mipbench-anon/mipbench
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/mipbench-anon/mipbench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-4.0
---
提供机构:
mipbench-anon
搜集汇总
数据集介绍
构建方式
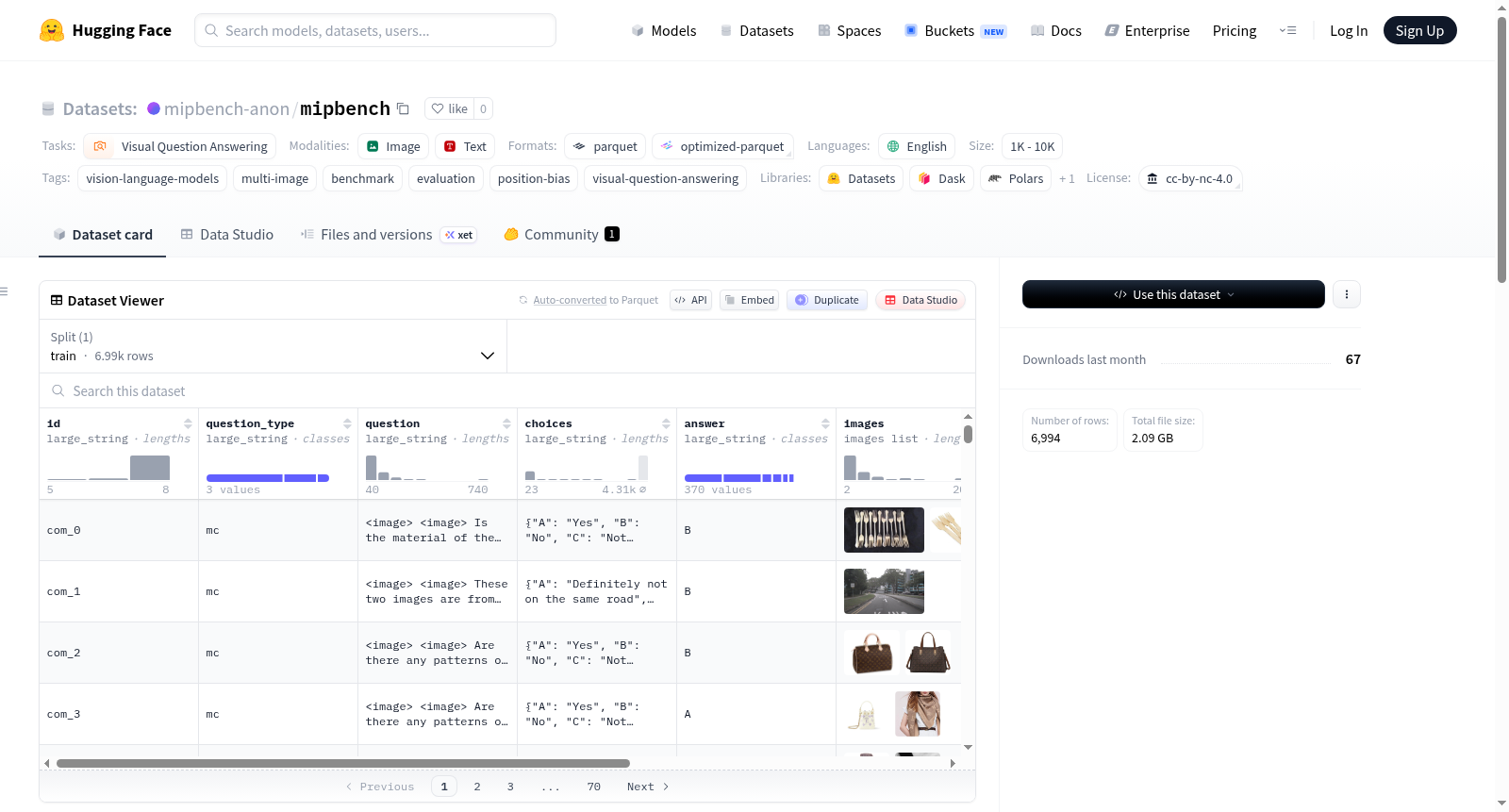
MIPBench是一个专用于评估多图像视觉问答中位置敏感性(position sensitivity)的高精度基准数据集,其构建过程严谨而系统。它从九个公开的多图像基准数据集中提取了6,994个位置不变(position-invariant)的示例,这些示例经过一个三阶段流水线过滤和人工审核,确保其正确答案不依赖于图像输入的顺序。每个示例均保留了来源基准的名称和原始标识符,同时标注了任务类别和答案格式等元数据,为后续分析提供了丰富的溯源信息。
特点
MIPBench的核心特点在于其针对位置不变性场景下的模型稳定性评估而设计,涵盖了五种任务类别和三种答案格式(如多项选择、是否类、短答案)。该数据集通过计算图像排列下的预测准确率、一致性率和翻转率(flip rate)等指标,能够精准量化视觉语言模型在输入图像顺序变化时的预测稳定性。其高精度特性来源于严格的过滤和人工审核流程,有效避免了因图像顺序依赖而引入的噪声。
使用方法
MIPBench仅用于评估,不可用于模型训练。使用时,用户需将包含多张图像及其对应问题的示例输入至待评估的视觉语言模型,要求模型对多个图像排列版本(permutations)进行预测。通过比较模型在相同问题下不同图像顺序的预测结果,可以计算其准确率、一致性率和翻转率,从而诊断模型是否存在位置偏差。该基准支持多种答案格式,兼容常见推理管道,为多图像视觉语言模型的公平性评估提供了标准化工具。
背景与挑战
背景概述
MIPBench(Multi-Image Position Benchmark)是由研究者在2023年提出的一项专用评测基准,旨在衡量多图像视觉问答(VQA)模型中位置不变性(position invariance)的敏感度。该数据集由多位研究人员合作构建,来源于九个公开的多图像基准,通过三阶段筛选与人工审核,确保每个样本的正确答案不依赖于图像顺序。MIPBench包含6,994个样本,覆盖五种任务类别和三种答案格式,专注于评估模型在图像排列变换下预测的准确性、一致性和翻转率。该基准对多模态大语言模型的稳健性研究具有重要意义,揭示了当前模型在位置感知上的潜在缺陷,推动了该领域向更可靠的方向发展。
