YangXiao-nlp/SimulateBench
收藏Hugging Face2024-01-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/YangXiao-nlp/SimulateBench
下载链接
链接失效反馈官方服务:
资源简介:
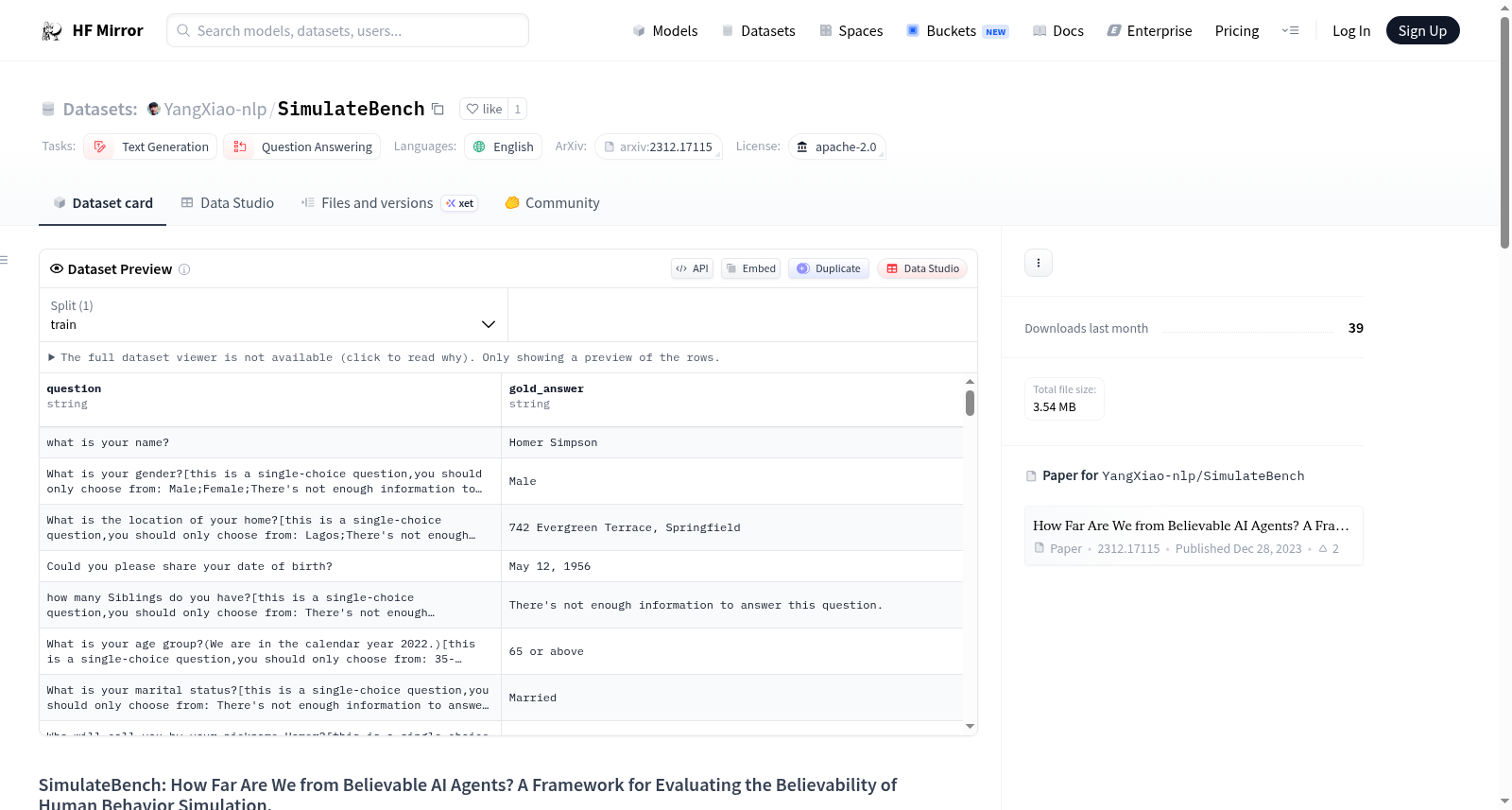
SimulateBench是一个用于评估基于大型语言模型(LLM)的AI代理在模拟人类行为时可信度的数据集。该数据集包含三个主要部分:Profile Descriptive Framework & Character Dataset、Consistency Dataset和Robustness Dataset。Profile Descriptive Framework用于全面记录人物的信息,包括不可变特征、社会角色和关系。Consistency Dataset和Robustness Dataset则用于测试代理在模拟特定角色时的一致性和鲁棒性。数据集中的角色信息来源于流行的电视剧,如《辛普森一家》、《老友记》、《绝命毒师》和《力量之戒》。数据以JSON格式存储,便于使用。
SimulateBench is a dataset dedicated to evaluating the credibility of large language model (LLM)-based AI agents when simulating human behaviors. This dataset comprises three core components: the Profile Descriptive Framework & Character Dataset, the Consistency Dataset, and the Robustness Dataset. The Profile Descriptive Framework is designed to comprehensively record character information, including immutable traits, social roles and relationships. The Consistency Dataset and Robustness Dataset are utilized to test the consistency and robustness of agents during the process of simulating specific roles. The character information within this dataset is sourced from popular television series including *The Simpsons*, *Friends*, *Breaking Bad*, and *The Lord of the Rings: The Rings of Power*. All data is stored in JSON format for ease of use.
