scikit-fingerprints/MoleculeNet_ToxCast
收藏Hugging Face2024-07-18 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/scikit-fingerprints/MoleculeNet_ToxCast
下载链接
链接失效反馈官方服务:
资源简介:
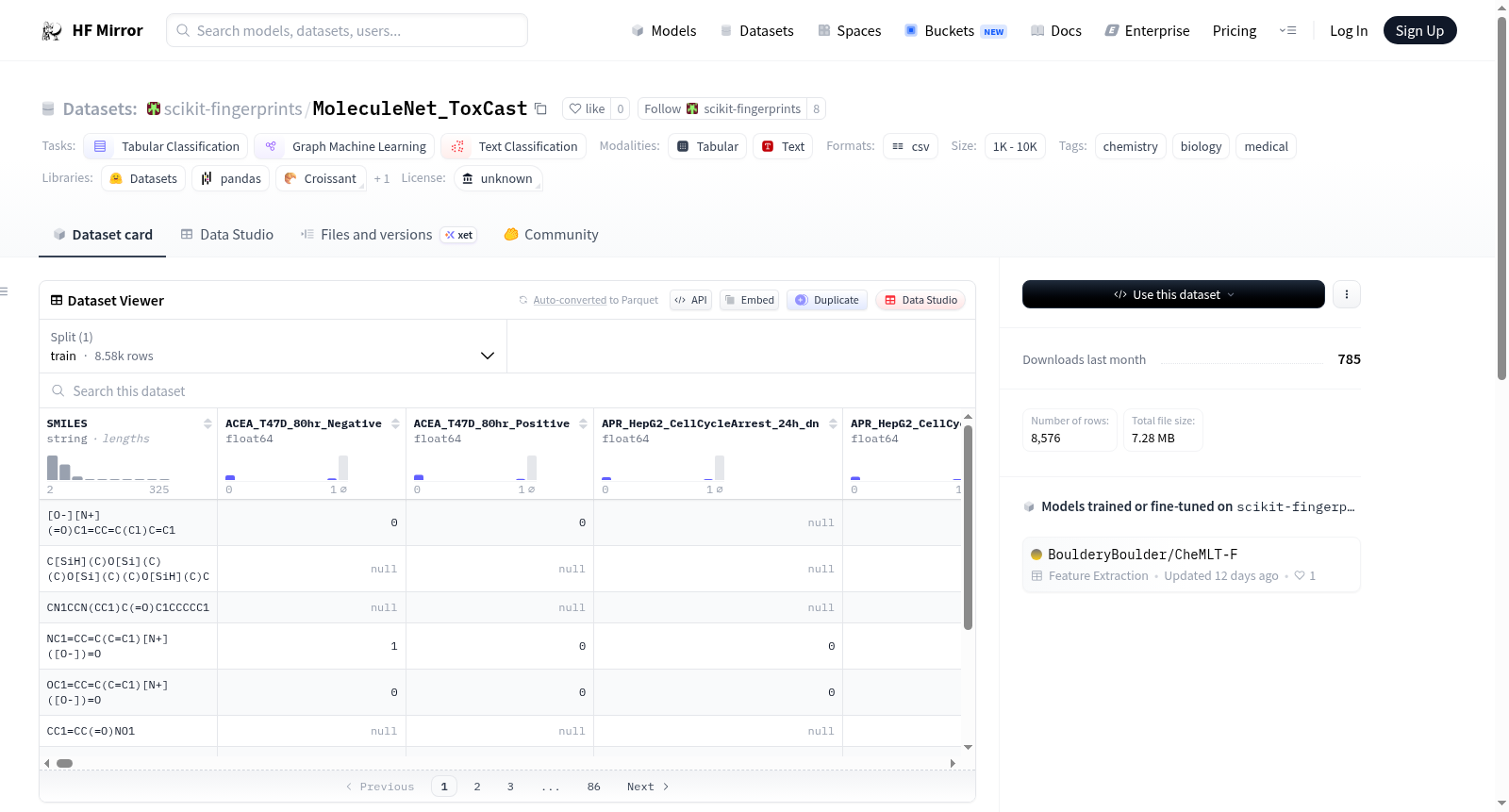
MoleculeNet ToxCast数据集是MoleculeNet基准测试的一部分,主要用于通过scikit-fingerprints库进行使用。该数据集的任务是基于体外高通量筛选预测大型化合物库中的617个毒性目标,所有任务都是二分类的。数据集中存在缺失值,算法应仅在现有标签上进行评估,训练数据可能需要用零值进行填补。数据集包含8576个样本,推荐使用scaffold分割方法,评估指标为AUROC。
The MoleculeNet ToxCast dataset is part of the MoleculeNet benchmark, designed to predict 617 toxicity targets from a large library of compounds through in vitro high-throughput screening. The dataset contains 8576 samples, with all tasks being binary classification. The recommended metric for evaluation is AUROC, and it is suggested to use scaffold for data splitting. The dataset includes missing values in targets, and it is recommended to impute them in training data.
