NHR-Edit
收藏arXiv2025-07-19 更新2025-07-22 收录
下载链接:
https://riko0.github.io/No-Humans-Required/
下载链接
链接失效反馈官方服务:
资源简介:
NHR-Edit是一个开放的数据集,包含358,000个经过严格验证的三元组,用于高保真度的图像编辑训练。该数据集由Layer Team和SALUTEDEV创建,旨在解决图像编辑中缺乏高质量三元组数据的问题。数据集内容涵盖了多个领域、分辨率、指令复杂性和风格,旨在帮助训练模型更好地理解和执行自然语言指令。创建过程中使用了自动化的模块化流程,无需人类干预,并通过内置的Gemini验证器直接对指令遵守程度和美观度进行评分。该数据集可用于解决图像编辑中存在的复杂问题,如物体删除、风格转换等,有助于推动基于自然语言指令的图像编辑研究。
NHR-Edit is an open dataset containing 358,000 rigorously validated triplets for high-fidelity image editing training. Developed by Layer Team and SALUTEDEV, this dataset aims to address the shortage of high-quality triplet data in image editing. Covering diverse domains, resolutions, instruction complexities and styles, the dataset is designed to assist models in better understanding and executing natural language instructions. Its creation adopts an automated modular workflow without human intervention, and directly scores instruction adherence and aesthetic quality via the built-in Gemini validator. This dataset can be used to tackle complex issues in image editing, such as object removal, style transfer and more, and helps advance research on natural language instruction-based image editing.
提供机构:
Layer Team, SALUTEDEV
创建时间:
2025-07-19
原始信息汇总
No Humans Required (NHR) 数据集概述
数据集简介
