问题解决中的有效性,以及探究采样次数N对推理性能的影响。该设计为少样本下数学推理的策略对比提供了标准化测试基准,尤其适合验证轻量级模型(如1.5B参数)配合PRM的推理能力上限。
解决学术问题
该数据集核心解决了如何有效结合过程奖励模型与采样策略来提升数学推理准确率的学术问题。通过对比贪婪解码与加权BoN的准确率差异(45% vs 70%),揭示了小模型在有限预算下通过合理奖励加权能够超越简单多数投票机制(65%)。更重要的是,数据集中对奖励求和的加权机制直接回应了“测试时计算扩展(Test-Time Compute Scaling)”这一前沿挑战,为arXiv:2408.03314中附录E的加权BoN理论提供了实证支撑。其意义在于为开源模型在数学推理的可靠性与计算效率权衡方面建立了可复现的基准,推动了无需巨大模型参数即可实现推理增强的研究方向。
实际应用
实际应用中,该数据集的方法可被直接部署于教育领域的自动解题系统或智能辅导平台。例如,在数学作业批改场景中,利用加权BoN策略从16个候选解答中筛选最优解,能够显著降低简单模型(如Qwen2.5-1.5B)的误判率(准确率从45%提升至70%)。Skywork PRM的奖励信号还可用于诊断学生错误推理步骤,辅助教师定位常见思维误区。此外,该数据集的轻量设计(仅需T4 GPU和bfloat16精度)使其适合边缘计算设备部署,例如在线学习系统的实时答题反馈功能,在不依赖昂贵硬件的前提下提升推理质量。
数据集最近研究
最新研究方向
该数据集聚焦于数学推理任务中测试时计算扩展的前沿探索,通过最佳N采样策略结合过程奖励模型(PRM)来提升大语言模型在复杂数学问题上的准确率。其研究热点在于权重化最佳N方法,该方法通过解析中间步骤的奖励信号并加权聚合答案候选,显著优于传统的贪心解码和多数投票基线。这一方向与当前业界对推理模型效率优化的迫切需求紧密相关,特别是在开放模型生态中,通过轻量级策略(如Skywork PRM与Qwen2.5的搭配)实现性能突破,为降低大规模部署成本提供了实证支持。数据集收录的80%准确率成果(基于argmax奖励选择)不仅验证了过程监督在数学领域的有效性,也推动了测试时计算资源分配策略的规范化研究,对构建可靠、可扩展的推理模型具有标杆意义。
以上内容由遇见数据集搜集并总结生成


