PangeaBench-cvqa
收藏Hugging Face2024-11-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/neulab/PangeaBench-cvqa
下载链接
链接失效反馈官方服务:
资源简介:
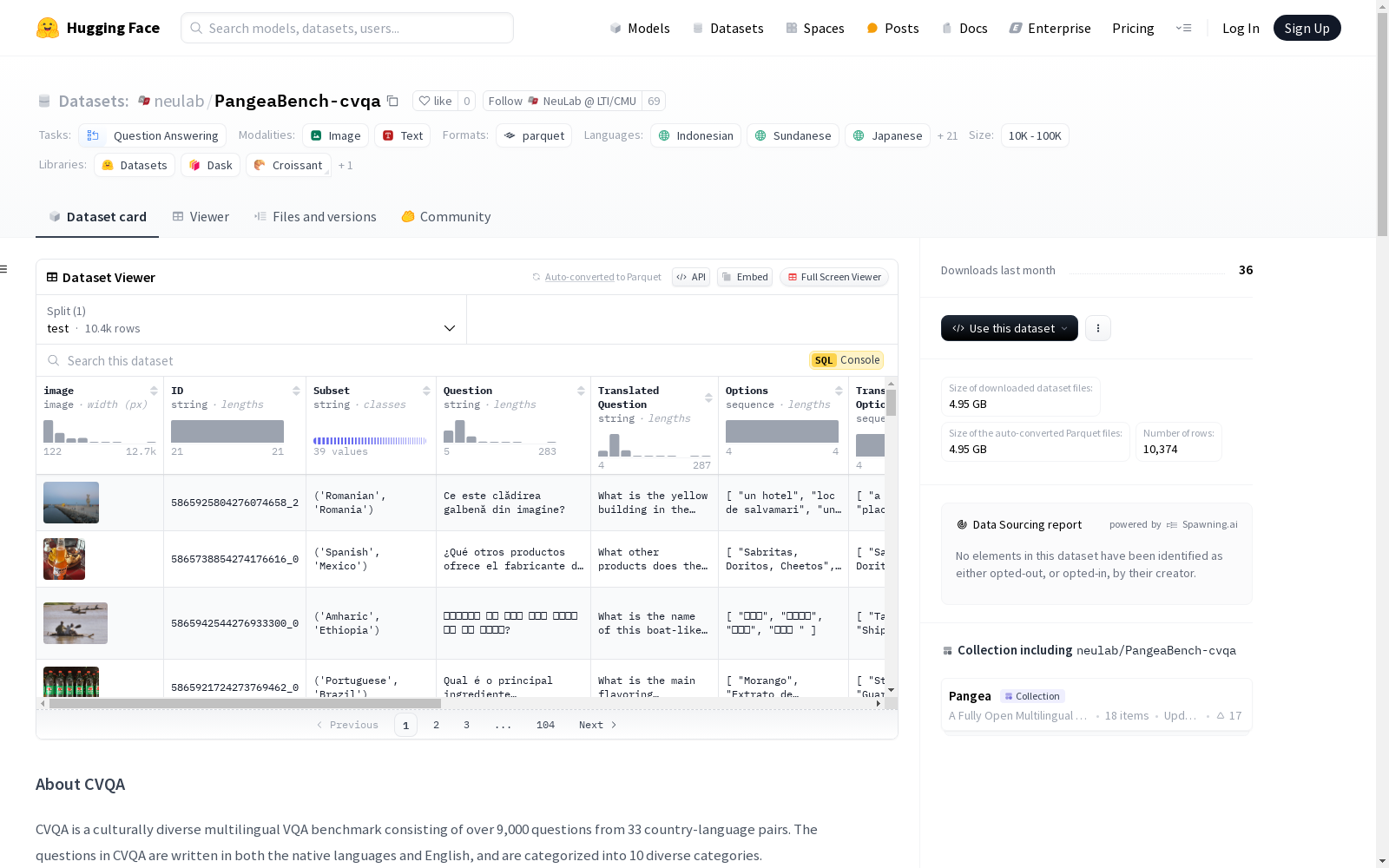
CVQA是一个多语言、多文化的视觉问答基准数据集,包含来自33个国家和地区对的超过9000个问题。问题以本地语言和英语书写,并分为10个不同的类别。数据集设计用于测试集,包含图像、问题、翻译问题、选项、翻译选项、标签、类别、图像类型、图像来源和许可证等字段。数据集的创建涉及问题制定和验证两个步骤,由熟练的注释者手工制作问题。注释者需要是相关语言的流利使用者,并且熟悉相关文化。数据集中的图像可以是基于现有外部图像或贡献者自己的图像,具有不同的许可类型。
CVQA is a multilingual, multicultural visual question answering (VQA) benchmark dataset containing over 9,000 questions originating from 33 countries and regions. All questions are written in both local languages and English, and fall into 10 distinct categories. This dataset is designed for evaluation purposes, and includes fields such as images, questions, translated questions, answer options, translated answer options, labels, categories, image types, image sources, and licenses. The construction of this dataset involves two key steps: question formulation and validation, with all questions manually crafted by skilled annotators. Annotators are required to be fluent speakers of the relevant languages and familiar with the corresponding cultural contexts. The images in the dataset can be either sourced from existing external materials or provided by contributors themselves, and are covered by various license types.