- 名称: No Humans Required (NHR)
- 核心成果: NHR-Edit 数据集
- 目标: 为高级图像编辑模型的训练和评估提供高质量、像素级完美的图像编辑序列
关键创新
- 全自动流程: 消除传统数据集中人工标注的偏见和低效问题
- 技术栈:
- 视觉语言模型(VLMs)
- 文本到图像生成器(Text2Image)
- 大语言模型(LLMs)
- 其他先进AI范式
生成流程
-
起点生成:
- 使用Flux1.schnell模型生成高质量输入图像
- 采用OpenAI O3作为顶级LLM
-
自动序列延续:
- LLM生成复杂编辑指令
- 高级图像编辑模型执行编辑操作
-
智能过滤与质量控制:
- 使用SOTA模型评估图像编辑对的质量
- 确保编辑准确反映指令并保持视觉保真度
-
可扩展性与多样性:
- 无需人工干预的持续数据生成能力
- 支持创建针对特定研究需求的大规模多样化数据集
自主数据集生成管道
- LLM生成多样化图像编辑任务提示
- 使用Flux1.dev模型生成初始图像
- 专有DiT模型执行图像编辑
- Qwen模型进行质量评估(像素级精度/指令遵循/美学)
- 使用反转和引导组合操作进行强增强
- 基于反转或组合质量进行反向一致性过滤
衍生成果
- Bagel-NHR-Edit:
- 基于NHR-Edit微调的LoRA变体
- 在ImgEditBench和GEdit-Bench上表现优于基础模型
相关文献
Kuprashevich, M., et al. (2025). NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining. arXiv. [https://arxiv.org/abs/2507.14119]
搜集汇总
数据集介绍
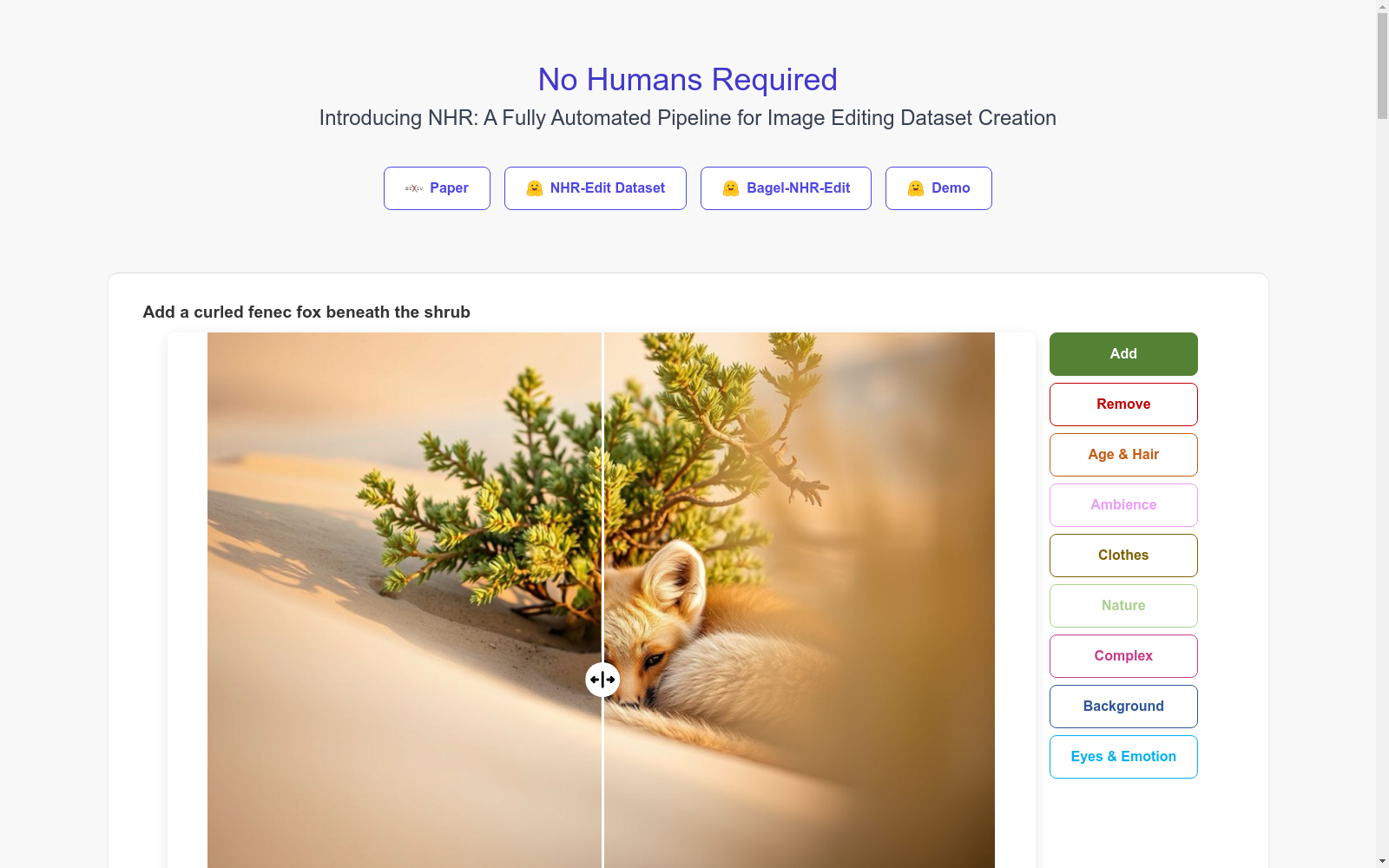
构建方式
NHR-Edit数据集通过自动化、模块化的流水线构建,利用公开生成模型生成高质量的三元组⟨原始图像、指令、编辑后图像⟩。该流水线包括提示工程模块、文本到图像生成器、指令引导的图像编辑器和多阶段验证堆栈,确保编辑质量。通过反转和组合引导,数据集规模扩大了约2.2倍,实现了无需人工标注的大规模高质量训练数据。
特点
NHR-Edit数据集包含358k个高质量三元组,覆盖多种编辑操作,如对象添加、移除、替换和风格调整等。其特点在于编辑指令的多样性和复杂性,能够处理多部分指令,如同时执行添加、删除和全局风格变化。此外,数据集还包含多种图像风格和分辨率,确保真实世界的多样性。
使用方法
NHR-Edit数据集适用于训练和评估指令引导的图像编辑模型。用户可以通过加载数据集中的三元组,输入原始图像和编辑指令,生成编辑后的图像。此外,数据集还可用于模型自我改进,通过生成新的训练数据来优化模型性能。具体使用时,建议结合多阶段验证堆栈,确保编辑质量和指令遵循性。
背景与挑战
背景概述
