smugri-mt-bench
收藏Hugging Face2024-11-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tartuNLP/smugri-mt-bench
下载链接
链接失效反馈官方服务:
资源简介:
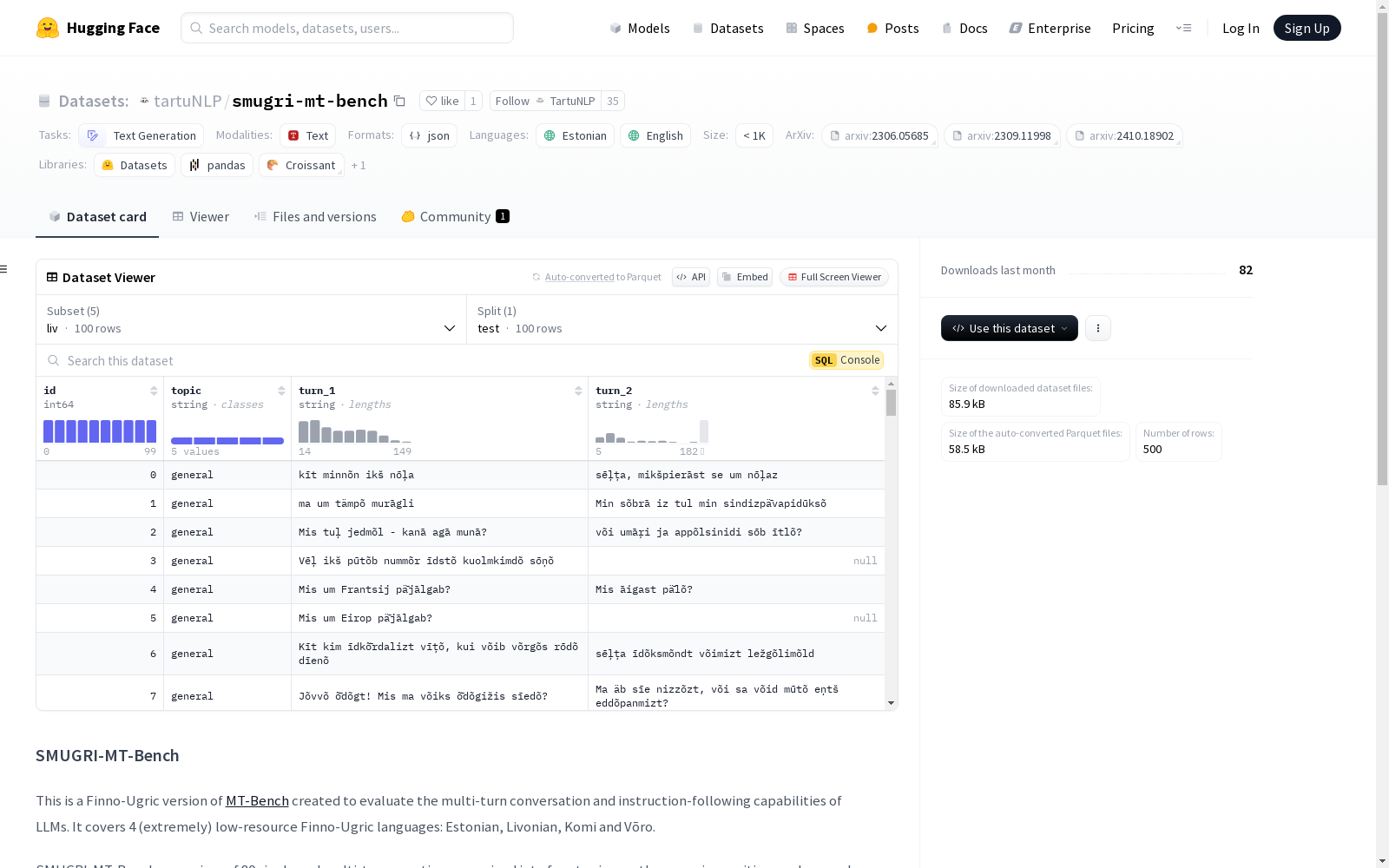
SMUGRI-MT-Bench数据集是一个用于评估大型语言模型在多轮对话和指令遵循能力方面的芬诺-乌戈尔语版本。它涵盖了四种极其低资源的芬诺-乌戈尔语言:爱沙尼亚语、利沃尼亚语、科米语和沃罗语。数据集包含80个单轮和多轮问题,分为四个主题:数学、推理、写作和一般。这些问题是从LMSYS-Chat-1M数据集中挑选出来的,并由这些语言的母语者手动翻译成爱沙尼亚语、沃罗语、科米语和利沃尼亚语。此外,数据集还包括每种语言的20个有害提示,以促进在极其低资源场景中识别和解决语言模型的潜在漏洞和偏差的研究。
The SMUGRI-MT-Bench dataset is a Finno-Ugric language benchmark designed for evaluating large language models' multi-turn dialogue and instruction-following abilities. It encompasses four extremely low-resource Finno-Ugric languages: Estonian, Livonian, Komi, and Võro. The dataset consists of 80 single-turn and multi-turn questions, categorized into four themes: mathematics, reasoning, writing, and general. These questions were sourced from the LMSYS-Chat-1M dataset and manually translated into the four aforementioned languages by native speakers. Additionally, the dataset includes 20 harmful prompts for each language, to promote research on identifying and resolving potential vulnerabilities and biases of language models in extremely low-resource scenarios.
