ipo-images
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/gtfintechlab/ipo-images
下载链接
链接失效反馈官方服务:
资源简介:
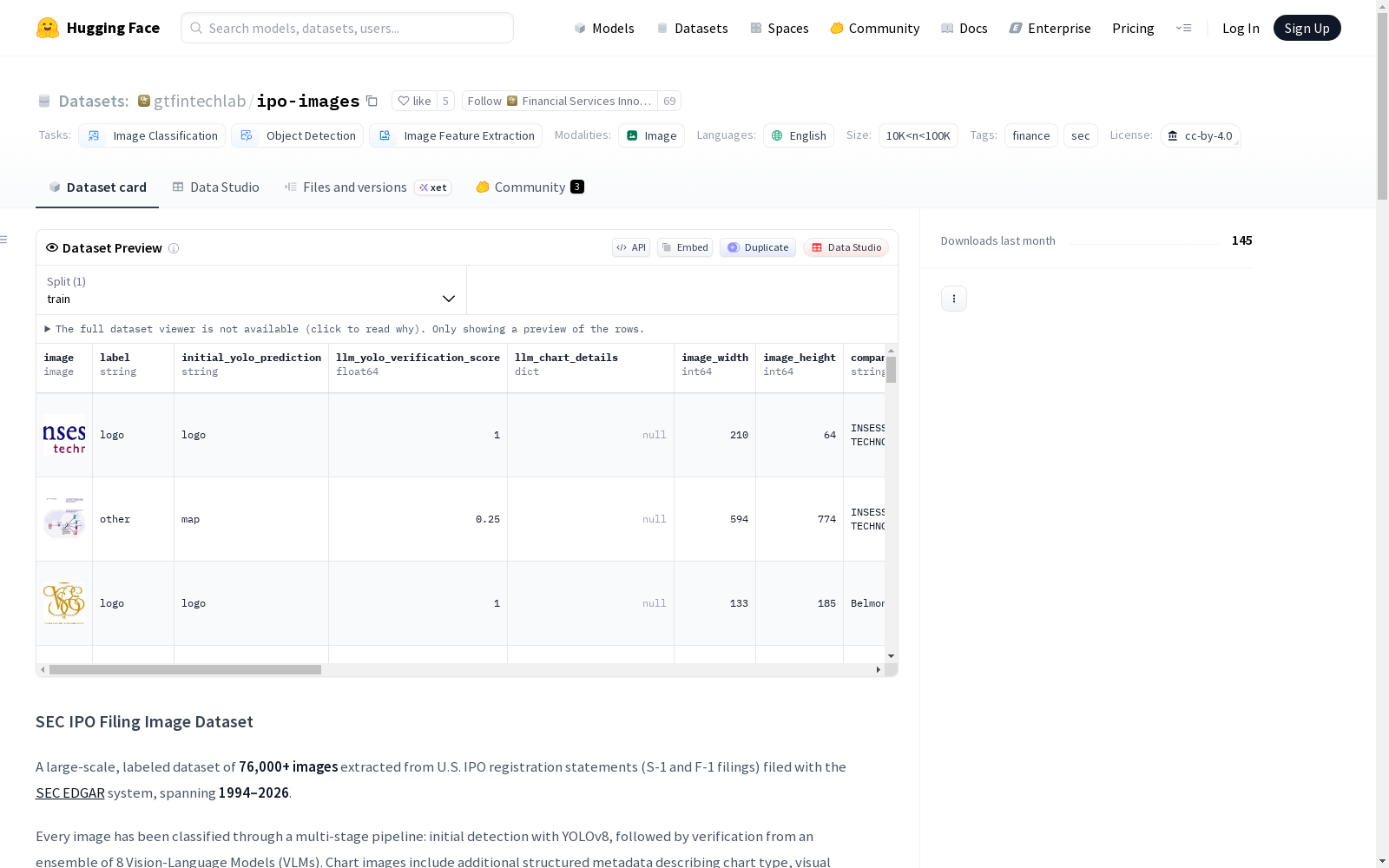
SEC IPO (S-1/F-1) 图像数据集是一个大规模、带标签的数据集,包含从美国证券交易委员会(SEC)EDGAR系统中提取的76,000多张图像,涵盖1994年至2026年的IPO注册声明(S-1和F-1文件)。每张图像都通过多阶段流程进行分类:首先使用YOLOv8进行初始检测,然后由8个视觉语言模型(VLM)组成的集合进行验证。图表图像还包括描述图表类型、视觉属性和内容的结构化元数据。数据集包含以下标签:图表(如条形图、折线图、饼图等)、标志(公司标志和品牌标记)、地图(地理地图)、信息图(结合数据、图标和文本的复合视觉展示)和其他(装饰性图像、照片、签名等)。数据集字段包括图像与分类信息、图表详细信息(仅限图表)、公司与文件元数据以及来源URL。该数据集适用于图像分类、目标检测和图像特征提取等任务,特别适合金融和SEC文件分析。
The SEC IPO (S-1/F-1) Image Dataset is a large-scale, labeled dataset containing over 76,000 images extracted from the U.S. Securities and Exchange Commission (SEC) EDGAR system, covering IPO registration statements (S-1 and F-1 filings) from 1994 to 2026. Each image is classified via a multi-stage pipeline: initial detection using YOLOv8, followed by validation using an ensemble of 8 vision-language models (VLMs). Chart images also include structured metadata describing chart type, visual attributes, and content. The dataset includes the following labels: charts (e.g., "bar charts", "line charts", "pie charts", etc.), logos (company logos and brand marks), maps (geographic maps), infographics (composite visual displays combining data, icons, and text), and others (decorative images, photographs, signatures, etc.). The dataset fields include image and classification information, chart details (for chart images only), company and document metadata, and source URLs. This dataset is suitable for tasks such as image classification, object detection, and image feature extraction, and is particularly well-suited for financial and SEC document analysis.
创建时间:
2026-02-08
原始信息汇总
SEC IPO (S-1/F-1) 图像数据集概述
