dataset-quality
收藏Hugging Face2025-03-19 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/TempestTeam/dataset-quality
下载链接
链接失效反馈官方服务:
资源简介:
该数据集设计用于训练模型对文本和代码数据的质量进行分类,能够区分不同的质量等级(从0:不适当或最低质量,到3:最高质量或高级内容)。质量评估是使用Qwen2.5-32B-Instruct-AWQ模型和链式思维(CoT)提示技术进行的,这使得对数据进行了细致的评估。
This dataset is designed for training models to classify the quality of text and code data, capable of distinguishing between different quality levels ranging from 0: Inappropriate or minimum quality, to 3: Highest quality or advanced content. Quality assessment was conducted using the Qwen2.5-32B-Instruct-AWQ model and Chain-of-Thought (CoT) prompting techniques, which enables meticulous evaluation of the data.
创建时间:
2025-03-17
搜集汇总
数据集介绍
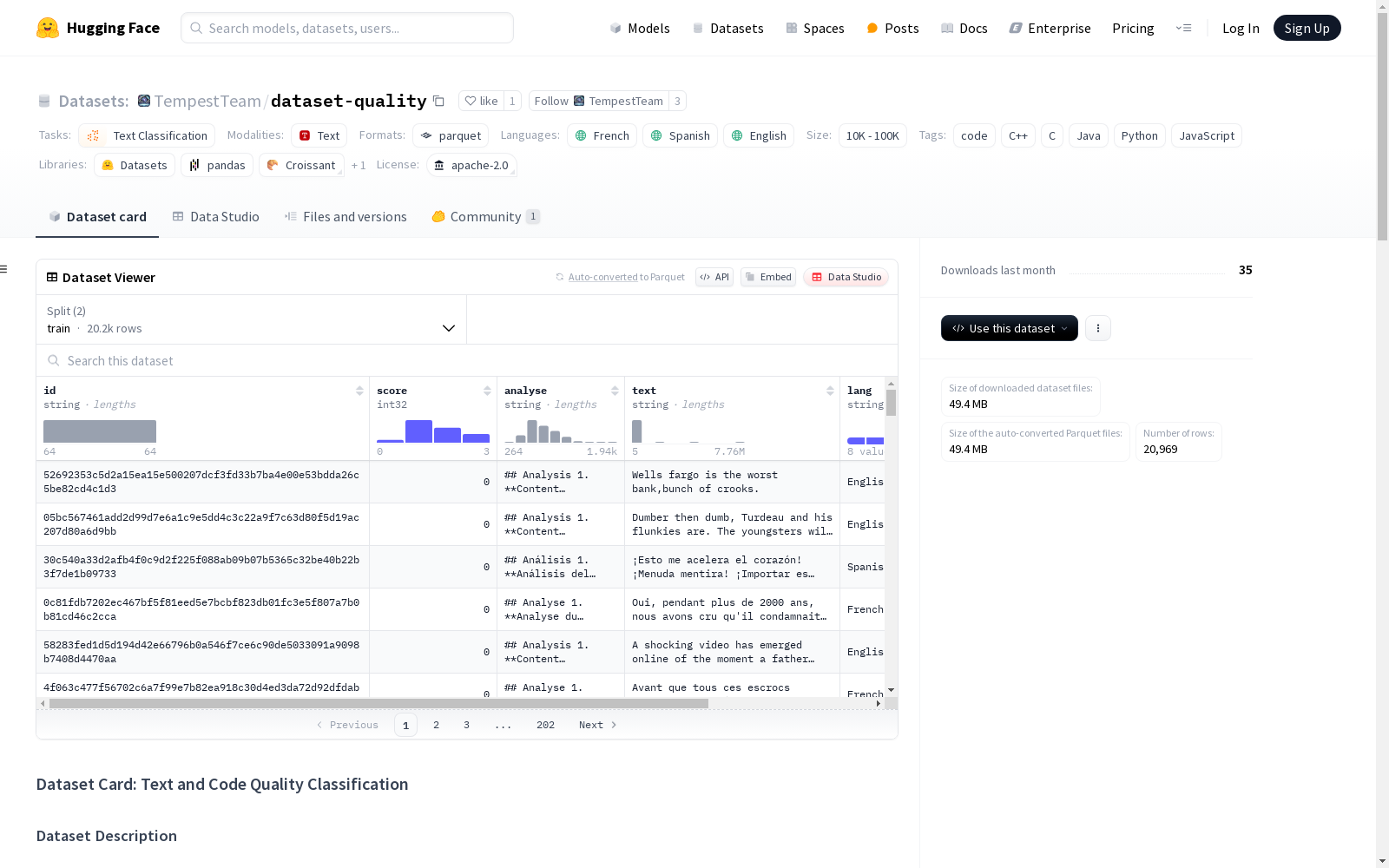
构建方式
该数据集的构建基于多语言文本和代码片段的质量分类任务,采用了Qwen2.5-32B-Instruct-AWQ模型进行质量评估。通过链式思维(CoT)提示技术,模型对文本和代码进行了细致的分析,并赋予其质量评分(0至3分)。数据来源包括FineWeb、FineWeb2和The-Stack-v2等公开数据集,涵盖了英语、法语、西班牙语以及多种编程语言(如C++、Python、Java等)。
使用方法
该数据集适用于训练自动化数据质量分类模型,尤其适用于自然语言处理(NLP)和代码分析任务。用户可以通过加载训练集(`train`)和验证集(`eval`)进行模型训练与评估。数据集的设计还支持过滤低质量数据,从而提升训练数据的整体质量。此外,该数据集还可用于基准测试和质量控制,帮助研究人员评估和改进模型的性能。
背景与挑战
背景概述
