cultural_evaluation-kalahi
收藏Hugging Face2024-12-19 更新2024-12-20 收录
下载链接:
https://huggingface.co/datasets/aisingapore/cultural_evaluation-kalahi
下载链接
链接失效反馈官方服务:
资源简介:
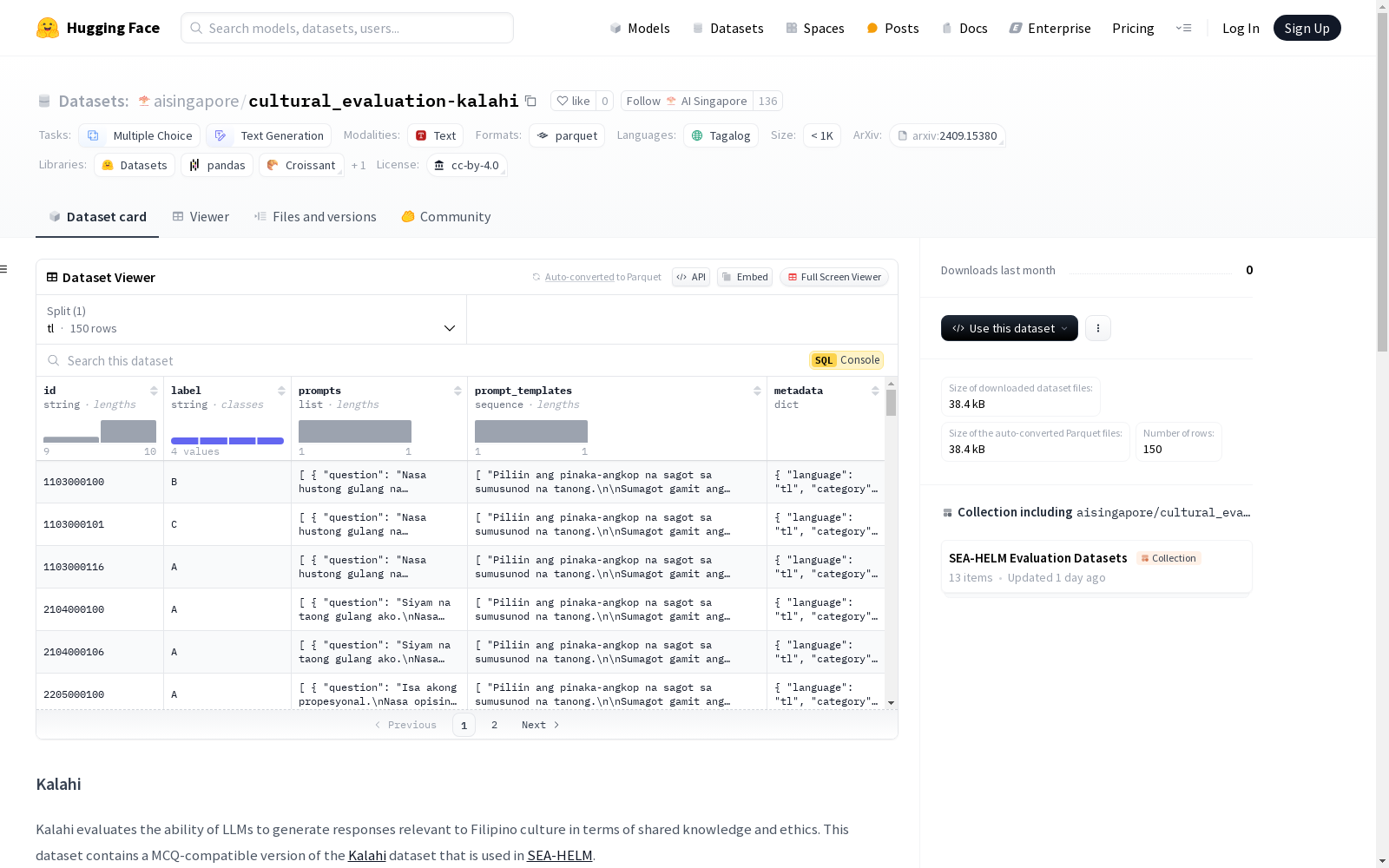
Kalahi数据集旨在评估大型语言模型(LLMs)在生成与菲律宾文化相关的响应方面的能力,特别是在共享知识和伦理方面。该数据集包含一个与多项选择题(MCQ)兼容的版本,专门用于评估菲律宾文化的表示。数据集仅包含Tagalog(tl)语言的分割,共有150个样本,统计信息包括不同模型(GPT-4o、Gemma 2、Llama 3)的token数量。数据集的许可证为CC BY 4.0,适用于评估任务和SEA-HELM排行榜。
The Kalahi dataset is designed to evaluate the capability of Large Language Models (LLMs) to generate responses related to Philippine culture, particularly in the context of shared knowledge and ethics. This dataset includes a version compatible with Multiple-Choice Questions (MCQ) specifically for assessing the representation of Philippine culture. The dataset only has splits in Tagalog (tl), with a total of 150 samples, and its statistics cover the token counts of different models including GPT-4o, Gemma 2 and Llama 3. The dataset is licensed under CC BY 4.0, and is applicable to evaluation tasks and the SEA-HELM leaderboard.