数据集基本信息
- 数据集名称: SEC IPO (S-1/F-1) Image Dataset
- 数据集规模: 76,000+ 图像
- 数据来源: 美国证券交易委员会(SEC)EDGAR系统中提交的IPO注册声明(S-1和F-1文件)
- 时间跨度: 1994年至2026年
- 许可协议: CC BY 4.0
- 主要语言: 英语
- 任务类别: 图像分类、目标检测、图像特征提取
- 标签: 金融、SEC
- 规模类别: 10K<n<100K
数据内容与标注
数据集包含从美国IPO文件中提取的图像,每张图像都通过一个多阶段流程进行了分类:首先使用YOLOv8进行初始检测,然后由8个视觉语言模型(VLM)组成的集成模型进行验证。图表图像还包含描述图表类型、视觉属性和内容的结构化元数据。
图像标签类别
| 标签 | 描述 |
|---|---|
chart |
条形图、折线图、饼图、组织结构图、流程图等 |
logo |
公司徽标和品牌标识 |
map |
地理地图 |
infographic |
结合数据、图标和文本的复合视觉展示 |
other |
装饰性图像、照片、签名和其他不可分类的视觉内容 |
数据字段说明
图像与分类字段
file_name: 图像文件的相对路径label: 最终验证的图像类别initial_yolo_prediction: YOLOv8目标检测模型的原始分类llm_yolo_verification_score: VLM集成模型验证YOLO预测的共识分数(0.0–1.0)llm_yolo_verification_votes: 用于验证的8个VLM中每个模型的投票结果image_width: 图像宽度(像素)image_height: 图像高度(像素)
图表详情字段(仅图表图像)
llm_chart_details: 图表图像的结构化属性llm_chart_details_votes: 图表细节提取的每个模型投票结果
公司与文件元数据字段
company_name: 提交IPO的公司名称company_tickers: 股票代码(如提交时可用)cik: SEC中央索引密钥sic: 标准行业分类代码industry: 从SIC代码得出的人类可读行业描述office: 负责审查文件的SEC办公室exchanges: 公司上市的证券交易所filing_type: SEC表格类型filing_date: 文件提交日期filing_accession_number: 文件的唯一SEC登记号
来源URL字段
image_url: SEC EDGAR上图像的直接URLfiling_url: SEC EDGAR上源文件文档的URL
引用信息
如果使用此数据集,请引用: bibtex @misc{galarnyk2026ipomine, title = {IPO-Mine: A Toolkit and Dataset for Section-Structured Analysis of Long, Multimodal IPO Documents}, author = {Galarnyk, Michael and Lohani, Siddharth and Nandi, Sagnik and Patel, Aman and Kannan, Vidhyakshaya and Banerjee, Prasun and Routu, Rutwik and Ye, Liqin and Hiray, Arnav and Somani, Siddhartha and Chava, Sudheer}, year = {2026}, url = {https://huggingface.co/datasets/gtfintechlab/ipo-images}, note = {Preprint/Working Paper} }
搜集汇总
数据集介绍
构建方式
