orkg/SciQA
收藏Hugging Face2023-05-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/orkg/SciQA
下载链接
链接失效反馈官方服务:
资源简介:
SciQA数据集包含2,565个SPARQL查询与问题对,这些问题和查询是从开放研究知识图谱(ORKG)中获取的。数据集分为训练、验证和测试集,比例分别为70%、10%和20%。数据集的创建结合了手工制作和自动生成的问题和查询。
The SciQA dataset comprises 2,565 SPARQL query-question pairs extracted from the Open Research Knowledge Graph (ORKG). The dataset is split into training, validation, and test sets with a ratio of 70%, 10%, and 20% respectively. The construction of this dataset combines manually crafted question-query pairs and automatically generated ones.
提供机构:
orkg
原始信息汇总
数据集概述
数据集名称
- 名称: The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge
- 别名: SciQA
数据集基本信息
- 语言: 英语 (en)
- 许可证: Creative Commons Attribution 4.0 International License (CC BY 4.0)
- 多语言性: 单语种
- 大小: 1K<n<10K
- 来源: 原始数据
- 标签: 知识库问答 (knowledge-base-qa)
- 任务类别: 问答 (question-answering)
数据集内容
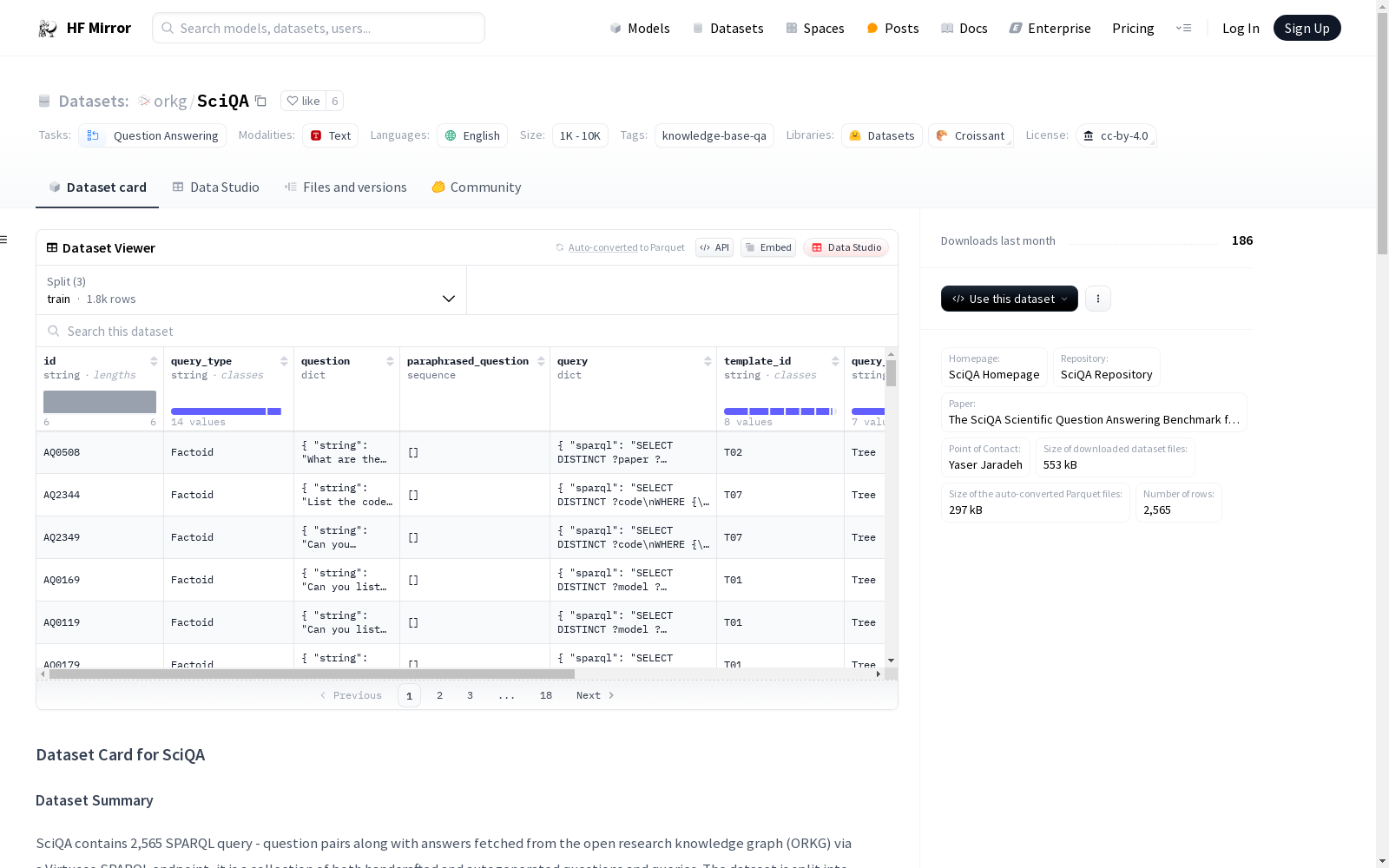
- 数据实例: 包含2,565个SPARQL查询-问题对及其答案,数据来源于开放研究知识图谱(ORKG)。
- 数据字段:
id: 问题IDquestion: 问题文本paraphrased_question: 问题的改写版本query: 回答问题的SPARQL查询query_type: 查询类型query_shape: 查询结构query_class: 查询类别auto_generated: 是否自动生成number_of_patterns: 查询中的图模式数量
数据集结构
- 数据分割: 训练集70%,验证集10%,测试集20%。
数据集创建
- 注释创建者: 专家生成和自动生成
- 语言创建者: 机器生成
附加信息
- 许可证信息: 数据集根据CC BY 4.0许可证发布。
- 引用信息: 数据集的引用格式和详细信息。
- 贡献者: 感谢@YaserJaradeh添加此数据集。
搜集汇总
数据集介绍
构建方式