提供机构:
NeuLab @ LTI/CMU
创建时间:
2024-11-01
搜集汇总
数据集介绍
构建方式
PangeaBench-cvqa数据集的构建过程体现了跨文化多语言视觉问答的复杂性。该数据集由MBZUAI的研究团队主导,通过协作方式收集了来自33个国家-语言对的超过9,000个问题。数据集的图像来源包括外部图像和贡献者自拍图像,问题则由熟练的母语者手工编写,确保文化相关性和语言准确性。每个问题均包含一个正确答案和三个干扰项,并通过另一名注释者进行验证,以确保图像和问题符合指导原则。
特点
PangeaBench-cvqa数据集以其文化多样性和多语言特性著称,涵盖了33种国家-语言对,问题以本地语言和英语双语呈现,并分为10个不同类别。数据集中的图像类型分为自拍和外部来源,图像使用许可根据来源不同而有所区分。每个问题均附有详细的元数据,包括问题类别、图像类型、来源和许可信息,为研究者提供了丰富的上下文信息。
使用方法
PangeaBench-cvqa数据集专为测试集设计,适用于评估多语言视觉问答模型的性能。研究者可通过提交模型预测结果至指定平台进行性能评估。数据集的使用需注意每个问题的许可信息,确保在符合许可要求的范围内进行研究或商业应用。通过该数据集,研究者能够深入探索跨文化背景下的视觉问答任务,推动多语言人工智能技术的发展。
背景与挑战
背景概述
PangeaBench-cvqa数据集是由MBZUAI研究团队主导构建的一个多语言视觉问答(VQA)基准测试集,旨在评估模型在跨文化背景下的表现。该数据集涵盖了33种国家-语言对的9000多个问题,问题以本地语言和英语双语形式呈现,并分为10个不同的类别。通过这一数据集,研究者能够深入探讨模型在处理多语言和文化多样性问题时的能力,进一步推动视觉问答领域的发展。
当前挑战
PangeaBench-cvqa数据集在构建和应用过程中面临多重挑战。首先,数据集的跨文化特性要求问题必须具有文化敏感性,这对标注者的文化背景和语言能力提出了极高要求。其次,问题的设计需要确保其与图像的紧密关联,同时避免泄露答案的线索,这对标注和验证流程提出了严格的标准。此外,数据集的图像来源多样,涉及外部图像和贡献者自拍图像,需确保每张图像的版权和许可信息准确无误,这对数据管理和合规性提出了挑战。最后,多语言问题的翻译和选项设计需保持语义一致性,这对语言处理和模型评估提出了更高的技术要求。
常用场景
经典使用场景
PangeaBench-cvqa数据集在跨文化视觉问答(VQA)领域具有重要应用,尤其是在多语言和多文化背景下的视觉理解任务中。该数据集通过提供33种国家-语言对的超过9,000个问题,涵盖了10个不同的类别,为研究者提供了一个丰富的测试平台。经典的使用场景包括评估多语言视觉问答模型的性能,特别是在处理文化差异和语言多样性时的表现。
解决学术问题
PangeaBench-cvqa数据集解决了多语言视觉问答模型在跨文化背景下的性能评估问题。通过提供多种语言和文化背景的问题,该数据集帮助研究者更好地理解和改进模型在处理文化差异和语言多样性时的表现。此外,该数据集还为研究多语言模型的文化适应性提供了宝贵的数据支持,推动了跨文化视觉问答领域的研究进展。
衍生相关工作
PangeaBench-cvqa数据集衍生了一系列相关研究工作,特别是在多语言视觉问答模型的文化适应性研究方面。许多研究者利用该数据集开发了新的模型和算法,以提升模型在跨文化背景下的表现。此外,该数据集还促进了多语言视觉问答领域的标准化评估方法的发展,为后续研究提供了重要的参考和基准。
以上内容由遇见数据集搜集并总结生成