在金融文档分析领域,SEC IPO图像数据集的构建体现了多模态信息处理的严谨性。该数据集通过自动化流程从美国证券交易委员会EDGAR系统中提取了超过7.6万张图像,涵盖1994年至2026年间的IPO注册文件。构建过程采用两阶段验证机制:首先运用YOLOv8模型进行初步图像检测与分类,随后通过八种视觉语言模型组成的集成系统进行交叉验证,确保标签的准确性。对于图表类图像,还额外提取了图表类型、视觉属性等结构化元数据,形成了层次化的标注体系。
特点
该数据集的核心特征在于其精细化的分类体系和丰富的元数据维度。所有图像均被划分为图表、标识、地图、信息图及其他五大类别,每张图像不仅包含基础分类标签,还保留了初始预测结果和集成验证的置信度分数。特别值得注意的是,图表类图像附带了完整的结构化描述,包括三维属性、图例信息等深度特征。数据集同时整合了发行公司的行业分类、交易所信息及文件提交日期等金融属性,实现了视觉内容与商业背景的有机融合。
使用方法
从应用视角出发,该数据集为金融文档的多模态研究提供了标准化实验平台。研究人员可直接通过HuggingFace平台加载数据集,利用预定义的图像路径和元数据字段进行模型训练。对于图表分析任务,可调用llm_chart_details字段中的结构化信息开发专门的视觉问答系统;在跨模态检索场景中,结合公司行业标签与图像类别可实现精准的内容关联分析。数据集采用的通用图像格式确保了与主流深度学习框架的兼容性,其分层验证机制也为模型可靠性评估提供了基准参照。
背景与挑战
背景概述
在金融信息处理与多模态数据分析领域,SEC IPO图像数据集由佐治亚理工学院金融科技实验室的研究团队于2026年构建,旨在系统化地提取与分析美国证券交易委员会(SEC)首次公开募股(IPO)注册文件(S-1与F-1表格)中的视觉内容。该数据集涵盖了自1994年至2026年间超过76,000张图像,通过融合目标检测与视觉语言模型的混合标注流程,实现了对图表、标识、地图、信息图及其他视觉元素的精细分类。其核心研究问题聚焦于如何从结构复杂的金融文档中自动化解析视觉信息,以支持财务分析、风险评估与监管科技等应用,为金融文本的多模态理解提供了重要的基准资源。
当前挑战
该数据集致力于解决金融文档多模态理解中的核心挑战,即如何准确识别与分类IPO文件内嵌的多样化视觉元素,以增强自动化财务分析的效能。在构建过程中,面临的主要挑战包括:从非结构化的PDF文档中可靠地提取图像,并保持其视觉完整性;设计稳健的标注流程以应对金融图表的高度专业性与视觉变异,例如三维图表与复合信息图;以及整合多模型验证机制以确保标注质量,克服单一模型在复杂场景下的误判风险。这些挑战凸显了在领域特定数据上实现高精度视觉理解的复杂性。
常用场景
经典使用场景
在金融信息处理领域,SEC IPO图像数据集为图像分类与目标检测任务提供了高质量的基准资源。该数据集从美国证券交易委员会的IPO注册文件中提取了超过7.6万张图像,并经过多阶段流程验证标注,涵盖了图表、标识、地图、信息图等多种视觉类别。研究者可利用这一数据集训练和评估计算机视觉模型,特别是在处理金融文档中复杂的视觉元素时,能够有效提升模型对特定领域图像的识别精度与鲁棒性。
实际应用
在实际应用层面,SEC IPO图像数据集能够赋能金融科技与监管科技领域。例如,投资机构可借助基于该数据集训练的模型,自动扫描海量IPO文件,快速提取并分析其中的关键图表数据,以辅助投资决策。同时,监管机构也可利用相关技术实现IPO文档的自动化审查,提升对信息披露合规性的监督效率。这些应用显著降低了人工处理成本,并增强了金融信息处理的规模与深度。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。其核心来源论文《IPO-Mine: A Toolkit and Dataset for Section-Structured Analysis of Long, Multimodal IPO Documents》提出了一个用于长篇幅、多模态IPO文档分析的工具包与数据集框架。在此基础上,后续研究可能进一步探索视觉语言模型在金融图表理解中的应用,或结合文本与图像信息进行跨模态的财务风险预测,持续拓展了计算金融学的研究边界。
以上内容由遇见数据集搜集并总结生成


