BTZSC
收藏arXiv2026-03-12 更新2026-03-14 收录
下载链接:
https://huggingface.co/datasets/btzsc/btzsc
下载链接
链接失效反馈官方服务:
资源简介:
BTZSC是由欧洲中央银行研究者提出的零样本文本分类基准,涵盖情感、主题、意图和情绪分类四大任务,整合了22个高质量公开数据集,数据来源包括新闻、社交媒体、产品评论等多领域。该数据集通过严格筛选确保任务多样性和领域平衡性,平均文本长度从13至293个token不等,旨在系统评估NLI交叉编码器、嵌入模型、重排序器及指令调优大模型的零样本性能,推动自然语言理解技术的公平可复现研究。
BTZSC is a zero-shot text classification benchmark proposed by researchers from the European Central Bank. It encompasses four core tasks: sentiment classification, topic classification, intent classification and emotion classification, integrating 22 high-quality public datasets with data sources spanning multiple domains including news, social media and product reviews. This benchmark ensures task diversity and domain balance through strict screening, with average text lengths ranging from 13 to 293 tokens. It aims to systematically evaluate the zero-shot performance of NLI cross-encoders, embedding models, rerankers and instruction-tuned large language models (LLMs), and promote fair and reproducible research on natural language understanding technologies.
提供机构:
欧洲中央银行
创建时间:
2026-03-12
原始信息汇总
BTZSC 数据集概述
数据集基本信息
- 数据集名称:BTZSC: Benchmark for Textual Zero-Shot Classification
- 数据集地址:https://huggingface.co/datasets/btzsc/btzsc
- 主要用途:用于文本零样本分类的基准测试套件,支持在跨编码器、嵌入模型、重排序器和大型语言模型等主要模型家族之间进行公平评估。
- 任务类别:文本分类、零样本分类
- 语言:英语
- 许可协议:汇总了多个公共数据集,各源数据集许可协议不同,需遵守原始数据集许可。
- 标签:零样本分类、基准测试
数据集结构与配置
数据集以单一 Hugging Face 数据集仓库形式发布,包含多个配置。
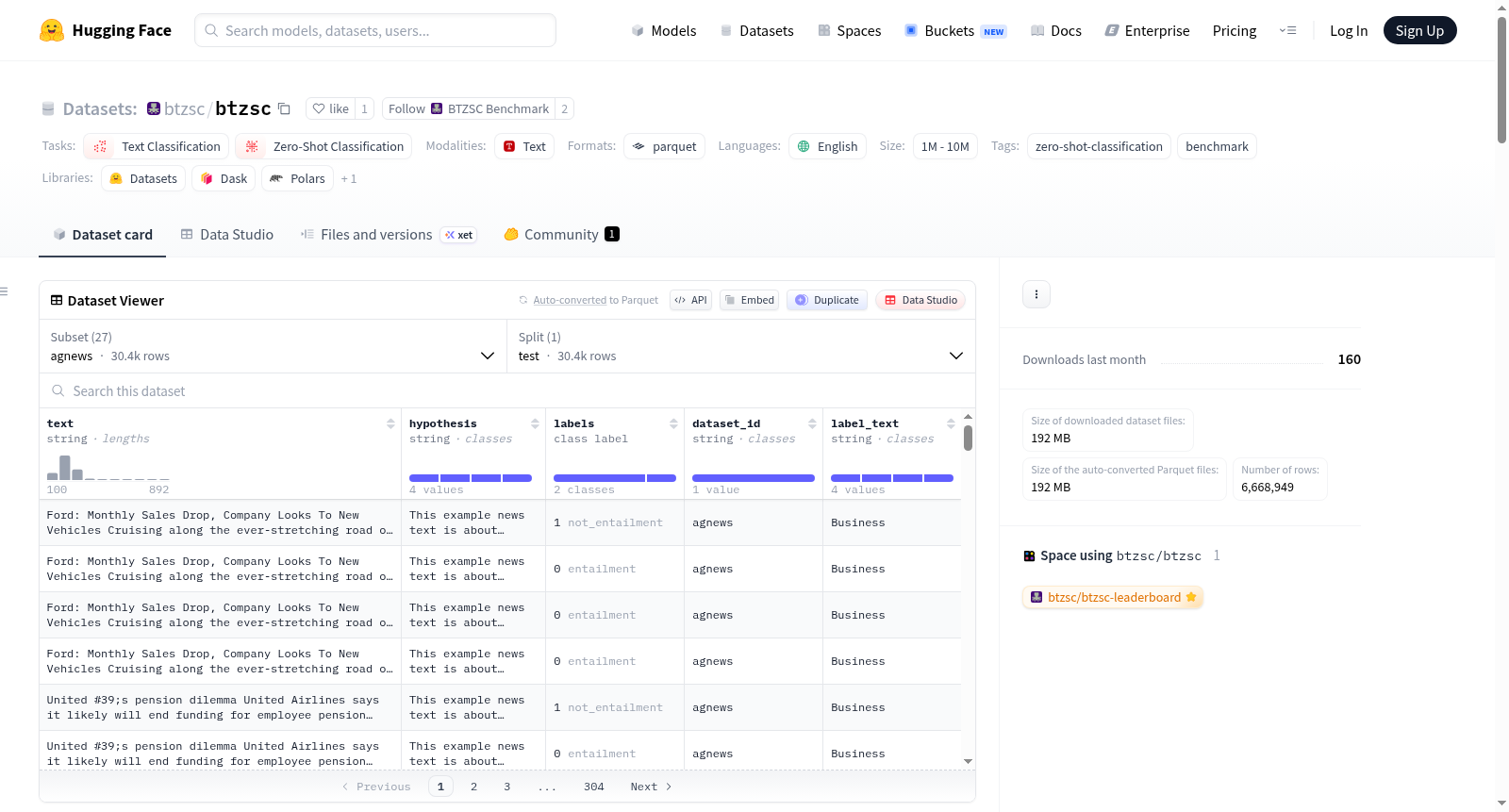
基础数据集(22个)
| 任务类别 | 包含的数据集配置名称 |
|---|---|
| 情感分析 | amazonpolarity, imdb, appreviews, yelpreviews, rottentomatoes, financialphrasebank |
