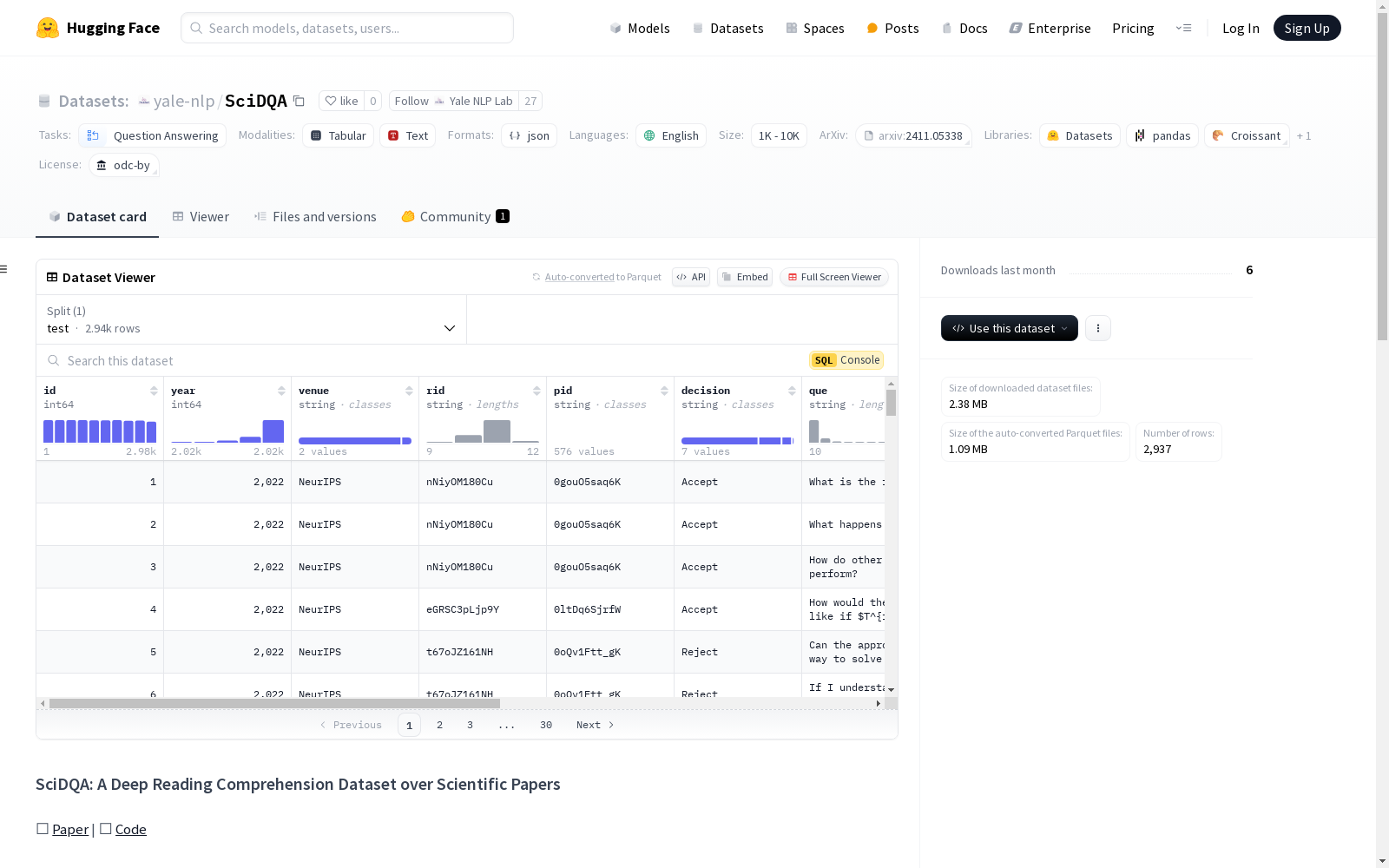
SciDQA
收藏SciDQA: A Deep Reading Comprehension Dataset over Scientific Papers
概述
SciDQA 是一个用于阅读理解的新数据集,专注于科学论文的深度理解。该数据集包含 2,937 个问答对,旨在挑战语言模型对科学文章的深度理解能力。与其他的科学问答数据集不同,SciDQA 的问题来源于领域专家的同行评审,答案则由论文作者提供,确保了对文献的彻底审查。
特点
- 数据来源:问题来源于同行评审,答案由论文作者提供。
- 数据处理:通过过滤低质量问题、去上下文化、跟踪不同版本的源文档以及引入参考文献,提升了数据集的质量。
- 多文档问答:问题需要跨图表、表格、公式、附录和补充材料的推理,并要求多文档推理。
评估
数据集通过多种配置评估了多个开源和专有的语言模型,探索它们在生成相关和事实性响应方面的能力。评估基于表面相似性和语言模型判断的指标,揭示了显著的性能差异。
许可证
Open Data Commons Attribution License (ODC-By) v1.0
引用
@inproceedings{singh-etal-2024-scidqa, title = "{S}ci{DQA}: A Deep Reading Comprehension Dataset over Scientific Papers", author = "Singh, Shruti and Sarkar, Nandan and Cohan, Arman", editor = "Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung", booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing", month = nov, year = "2024", address = "Miami, Florida, USA", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2024.emnlp-main.1163", doi = "10.18653/v1/2024.emnlp-main.1163", pages = "20908--20923", abstract = "Scientific literature is typically dense, requiring significant background knowledge and deep comprehension for effective engagement. We introduce SciDQA, a new dataset for reading comprehension that challenges language models to deeply understand scientific articles, consisting of 2,937 QA pairs. Unlike other scientific QA datasets, SciDQA sources questions from peer reviews by domain experts and answers by paper authors, ensuring a thorough examination of the literature. We enhance the dataset{}s quality through a process that carefully decontextualizes the content, tracks the source document across different versions, and incorporates a bibliography for multi-document question-answering. Questions in SciDQA necessitate reasoning across figures, tables, equations, appendices, and supplementary materials, and require multi-document reasoning. We evaluate several open-source and proprietary LLMs across various configurations to explore their capabilities in generating relevant and factual responses, as opposed to simple review memorization. Our comprehensive evaluation, based on metrics for surface-level and semantic similarity, highlights notable performance discrepancies. SciDQA represents a rigorously curated, naturally derived scientific QA dataset, designed to facilitate research on complex reasoning within the domain of question answering for scientific texts.", }