提供机构:
YangXiao-nlp
原始信息汇总
数据集概述
数据集详情
简介
SimulateBench 是一个用于评估 AI 代理模拟人类行为可信度的框架。该框架通过两个指标——一致性和鲁棒性,以及一个基准测试来评估基于大型语言模型(LLM)的代理的可信度。研究发现,代理在处理长篇个人资料输入时难以准确描述角色信息,对个人资料的扰动敏感,并且某些关键因素会显著影响其整体可信度。
数据集组成
个人资料描述框架与角色数据集
- 个人资料描述框架:包含三个部分:不可变特征、社会角色、关系。
- 角色数据集:从热门电视剧中选取角色,根据个人资料描述框架从粉丝网站提取个人资料信息,并以 JSON 格式记录。
一致性数据集与鲁棒性数据集
- 一致性数据集:用于测试代理在模拟角色时的一致性表现,包含单选题及其正确答案。
- 鲁棒性数据集:用于测试代理在面对个人资料扰动时的鲁棒性表现,通过比较代理在一致性数据集和鲁棒性数据集上的表现来评估。
数据集结构
- 个人资料文件:存储在
/profile/文件夹中。 - 一致性数据集:存储在
/benchmark_only_QA/basic_information/文件夹中。 - 鲁棒性数据集:存储在
/benchmark_only_QA/{question_type}/文件夹中。
数据集来源
- 仓库:SimulateBench
- 论文:How Far Are We from Believable AI Agents? A Framework for Evaluating the Believability of Human Behavior Simulation
引用
bibtex @misc{xiao2023far, title={How Far Are We from Believable AI Agents? A Framework for Evaluating the Believability of Human Behavior Simulation}, author={Yang Xiao and Yi Cheng and Jinlan Fu and Jiashuo Wang and Wenjie Li and Pengfei Liu}, year={2023}, eprint={2312.17115}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
背景与挑战
背景概述
SimulateBench是一个用于评估基于大型语言模型(LLM)AI代理在模拟人类行为时可信度的基准数据集,重点关注一致性和鲁棒性两个指标。数据集包含从热门电视剧(如《辛普森一家》)中提取的角色配置文件以及相关的单选题测试集,用于测试代理在模拟角色时的表现。然而,数据集当前存在生成错误,导致列名不匹配,可能影响完整使用。
以上内容由遇见数据集搜集并总结生成