| 情感识别 | emotiondair, empathetic |
| 意图识别 | banking77, biasframes_intent, massive |
| 主题分类 | agnews, yahootopics, trueteacher, manifesto, capsotu, biasframes_offensive, biasframes_sex, wikitoxic_insult, wikitoxic_obscene, wikitoxic_threat, wikitoxic_toxicaggregated |
便捷捆绑包
| 捆绑包配置名称 | 描述 |
|---|---|
sentiment |
全部6个情感分析数据集 |
emotion |
全部2个情感识别数据集 |
intent |
全部3个意图识别数据集 |
topic |
全部11个主题分类数据集 |
all |
全部22个数据集 |
数据详情
所有配置均仅包含测试集。
数据特征
所有配置共享以下核心特征:
text:输入文档文本。hypothesis:由候选标签构建的自然语言假设。labels:二元目标标签。0表示蕴含,1表示不蕴含。label_text:候选类别名称。
部分配置额外包含:
dataset_id:数据集标识符。task_name:任务名称。
数据规模统计
| 配置名称 | 样本数量 | 数据集大小(字节) | 下载大小(字节) |
|---|---|---|---|
agnews |
30,400 | 9,630,696 | 1,280,949 |
all |
2,222,983 | 1,030,704,708 | 64,153,380 |
amazonpolarity |
20,000 | 10,798,222 | 2,974,010 |
appreviews |
8,000 | 2,414,054 | 566,905 |
banking77 |
221,760 | 40,018,400 | 804,682 |
biasframes_intent |
7,296 | 1,592,094 | 310,428 |
biasframes_offensive |
7,676 | 1,785,704 | 327,567 |
biasframes_sex |
8,808 | 1,830,030 | 379,857 |
capsotu |
70,455 | 24,646,828 | 723,183 |
emotion |
93,344 | 54,342,486 | 1,249,373 |
emotiondair |
12,000 | 2,202,560 | 158,115 |
empathetic |
81,344 | 52,139,926 | 1,092,730 |
financialphrasebank |
2,070 | 514,854 | 65,448 |
imdb |
20,000 | 27,862,150 | 8,559,151 |
intent |
404,522 | 65,522,268 | 1,669,284 |
manifesto |
953,008 | 417,565,056 | 8,569,698 |
massive |
175,466 | 23,911,774 | 558,077 |
rottentomatoes |
2,132 | 493,664 | 95,622 |
sentiment |
72,202 | 57,771,774 | 16,757,956 |
topic |
1,652,915 | 853,068,180 | 44,471,303 |