SciQA数据集的构建采取了一种结合手工制作与自动生成的方式,首先由专家手工制作了100个复杂的科学问题,随后利用八个问题模板自动生成了额外的2465个问题。这些问题均可以借助开放研究知识图谱(ORKG)中的信息通过SPARQL查询得到答案。数据集被划分为70%的训练集、10%的验证集和20%的测试集,以适应不同的模型训练和评估需求。
使用方法
使用SciQA数据集时,研究者可以依据数据集提供的SPARQL查询和问题对进行模型训练和评估。数据集的结构包括问题ID、问题文本、问题重写版本、SPARQL查询、查询类型、查询模板、查询形状、查询类别、是否自动生成的问题以及查询模式数量等字段。用户应遵守数据集的许可协议,并在研究成果中引用数据集的详细信息。
背景与挑战
背景概述
SciQA(学术知识问答基准)是一个针对学术知识领域的问题回答数据集,创建于2023年,由Sören Auer、Dante A. C. Barone等研究人员共同开发。该数据集旨在通过开放研究知识图谱(ORKG)提供一个科学问题回答的基准,涵盖了近709个研究领域的近15,000篇学术论文的研究贡献。SciQA的构建采用了自底向上的方法,首先手工开发了100个复杂问题,然后通过八个问题模板自动生成了2,465个问题。这些问题及其对应的SPARQL查询覆盖了多个研究领域的不同问题类型,对相关领域的研究具有重要的推动作用。
当前挑战
SciQA数据集在构建过程中遇到了多个挑战:1)如何确保手工开发的问题与自动生成的问题在质量和难度上的一致性;2)如何处理知识图谱中的不完整和错误信息,以保证问题能够得到准确回答;3)数据集的多样性和覆盖面问题,以确保其能够适应不同研究领域的问题回答需求。此外,SciQA所解决的学术知识图谱问题回答领域,面临着如何提高系统对复杂科学问题的理解和回答能力,以及如何准确映射自然语言问题到结构化查询语言的挑战。
常用场景
经典使用场景
在科学知识领域,SciQA数据集被广泛用于构建和评估学术问答系统。其经典的使用场景在于,研究者通过该数据集训练模型,以实现对开放研究知识图谱(ORKG)中的科学问题进行准确回答。数据集中的问题-查询对,涵盖了从事实性问题到复杂问题等多种类型,使得SciQA成为科学问答领域的重要基准。
解决学术问题
SciQA数据集解决了学术研究中如何有效利用大规模科学知识图谱进行问题回答的难题。它为学术问答系统提供了一种评价标准,帮助研究者们在科学文献、研究贡献和学术领域等方面进行深入探索。SciQA的意义在于促进了学术知识问答技术的发展,提升了知识图谱在学术领域的应用价值。
实际应用
实际应用中,SciQA数据集的应用场景包括但不限于学术搜索引擎、智能问答系统以及科研助手等。这些应用能够帮助科研人员快速定位学术资源,促进科学研究的效率,同时也为普通用户提供了一种便捷的获取科学知识的方式。
数据集最近研究
最新研究方向
SciQA科学问题回答基准在学术知识领域具有显著的研究价值,其数据集结合了手动制作与自动生成的查询-问题对,旨在通过开放研究知识图谱(ORKG)促进科研领域的问答系统发展。近期研究聚焦于提升学术知识图谱的问答能力,尤其是针对复杂问题的回答准确性。SciQA的构建理念及其实践,对于推动知识图谱在学术领域的应用具有重要意义,不仅拓宽了知识图谱的应用范围,也为评估下一代问答系统性能提供了挑战性的基准。该数据集的发布,引发了学术界对于如何高效利用知识图谱进行学术问答研究的热烈讨论,为相关领域的研究提供了新的视角和工具。
以上内容由遇见数据集搜集并总结生成


