CineVerse
收藏arXiv2025-04-28 更新2025-04-30 收录
下载链接:
https://cinevers.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
CineVerse数据集是为了电影场景组合任务而创建的,它由马里兰大学帕克分校和Adobe Research共同开发。该数据集的创建旨在支持电影制作中的多角色、复杂交互和视觉电影效果等挑战,为电影场景的生成提供了高质量的数据支持。CineVerse数据集的创建过程和具体内容在文中未详细描述,但可以推测它包含了详细的场景描述、角色设定和镜头描述等信息。该数据集的应用领域主要在于电影视频合成,旨在生成视觉上连贯且内容丰富的电影场景,为电影制作提供新的可能性。
The CineVerse dataset was developed for the film scene composition task, and was jointly created by the University of Maryland, College Park and Adobe Research. It was designed to address core challenges in filmmaking such as multi-character scenarios, complex interactions and visual cinematic effects, providing high-quality data support for the generation of cinematic scenes. The specific creation process and detailed content of the CineVerse dataset are not elaborated in the relevant text, but it can be inferred that the dataset contains detailed scene descriptions, character settings and shot descriptions, along with other relevant information. Its main application fields lie in film video synthesis, aiming to generate visually coherent and content-rich cinematic scenes, thereby providing new possibilities for filmmaking.
提供机构:
马里兰大学帕克分校, Adobe Research
创建时间:
2025-04-28
原始信息汇总
CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition
摘要
- 提出CineVerse框架,专注于电影场景合成的任务。
- 任务特点:强调帧间一致性和连续性,解决电影制作中的多角色、复杂互动和视觉特效等挑战。