dataset-quality数据集由Hugging Face社区于近期发布,旨在为文本和代码质量分类任务提供高质量的训练数据。该数据集的核心研究问题在于如何通过自动化手段对文本和代码的质量进行分级,从而为自然语言处理(NLP)和代码分析领域提供更精确的数据支持。数据集采用了Qwen2.5-32B-Instruct-AWQ模型,结合链式思维(CoT)提示技术,对文本和代码进行了细致的质量评估。数据来源包括FineWeb、FineWeb2以及The-Stack-v2等知名数据集,涵盖英语、法语、西班牙语以及多种编程语言。该数据集的发布为数据质量过滤、模型训练以及基准测试提供了重要资源,推动了相关领域的研究进展。
当前挑战
dataset-quality数据集在构建和应用过程中面临多重挑战。首先,文本和代码的质量评估具有高度主观性,尽管采用了链式思维提示技术,但模型评估仍可能受到语言模型自身偏见的影响。其次,不同语言的语法和文化背景差异可能导致分类结果的不一致性,尤其是在多语言环境下,如何确保评估标准的统一性成为一大难题。此外,代码片段的评估不仅需要考虑可读性和算法效率,还需兼顾注释的质量,这对模型的综合判断能力提出了更高要求。最后,数据集的规模相对较小,可能限制了其在复杂任务中的泛化能力,未来需要进一步扩展数据量以提升模型的鲁棒性。
常用场景
经典使用场景
在自然语言处理和代码分析领域,dataset-quality数据集被广泛应用于训练模型以自动分类文本和代码的质量。通过使用链式思维(CoT)提示技术,该数据集能够对文本和代码进行细致的质量评估,从而帮助研究人员构建更精确的分类模型。特别是在多语言环境下,该数据集能够有效区分不同语言的文本质量,为跨语言研究提供了坚实的基础。
解决学术问题
dataset-quality数据集解决了自然语言处理和代码分析中的关键问题,即如何自动化和标准化文本与代码的质量评估。通过提供从0到3的质量评分,该数据集帮助研究人员克服了传统方法中主观性和不一致性的问题。此外,该数据集还为多语言环境下的质量评估提供了统一的框架,显著提升了跨语言研究的准确性和可靠性。
实际应用
在实际应用中,dataset-quality数据集被广泛用于过滤和提升训练数据的质量。例如,在构建大规模语言模型时,研究人员可以利用该数据集筛选出高质量的文本和代码,从而提高模型的训练效果。此外,该数据集还可用于代码审查工具的开发,帮助开发者识别和修复低质量的代码片段,提升软件开发的整体质量。
数据集最近研究
最新研究方向
近年来,随着自然语言处理(NLP)和代码分析技术的快速发展,数据集质量评估成为了一个备受关注的研究方向。dataset-quality数据集通过结合链式思维(CoT)提示技术,利用Qwen2.5-32B-Instruct-AWQ模型对文本和代码片段进行细致的质量分类,涵盖了从低质量到高质量的多层次评估。这一数据集不仅支持多语言(如英语、法语、西班牙语)和多种编程语言(如C++、Python、Java)的质量分析,还为自动化数据过滤和模型训练提供了重要基准。当前研究热点集中在如何进一步优化评估模型,减少语言和代码分析中的偏见,以及提升分类的准确性和泛化能力。该数据集的应用前景广泛,包括但不限于数据清洗、模型训练优化以及代码质量控制的自动化工具开发。
以上内容由遇见数据集搜集并总结生成


