SEED-Data-Edit - 指令引导的图像编辑混合数据集
收藏Hugging Face2024-12-12 收录
下载链接:
https://huggingface.co/datasets/AILab-CVC/SEED-Data-Edit
下载链接
链接失效反馈官方服务:
资源简介:
SEED-Data-Edit是腾讯发布的一个指令引导的图像编辑数据集。该数据集由三种不同类型的数据组成:自动化流水线产生的高质量编辑数据、从互联网收集的真实世界场景数据以及由Photoshop专家注释的高精度多轮编辑数据。数据集总量超过了350万个图像编辑对。该数据集广泛应用于图像编辑领域,特别是需要精确理解和执行编辑指令的复杂任务,如对象添加、风格转换等,其为训练语言引导的图像编辑模型提供了宝贵的资源。
SEED-Data-Edit is an instruction-guided image editing dataset released by Tencent. This dataset comprises three distinct types of data: high-quality editing data generated via automated pipelines, real-world scene data collected from the Internet, and high-precision multi-turn editing data annotated by Photoshop experts. The total scale of the dataset exceeds 3.5 million image editing pairs. This dataset is widely applied in the field of image editing, especially for complex tasks that require precise understanding and execution of editing instructions such as object addition and style transfer, and it serves as a valuable resource for training language-guided image editing models.
提供机构:
腾讯
创建时间:
2024-05-07
搜集汇总
数据集介绍
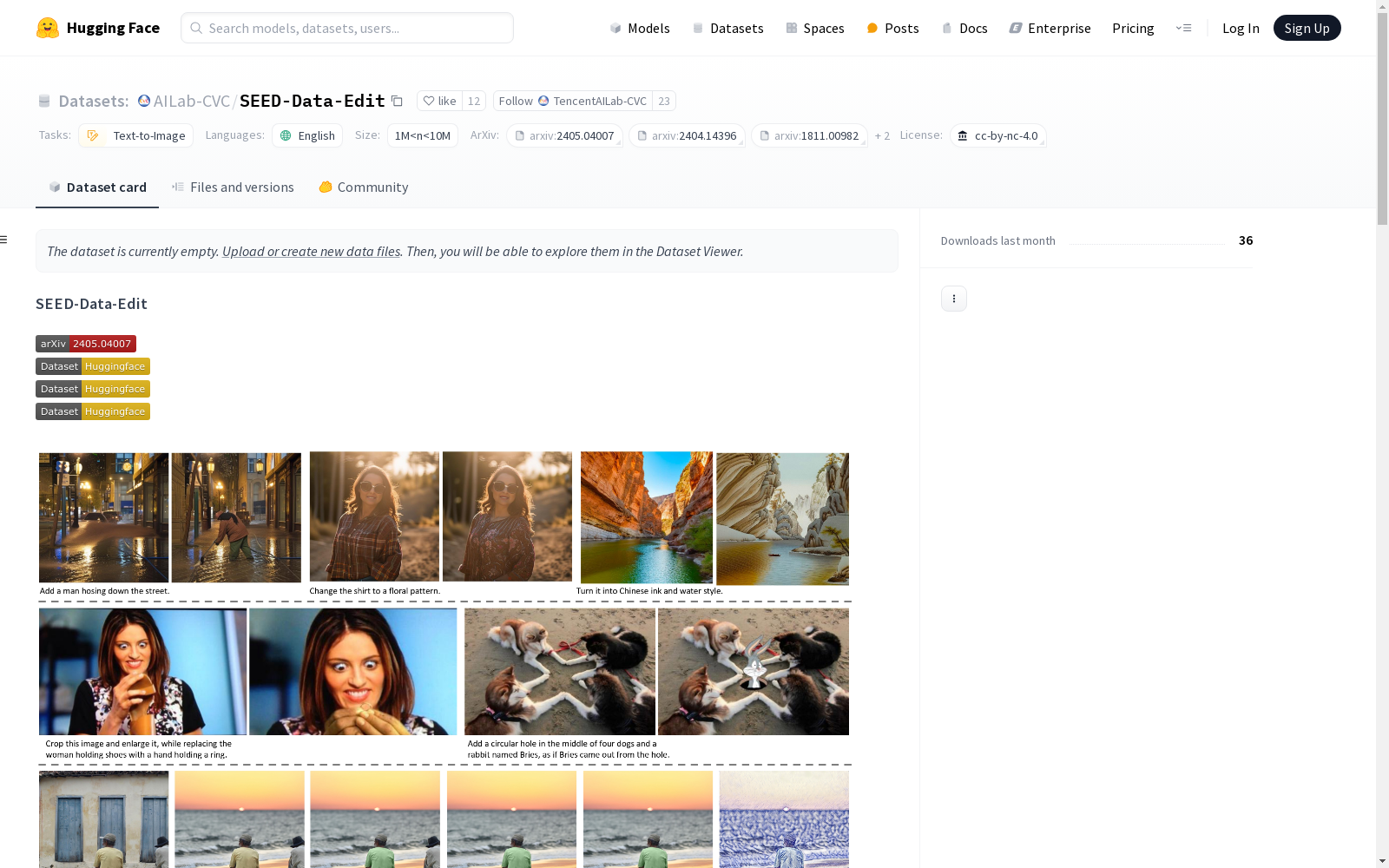
构建方式
SEED-Data-Edit数据集的构建采用了混合数据源的方式,涵盖了自动化生成、互联网收集以及人工标注三种主要途径。具体而言,Part-1部分通过自动化管道生成了大规模高质量的图像编辑对,总计350万对;Part-2部分则从互联网上收集了真实场景下的图像编辑数据,共计5.2万对;Part-3部分则通过人工标注的方式生成了高精度的多轮编辑数据,包含9.5万对编辑数据,涉及2.1万轮多轮编辑,最多可达5轮。
特点
SEED-Data-Edit数据集的特点在于其多样性和高质量。首先,数据集涵盖了从自动化生成到人工标注的多种数据来源,确保了数据的广泛性和代表性。其次,数据集特别注重多轮编辑的复杂性,提供了多达5轮的多轮编辑数据,能够有效支持复杂的图像编辑任务。此外,数据集的规模庞大,总计370万对图像编辑数据,为模型训练提供了丰富的资源。