trueteacher |
17,910 | 24,821,652 | 6,972,936 |
wikitoxic_insult |
16,854 | 7,364,528 | 1,724,127 |
wikitoxic_obscene |
17,382 | 7,951,550 | 1,847,410 |
wikitoxic_threat |
10,422 | 5,174,652 | 1,332,140 |
wikitoxic_toxicaggregated |
20,000 | 9,026,954 | 2,024,344 |
yahootopics |
500,000 | 343,270,530 | 19,108,728 |
yelpreviews |
20,000 | 15,688,830 | 4,505,433 |
数据格式
数据集以成对蕴含格式提供,使其可直接用于NLI风格的跨编码器,并为其他零样本分类方法提供统一接口。 每个数据行对应一个*(文本,候选标签)*对:
- 对于每个原始示例,BTZSC包含一个正样本对(真实标签)和多个负样本对(所有其他标签)。
评估协议
- 主要指标:每个数据集的宏F1分数,跨数据集平均得到总体分数。
- 次要指标:准确率、宏精确率、宏召回率。
- 协议:严格的零样本协议,禁止在评估数据集上进行训练或调优。
- 评估任务家族:情感分析、主题分类、意图识别、情感识别。
相关资源
- 论文:https://openreview.net/forum?id=IxMryAz2p3
- 评估工具:https://github.com/IliasAarab/btzsc
- 排行榜空间:https://huggingface.co/spaces/btzsc/btzsc-leaderboard
- 排行榜结果数据集:https://huggingface.co/datasets/btzsc/btzsc-results
引用信息
bibtex @inproceedings{aarab2026btzsc, title = {BTZSC: A Benchmark for Zero-Shot Text Classification Across Cross-Encoders, Embedding Models, and Rerankers}, author = {Aarab, Ilias}, booktitle = {International Conference on Learning Representations (ICLR) 2026}, year = {2026}, note = {OpenReview PDF: https://openreview.net/pdf?id=IxMryAz2p3}, url = {https://openreview.net/forum?id=IxMryAz2p3} }
搜集汇总
数据集介绍
构建方式
BTZSC基准的构建遵循系统化原则,旨在全面评估零样本文本分类任务。该基准整合了22个公开数据集,涵盖情感分析、主题分类、意图识别和情绪检测四大任务类别,确保任务多样性与领域代表性。数据集选自高质量公开资源,并经过标准化预处理,统一为单标签分类格式,每个样本包含文本输入和类别标签。通过加权Jaccard相似度分析,验证了数据集间的词汇多样性,同时依据文档长度、类别基数和领域分布进行平衡筛选,构建了一个兼具广度和深度的评估体系。
特点
BTZSC基准的突出特点在于其跨模型架构的统一评估框架,首次将自然语言推理交叉编码器、文本嵌入模型、重排序器和指令调优大语言模型纳入同一零样本协议下比较。该基准覆盖多样化的任务难度与领域分布,从二分类到高基数分类,从短文本到长文档,全面检验模型的泛化能力。评估采用宏观F1作为核心指标,确保类别不平衡下的公平性,同时提供微观准确率及精确率、召回率等细粒度分析。基准设计强调可复现性,所有数据集、代码与模型检查点均公开,支持持续的零样本文本理解研究。