当前挑战
MIPBench所解决的核心领域挑战是位置偏差(position bias)问题,即多图像VQA模型可能因输入图像的排列顺序不同而改变输出结果,这与理想中位置无关的推理要求相悖。构建过程中,挑战在于从已有基准中精确筛选出严格满足位置不变性的样本,避免引入隐藏的顺序依赖,这需要复杂的过滤流水线和精细的人工校验。此外,由于源数据集存在语言、地理、人口统计和视觉领域的固有偏见,MIPBench也面临继承这些偏见的风险,限制了其作为通用评测工具的适用范围。最终,尽管经过严格筛选,部分样本中仍可能存在残留的顺序依赖性歧义,这对评测结果的可靠性和解释性构成挑战。
常用场景
经典使用场景
在多模态智能领域,视觉-语言模型(VLM)在处理多图像输入时,其推理稳定性与位置敏感性成为评估模型鲁棒性的关键维度。MIPBench作为一个专为位置不变性多图像视觉问答设计的评估基准,其核心使用场景在于系统性地检测模型对图像排列顺序的敏感程度。通过提供近七千个精心筛选的位置不变性样本,涵盖五种任务类别与三种答案格式,研究者能够利用该基准在受控条件下观测模型在图像置换后答案是否发生偏移,从而量化其对输入顺序的依赖程度。这一经典评估范式为多图像推理能力的可靠性验证提供了标准化工具。
解决学术问题
MIPBench精准回应了当前视觉-语言模型研究中一个被长期忽视的学术问题——当输入图像的物理顺序发生改变而语义恒定时,模型是否能够保持判断的一致性。传统多图像评估指标往往仅关注最终答案的正确率,却忽略了模型对排列噪声的脆弱性。该数据集通过构建位置不变性子集的严格过滤流程,首次将位置偏差视为独立可测量的系统性误差来源。其对学术界的重要意义在于揭示了看似鲁棒的模型可能在隐蔽的顺序暗示下产生不一致响应,推动研究者从仅关注答案准确性转向兼顾推理稳定性的新评估范式,为模型架构优化提供了关键诊断依据。
衍生相关工作
MIPBench的发布催生了一系列围绕多图像位置鲁棒性的后续研究工作。学术界已开始基于该基准设计新的位置不变性训练策略,例如通过顺序随机化与对比学习增强模型对排列扰动的抗性。部分工作进一步扩展了MIPBench的评估维度,探索不同模态(如图文交错输入)中的顺序敏感性。此外,该基准中基于九个源数据集构建的位置不变性子集,已作为元数据被用于训练数据去偏方法的研究,推动开发者在构建大规模多图像语料库时主动过滤掉位置相关的虚假关联。这些衍生工作共同编织了一张围绕多图像推理可靠性的研究网络,持续拓展着该领域的技术边界。
以上内容由遇见数据集搜集并总结生成