- 方法:创建CineVerse数据集,采用两阶段方法:
- 使用大型语言模型(LLM)生成详细场景计划(包括场景设置、角色描述和分镜描述)。
- 微调文本到图像生成模型以合成高质量视觉关键帧。
- 实验结果:CineVerse在生成视觉连贯且内容丰富的电影场景方面表现优异。
方法概述
- 第一阶段(LLM规划):
- 输入:场景描述。
- 输出:详细脚本,包括:
- 场景设置(背景描述)。
- 角色(独特外观描述)。
- 分镜描述(角色动作和指定镜头)。
- 第二阶段(关键帧合成):
- 使用生成的脚本,通过微调的文本到图像模型合成多张关键帧。
数据处理
- 使用预训练的视觉语言模型提取场景描述、分镜细节和角色外观。
对比实验
A. 多角色场景对比
- 对比方法:
- One-Prompt-One-Story (ICLR 2025)
- ConsiStory (TOG 2025)
- StoryDiff (NeurIPS 2024)
- IC-LoRA (arxiv 2024)
- 示例:
- 场景:技术人员通过“光环”装置制服嫌疑人。
- 地点:未来主义实验室。
- 角色:两名技术人员(女性和男性)和一名嫌疑人。
- 分镜描述:包含5个镜头(广角、中景、特写等)。
B. 单角色场景对比
- 对比方法:Video Studio (Long et al., ECCV 2024)
- 示例:
- 场景:Adam在电视工作室担任制作助理。
- 地点:繁忙的电视工作室。
- 角色:Adam(年轻男性,休闲装扮)。
- 分镜描述:包含3个镜头(广角、中景、特写)。
C. LLM分镜规划对比
- 对比方法:通用指令 vs. 指令优化
- 示例:
- 场景:Cobb的图腾(旋转的陀螺)。
- 地点:模糊的现实与梦境混合环境。
- 角色:Cobb(男性,短头发)。
- 分镜描述:包含3个镜头(广角、中景、特写)。
搜集汇总
数据集介绍
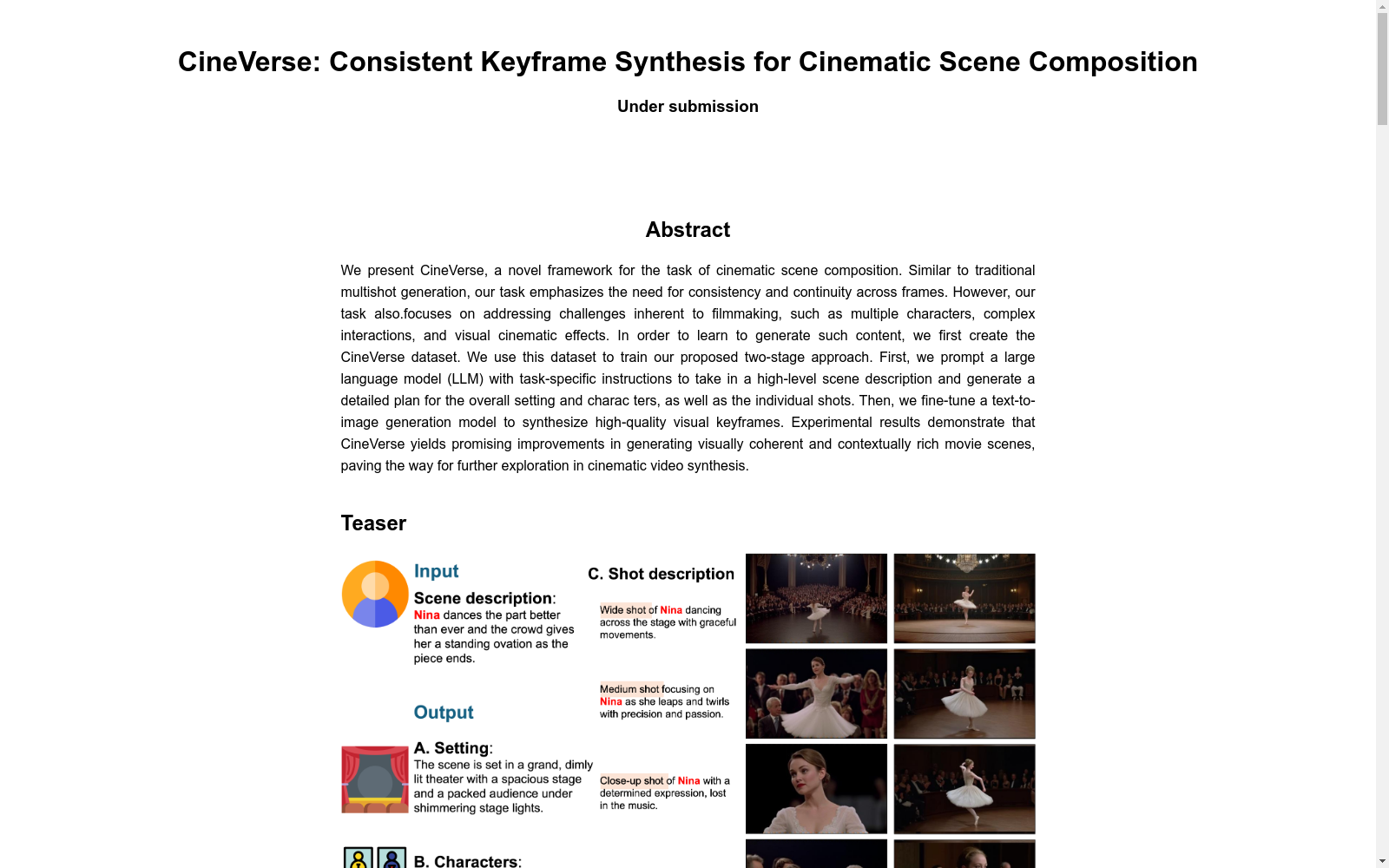
构建方式
CineVerse数据集的构建基于Storyboard20K数据集,通过多阶段精细处理流程实现。首先筛选出8.5K个多镜头场景作为基础数据,随后利用LLaVa-OneVision多模态大模型提取镜头描述、景别尺寸、场景设置和角色特征等新属性。针对原始数据中代词指代模糊的问题,结合MovieNet的全局情节信息,采用LLama3.3模型进行指代消解和场景描述细化,最终形成包含46K个镜头的增强型数据集。
使用方法
使用该数据集需遵循两阶段流程:首先将高层场景描述输入经过微调的LLM(如LLama3.3-70B)生成包含场景设置、角色属性和分镜脚本的详细规划;随后采用基于FLUX架构的文本生成图像模型,通过固定高度(272px)和棋盘格边界(16px)的预处理方式,将分镜脚本转换为视觉连贯的关键帧序列。特别建议在微调时采用rank=128的LoRA适配器,以获得最佳的多镜头生成效果。
背景与挑战
背景概述