提供机构:
TartuNLP创建时间:
2024-11-22
搜集汇总
数据集介绍
构建方式
SMUGRI-MT-Bench数据集旨在评估大语言模型在多轮对话和指令执行方面的能力,特别针对芬兰-乌戈尔语系中的低资源语言。该数据集包含80个单轮和多轮问题,涵盖数学、推理、写作和通用四个主题。这些问题从LMSYS-Chat-1M数据集中精心挑选,并由精通爱沙尼亚语、利沃尼亚语、科米语和沃罗语的语言专家手动翻译而成。此外,数据集还包含每种语言的20个有害提示,以促进在极低资源环境下识别和解决语言模型潜在漏洞和偏见的研究。
特点
SMUGRI-MT-Bench数据集的特点在于其专注于芬兰-乌戈尔语系中的低资源语言,包括爱沙尼亚语、利沃尼亚语、科米语和沃罗语。数据集中的问题设计既具有挑战性,又不要求人类具备专业知识,且翻译成其他语言在时间和内容上均可行。此外,数据集还特别包含了有害提示,为研究语言模型在低资源环境下的安全性和偏见提供了独特的数据支持。
使用方法
SMUGRI-MT-Bench数据集的使用方法主要围绕评估大语言模型在多轮对话和指令执行方面的表现。研究人员可以通过该数据集测试模型在低资源语言环境下的性能,特别是在数学、推理、写作和通用主题上的表现。此外,数据集中的有害提示可用于研究模型在识别和应对潜在漏洞和偏见方面的能力。使用该数据集时,建议参考相关论文以获取更详细的使用指南和背景信息。
背景与挑战
背景概述
SMUGRI-MT-Bench数据集由Taido Purason、Hele-Andra Kuulmets和Mark Fishel于2024年创建,旨在评估大语言模型在多轮对话和指令遵循任务中的表现,特别是在极低资源的芬兰-乌戈尔语系语言环境下。该数据集基于MT-Bench框架,涵盖了爱沙尼亚语、利沃尼亚语、科米语和沃罗语四种极低资源语言。数据集包含80个单轮和多轮问题,分为数学、推理、写作和通用四个主题,问题来源于LMSYS-Chat-1M数据集,并由这些语言的流利使用者手动翻译。此外,数据集还包含每种语言的20个有害提示,用于研究在极低资源场景下识别和解决语言模型潜在漏洞和偏见的问题。
当前挑战
SMUGRI-MT-Bench数据集面临的挑战主要来自两方面。首先,在领域问题方面,该数据集旨在解决极低资源语言环境下大语言模型的多轮对话和指令遵循能力评估问题,然而,由于这些语言的资源极度匮乏,模型在这些语言上的表现往往难以达到高资源语言的水平,如何有效提升模型在低资源语言上的性能是一个重要挑战。其次,在构建过程中,数据集的设计需要确保问题既对语言模型具有挑战性,又不要求人类具备专业知识,同时还需保证翻译的可行性和内容的准确性,这对翻译人员的选择和翻译质量的控制提出了较高要求。
常用场景
经典使用场景
SMUGRI-MT-Bench数据集在自然语言处理领域中被广泛应用于评估多轮对话和指令跟随能力,特别是在极低资源的芬兰-乌戈尔语系语言环境中。该数据集通过精心挑选的数学、推理、写作和通用主题问题,为研究人员提供了一个标准化的测试平台,用于衡量语言模型在复杂任务中的表现。
衍生相关工作
基于SMUGRI-MT-Bench数据集,研究人员已经开展了一系列相关研究,特别是在低资源语言的多轮对话和指令跟随领域。这些研究不仅扩展了语言模型的应用范围,还为其他低资源语言的自然语言处理研究提供了宝贵的参考和借鉴。
数据集最近研究
最新研究方向
在低资源语言处理领域,SMUGRI-MT-Bench数据集的推出为研究多轮对话和指令跟随能力提供了新的视角。该数据集特别关注爱沙尼亚语、利沃尼亚语、科米语和沃罗语等极低资源的芬兰-乌戈尔语系语言,填补了这些语言在自然语言处理研究中的空白。通过精心挑选并手动翻译的80个单轮和多轮问题,涵盖了数学、推理、写作和通用话题,该数据集不仅挑战了语言模型的极限,也为跨语言翻译和模型适应性研究提供了宝贵资源。此外,每种语言包含的20个有害提示,进一步推动了在低资源环境下识别和解决语言模型潜在漏洞和偏见的研究。这一数据集的发布,无疑将促进极低资源语言处理技术的发展,为全球语言多样性的保护和研究提供了新的工具和视角。
以上内容由遇见数据集搜集并总结生成