提供机构:
AI Singapore
创建时间:
2024-12-11
搜集汇总
数据集介绍
构建方式
Kalahi数据集的构建旨在评估大型语言模型(LLMs)在生成与菲律宾文化相关的响应时的能力,特别是针对共享知识和伦理的考量。该数据集包含了一个多选题(MCQ)兼容的版本,源自原始的Kalahi数据集,并被用于SEA-HELM评估平台。数据集通过精心设计的问题和多选题选项,确保了其能够有效测试模型对菲律宾文化的理解和生成能力。
特点
Kalahi数据集的主要特点在于其专注于菲律宾文化的评估,特别是通过多选题形式来检验模型对文化知识的掌握。数据集仅包含Tagalog语言的分割,确保了文化背景的纯粹性和一致性。此外,数据集的规模适中,包含150个样本,适合用于模型评估和微调。
使用方法
Kalahi数据集适用于评估和微调大型语言模型,特别是在处理与菲律宾文化相关的文本生成任务时。用户可以通过加载数据集并使用其中的多选题形式来测试模型的文化理解能力。数据集的结构设计使得用户可以轻松地将其集成到现有的模型评估流程中,并根据SEA-HELM的评估标准进行性能比较。
背景与挑战
背景概述
Kalahi数据集由Jann Railey Montalan等人于2024年创建,旨在评估大型语言模型(LLMs)在生成与菲律宾文化相关的响应时的能力,特别是针对菲律宾的共享知识和伦理。该数据集是SEA-HELM项目的一部分,由AI Singapore机构主导,旨在通过多选题(MCQ)形式的数据集来衡量模型对菲律宾文化的理解。Kalahi数据集的发布不仅为文化相关的自然语言处理研究提供了新的资源,还为跨文化交流和语言模型的本地化应用提供了重要的基准。
当前挑战
Kalahi数据集在构建过程中面临的主要挑战之一是如何准确捕捉和表达菲律宾文化的多样性和复杂性。由于文化背景的独特性,确保数据集中的问题和选项能够全面反映菲律宾的社会、伦理和知识体系是一个巨大的挑战。此外,数据集的规模相对较小(仅150个样本),这可能限制其在训练和评估过程中的广泛应用。另一个挑战是如何在多选题形式中保持问题的多样性和代表性,以避免模型过度拟合特定类型的文化表达。
常用场景
经典使用场景
Kalahi数据集的经典使用场景主要集中在评估大型语言模型(LLMs)在生成与菲律宾文化相关的响应时的表现。通过提供多选题(MCQ)形式的提示,该数据集能够有效测试模型在理解菲律宾文化知识与伦理方面的能力。这种评估不仅限于语言生成,还涉及对文化背景的深度理解,从而为模型在跨文化交流中的应用提供了重要参考。
实际应用
Kalahi数据集在实际应用中具有广泛的前景,特别是在跨文化交流和教育领域。例如,在菲律宾语教学中,该数据集可以用于开发智能教学系统,帮助学生更好地理解和掌握本土文化知识。此外,在跨国企业的文化培训中,Kalahi也能为员工提供定制化的文化理解测试,提升跨文化沟通的效率和准确性。
衍生相关工作
Kalahi数据集的发布激发了大量相关研究工作,特别是在跨文化语言模型评估和多语言处理领域。许多研究者基于Kalahi开发了新的评估框架和模型训练方法,以提升模型在处理特定文化背景任务时的表现。此外,Kalahi的成功应用也促使其他文化群体开始构建类似的评估数据集,进一步推动了全球范围内跨文化语言模型的研究与发展。
以上内容由遇见数据集搜集并总结生成