CineVerse数据集由马里兰大学和Adobe Research的研究团队于2025年创建,旨在解决电影场景合成的关键问题。该数据集专注于从高级场景描述生成连贯的多镜头关键帧,强调角色一致性、场景连续性和电影化效果。作为首个专门针对电影级多镜头合成的数据集,CineVerse通过整合Storyboard20K的8.5K多镜头场景并新增镜头尺寸、场景设置等标注,为生成式AI在电影叙事领域的应用提供了重要基准。其创新性的两阶段框架——基于大语言模型的场景规划和文本到图像的关键帧生成——显著提升了视觉叙事的一致性,对自动电影制作、虚拟制片等领域产生深远影响。
当前挑战
CineVerse面临的核心挑战体现在两个维度:在领域问题层面,现有方法难以同时保证多角色交互的视觉一致性、复杂电影效果的呈现以及严格遵循电影语法规则的镜头序列生成;在构建过程层面,数据收集需解决原始场景描述中代词指代模糊的问题,而多模态大模型标注时需平衡细节丰富性与标注效率。此外,固定帧高度与可变宽度图像的处理、关键帧间明确边界的定义等技术难题也增加了数据集构建的复杂性。这些挑战使得电影级场景合成成为生成式AI中尚未完全攻克的前沿问题。
常用场景
经典使用场景
CineVerse数据集在电影场景合成领域具有广泛的应用价值,尤其在生成多镜头一致的关键帧方面表现突出。该数据集通过结合大型语言模型(LLM)和文本到图像生成模型,能够根据高层场景描述生成详细的镜头计划和高质量的关键帧。这一过程不仅涵盖了场景设置、角色描述,还包括具体的镜头大小和动作细节,为电影制作和视觉叙事提供了强有力的支持。
解决学术问题
CineVerse数据集解决了电影场景合成中的多个关键学术问题。首先,它通过生成一致且连贯的关键帧序列,解决了多镜头生成中的一致性和连续性问题。其次,该数据集能够处理复杂场景中的多角色交互和视觉特效,填补了现有方法在复杂场景生成上的不足。此外,CineVerse还通过详细的镜头描述和角色标注,提升了文本到图像生成模型在电影场景合成中的表现。
实际应用
在实际应用中,CineVerse数据集为电影制作、动画设计和游戏开发等领域提供了强大的工具。电影制作者可以利用该数据集快速生成故事板,预览不同镜头的效果,从而优化拍摄计划。动画设计师可以通过生成一致的角色和场景,提高动画制作的效率和质量。此外,游戏开发者也可以利用该数据集生成游戏场景中的关键帧,增强游戏的视觉叙事效果。
数据集最近研究
最新研究方向
近年来,CineVerse数据集在电影场景合成领域引起了广泛关注。该数据集专注于解决电影制作中的关键挑战,如多角色交互、复杂场景布局以及视觉连续性。通过结合大型语言模型(LLM)和文本到图像生成模型,CineVerse能够从高层场景描述生成详细的镜头计划和高质量的关键帧。这一方法不仅提升了文本与图像的对齐度,还在角色一致性和场景连续性方面表现出色。当前的研究热点包括如何进一步优化模型的生成能力,以处理更复杂的电影叙事结构,以及如何将这一技术应用于实际电影制作流程中。CineVerse的出现为电影自动生成和后期制作提供了新的可能性,推动了生成式人工智能在影视行业的应用。
相关研究论文
- 1CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition马里兰大学帕克分校, Adobe Research · 2025年
以上内容由遇见数据集搜集并总结生成