使用方法
使用BTZSC进行评估时,需遵循严格的零样本协议:模型仅能基于预训练参数和通用提示模板进行预测,不得使用任何任务特定标注数据进行微调或调优。对于不同模型家族,采用统一的标签文本化策略,将类别标签转化为自然语言描述。评估流程包括:对每个数据集独立计算宏观F1等指标,再通过未加权平均聚合得到任务族和整体性能。研究人员可通过公开的代码库加载标准化数据集,并利用提供的脚本进行批量推理与结果分析,从而在不同模型架构间进行公平比较,推动零样本分类技术的进步。
背景与挑战
背景概述
BTZSC(Benchmark for Zero-Shot Text Classification)是欧洲中央银行研究人员Ilias Aarab于2026年提出的一个综合性零样本文本分类基准。该基准旨在系统评估自然语言推理交叉编码器、文本嵌入模型、重排序器以及指令调优大语言模型在零样本场景下的性能。BTZSC整合了22个公开数据集,涵盖情感分析、主题分类、意图识别和情感检测四大任务类别,涉及新闻、社交媒体、产品评论、政治文本等多个领域,具有多样化的类别基数和文档长度。其核心研究目标是解决现有评估体系(如MTEB)在零样本能力测评上的局限性,为不同模型架构提供公平、可复现的比较平台,推动零样本文本理解领域的研究进展。
当前挑战
BTZSC所应对的领域挑战在于零样本文本分类中模型架构的快速演进与评估标准的不统一。传统评估方法往往依赖监督式微调或线性探针,未能真实反映模型的零样本泛化能力;同时,新兴的嵌入模型、重排序器与大语言模型缺乏跨家族的标准化对比。构建过程中的挑战包括:数据集的筛选与平衡需兼顾任务多样性、领域代表性和类别基数,以确保基准的鲁棒性;标签描述的统一化与语义对齐要求精细设计,避免评估偏差;模型评估协议的一致性维护涉及不同架构的推理方式适配,如嵌入模型的余弦相似度计算、重排序器的相关性评分以及大语言模型的提示工程,均需严格标准化以保证结果可比性。
常用场景
经典使用场景
在自然语言处理领域,零样本文本分类旨在无需任务特定标注的情况下,通过直接匹配文本与人类可读的标签描述来完成分类任务。BTZSC基准通过整合22个公开数据集,覆盖情感、主题、意图和情感分类四大类别,为研究者提供了一个系统评估不同模型家族在零样本设置下性能的统一平台。该数据集最经典的使用场景在于系统比较基于自然语言推理的交叉编码器、文本嵌入模型、重排序模型以及指令调优的大型语言模型,揭示它们在多样领域、类别基数和文档长度下的相对优势与局限。
解决学术问题
BTZSC解决了零样本文本分类领域中长期存在的评估碎片化问题。传统基准如MTEB往往通过监督探针或微调引入标注样本,未能真正检验模型的零样本能力;而早期工作多局限于单一模型家族或狭窄任务范畴。BTZSC通过构建一个全面、任务平衡的评估套件,首次在一致的零样本协议下联合评估四大模型家族,使得研究者能够客观比较不同架构的零样本分类性能,从而推动对模型泛化能力、语义匹配机制以及跨任务可转移性的深入理解。
衍生相关工作
BTZSC的推出催生了一系列围绕零样本分类模型比较与优化的研究。基于其评估框架,后续工作可以深入探索多语言扩展、改进标签言语化策略、提示工程优化以及模型缩放规律。例如,研究可针对BTZSC揭示的重排序模型缩放收益显著、嵌入模型在中等规模后性能饱和等现象,设计更高效的训练范式或架构改进。此外,该基准也为探究自然语言推理能力与零样本分类性能之间的关联提供了数据基础,推动了语义匹配理论与应用的发展。
以上内容由遇见数据集搜集并总结生成