提供机构:
scikit-fingerprints
搜集汇总
数据集介绍
构建方式
在计算毒理学与分子机器学习的交叉领域中,MoleculeNet_ToxCast数据集作为一项重要的基准资源应运而生。该数据集源自美国环保署的ToxCast项目,旨在通过体外高通量筛选技术评估化合物对大量毒性靶标的影响。其构建方式基于对8576种化合物进行系统性的生物学测试,涵盖617个二元分类任务,每个任务对应一个特定的毒性终点。数据集的划分推荐采用基于分子骨架(scaffold)的拆分策略,以确保模型在化学空间上的泛化能力。数据中存在大量缺失值,这反映了真实世界中高通量实验的不完整性,为算法设计提出了挑战。
特点
MoleculeNet_ToxCast数据集的核心特点在于其大规模多任务学习框架与生物学领域的深度耦合。617个毒性预测任务构成了一个高维稀疏的标签空间,使得模型必须同时处理多个相关但异质的分类问题。数据集规模适中(8576个样本),但任务数量远超样本量,形成了典型的小样本多任务场景。推荐的评估指标为AUROC,这体现了对类别不平衡问题的关注。此外,数据集的缺失值结构并非随机,而是与实验设计密切相关,要求算法具备鲁棒的缺失值处理能力。
使用方法
使用该数据集时,研究者需通过scikit-fingerprints库进行分子指纹的提取与建模。数据以CSV格式提供,包含化合物标识符与617个毒性标签列。由于任务为多标签分类,训练前需对缺失标签进行填充(如以零填充),但评估时仅考虑真实存在的标签。推荐采用骨架划分法生成训练集与测试集,以避免化学结构相似性导致的过拟合。模型性能的评估应基于每个任务的AUROC,并最终计算宏观平均值以反映整体表现。
背景与挑战
背景概述
在计算化学与药物发现的交叉领域,分子机器学习基准的建立对于推动预测毒理学的发展至关重要。MoleculeNet ToxCast数据集由Ann M. Richard等人在2016年首次提出,后经Wu Zhenqin等人整合至2018年发布的MoleculeNet基准中,成为评估分子性质预测模型的重要资源。该数据集聚焦于体外高通量筛选化合物库中的617个毒性靶点预测,旨在通过多任务二分类框架揭示化学结构与生物活性之间的复杂关联。其影响力不仅体现在为毒理学研究提供了标准化评估平台,更在于促进了图神经网络与分子指纹等先进方法在化学信息学中的实际应用,加速了从传统实验到计算预测的范式转变。
当前挑战
ToxCast数据集面临的核心挑战在于其高维稀疏性与标签缺失问题。首先,617个毒性靶点构成的多任务学习场景中,大量样本仅标注了部分任务,导致模型需在缺失标签比例较高的条件下进行有效训练,这要求算法具备鲁棒的不完整数据处理能力。其次,数据集规模仅含8576个分子,远低于靶点数量的维度,极易引发过拟合与泛化能力不足。构建过程中,研究者需在保持化学多样性前提下,通过支架分割策略确保训练与测试集的结构差异性,同时避免因缺失值填充方式(如零填充)引入偏差。此外,不同毒性靶点间的生物学关联复杂,如何建模任务间的依赖关系以提升预测准确性,仍是当前方法学突破的关键瓶颈。
常用场景
经典使用场景
MoleculeNet_ToxCast数据集作为分子机器学习领域的经典基准之一,广泛用于多任务毒性预测模型的构建与评估。其核心任务是从8576个化合物出发,预测617个体外高通量筛选毒性靶标的二分类结果。研究者常利用该数据集验证图神经网络、分子指纹特征与多任务学习框架在复杂化学空间中的泛化能力,通过支架划分(scaffold split)策略评估模型对新型分子结构的预测鲁棒性。AUROC作为推荐指标,使得该数据集成为衡量分子表征学习算法在毒理学预测任务上性能的标尺。
衍生相关工作
围绕MoleculeNet_ToxCast数据集,学术界衍生了一系列经典工作。MoleculeNet基准本身即以此数据集为核心组件,系统对比了多种分子表示方法与机器学习模型在毒性预测上的表现。后续研究如Weave、MPNN等图神经网络架构,以及基于Transformer的分子语言模型,均将该数据集作为关键验证基准。此外,针对其缺失标签问题,研究者提出了半监督学习与标签补全策略,推动了不完整标注场景下多任务学习方法的创新。这些工作共同构建了从分子表征到毒性预测的方法论体系。
数据集最近研究
最新研究方向
在计算毒理学与分子机器学习的交叉前沿,MoleculeNet ToxCast数据集正成为推动高通量体外毒性预测模型发展的关键基准。随着化学物质环境暴露风险评估需求的激增,该数据集涵盖的617个二分类毒性靶标任务,为多任务学习与图神经网络在化合物-靶点相互作用建模中提供了丰富标注。近期研究聚焦于利用自监督预训练策略与分子指纹增强技术,以应对标签稀疏性与数据异质性挑战,进而提升对复杂毒性机制的泛化能力。该数据集的广泛应用不仅加速了21世纪毒理学从传统动物实验向体外高通量筛选的范式转型,更在药物安全评估与化学品监管决策中彰显了深远意义。
以上内容由遇见数据集搜集并总结生成