使用方法
SEED-Data-Edit数据集的使用方法较为灵活,用户可以根据需求选择下载不同部分的数据。数据集分为三个部分,分别对应自动化生成、互联网收集和人工标注的数据。用户可以通过HuggingFace平台分别下载Part-1、Part-2和Part-3的数据。此外,数据集还提供了与SEED-X-Edit模型的结合使用指南,用户可以通过该模型进行图像编辑任务的推理。数据集的使用需遵循CC-BY-NC-4.0许可协议,仅限于非商业研究用途。
背景与挑战
背景概述
SEED-Data-Edit是由AILab-CVC团队于2024年发布的一个混合数据集,专注于指令引导的图像编辑任务。该数据集包含3.7百万对图像编辑数据,分为三个部分:自动化管道生成的大规模高质量编辑数据、从互联网收集的真实场景数据以及人工标注的高精度多轮编辑数据。SEED-Data-Edit的发布旨在推动图像编辑领域的研究,特别是在基于自然语言指令的图像编辑任务中,为模型训练和评估提供了丰富的资源。该数据集的研究背景源于对图像生成与编辑技术的需求,尤其是在多模态任务中,如何通过自然语言指令精确控制图像编辑过程成为了核心研究问题。SEED-Data-Edit的发布为相关领域的研究者提供了重要的数据支持,推动了图像编辑技术的进一步发展。
当前挑战
SEED-Data-Edit在解决图像编辑领域的挑战中面临多重困难。首先,指令引导的图像编辑任务要求模型能够准确理解自然语言指令并将其转化为具体的图像操作,这对模型的语义理解能力和图像生成能力提出了极高要求。其次,数据集的构建过程也面临诸多挑战,例如自动化管道生成的数据需要确保编辑质量与多样性,而真实场景数据的收集则需解决版权与隐私问题。此外,人工标注的多轮编辑数据虽然精度高,但标注成本与时间消耗巨大。这些挑战不仅体现在数据集的构建中,也直接影响了下游任务模型的性能优化与泛化能力。
常用场景
经典使用场景
SEED-Data-Edit数据集在图像编辑领域具有广泛的应用,尤其是在指令引导的图像编辑任务中。该数据集通过自动化管道生成的大规模高质量编辑数据、从互联网收集的真实场景数据以及人工标注的高精度多轮编辑数据,为研究人员提供了丰富的实验素材。经典使用场景包括图像修复、风格迁移、对象替换等任务,这些任务依赖于精确的指令和高质量的图像对,以生成符合预期的编辑结果。
衍生相关工作
SEED-Data-Edit数据集催生了一系列相关研究工作,尤其是在图像生成和编辑模型的优化方面。基于该数据集训练的SEED-X-Edit模型在指令引导的图像编辑任务中表现出色,成为该领域的标杆模型之一。此外,许多研究团队利用该数据集进一步探索了多模态学习、图像语义理解以及跨模态生成等前沿课题,推动了图像编辑技术的快速发展。
数据集最近研究
最新研究方向
近年来,随着生成式人工智能技术的迅猛发展,指令引导的图像编辑成为计算机视觉领域的热点研究方向。SEED-Data-Edit作为混合数据集,通过自动化流水线生成的大规模高质量编辑数据、互联网采集的真实场景数据以及人工标注的高精度多轮编辑数据,为图像编辑任务提供了丰富的训练资源。该数据集不仅推动了基于文本指令的图像编辑模型的优化,还为多轮交互式编辑任务的研究提供了重要支持。结合SEED-X-Edit模型的应用,SEED-Data-Edit在图像生成与编辑的精度和可控性方面展现了显著优势,为艺术创作、广告设计等领域的智能化转型提供了技术基础。
以上内容由遇见数据集搜集并总结生成