NHR-Edit数据集由Layer Team和SALUTEDEV团队于2025年7月发布,旨在解决生成式模型在自然语言指令引导的图像编辑任务中面临的高质量训练数据稀缺问题。该数据集通过自动化流程构建了358,000组严格验证的三元组⟨原始图像, 编辑指令, 编辑后图像⟩,突破了传统人工标注的规模限制。其创新性地利用预训练编辑模型自生成数据,结合基于Gemini的专用验证器进行质量筛选,支持复杂指令编辑、风格迁移和对象操作等多维度任务,成为当前指令引导图像编辑领域规模最大且质量最优的开放数据集。
当前挑战
NHR-Edit需应对双重挑战:在领域层面,需确保编辑结果精准遵循指令要求(如仅修改指定区域、保持物理合理性和风格一致性),同时克服生成模型常见的语义漂移和细节失真问题;在构建层面,面临自动化流水线的三大技术瓶颈——缺乏可靠的编辑质量评估指标、多模型级联导致的误差累积,以及合成数据与真实场景的分布差距。特别地,其验证模块需在无参考图像条件下检测细微编辑缺陷,这对传统视觉评估方法提出了革新性要求。
常用场景
经典使用场景
在计算机视觉领域,NHR-Edit数据集为基于自然语言指令的图像编辑任务提供了高质量的训练样本。该数据集通过自动化流程生成大量⟨原始图像,编辑指令,编辑后图像⟩三元组,特别适用于训练和评估生成模型在复杂编辑任务中的表现。其经典使用场景包括但不限于对象添加与移除、风格转换、背景替换等任务,为研究人员提供了丰富的实验素材。
衍生相关工作
该数据集已衍生出多个重要研究工作,最典型的是BAGEL-NHR-EDIT模型,这是基于NHR-Edit数据对BAGEL模型进行LoRA微调的变体,在ImgEdit-Bench和GEdit-Bench等基准测试中表现出色。此外,其自动化数据挖掘方法论为后续研究如OmniEdit、AnyEdit等提供了技术范式,推动了自改进生成模型领域的发展。数据集包含的35.8万高质量三元组也成为评估图像编辑模型的新标准。
数据集最近研究
最新研究方向
在生成式模型快速发展的背景下,NHR-Edit数据集为基于自然语言指令的图像编辑任务提供了高质量的三元组数据⟨原始图像, 指令, 编辑后图像⟩。该数据集通过自动化流水线挖掘跨领域、分辨率和风格的高保真样本,解决了传统方法依赖人工标注和外部工具链的局限性。前沿研究聚焦于三个方面:首先,利用生成模型自身能力构建自改进的数据挖掘框架,通过多轮编辑迭代和严格验证筛选优质样本;其次,开发基于Gemini模型微调的专用验证器,显著提升了编辑质量评估的准确性;最后,探索数据增强技术如语义反转和组合引导,将数据集规模扩大约2.2倍。该数据集在跨数据集评估中表现优异,推动了指令引导图像编辑模型的自监督微调和偏好优化研究,为构建无需人类干预的持续学习系统提供了重要基础设施。
相关研究论文
- 1NoHumansRequired: Autonomous High-Quality Image Editing Triplet MiningLayer Team, SALUTEDEV · 2025年
以上内容由遇见数据集搜集并总结生成


