semantic-history-search
收藏Hugging Face2025-10-31 更新2025-11-01 收录
下载链接:
https://huggingface.co/datasets/frankjc2022/semantic-history-search
下载链接
链接失效反馈官方服务:
资源简介:
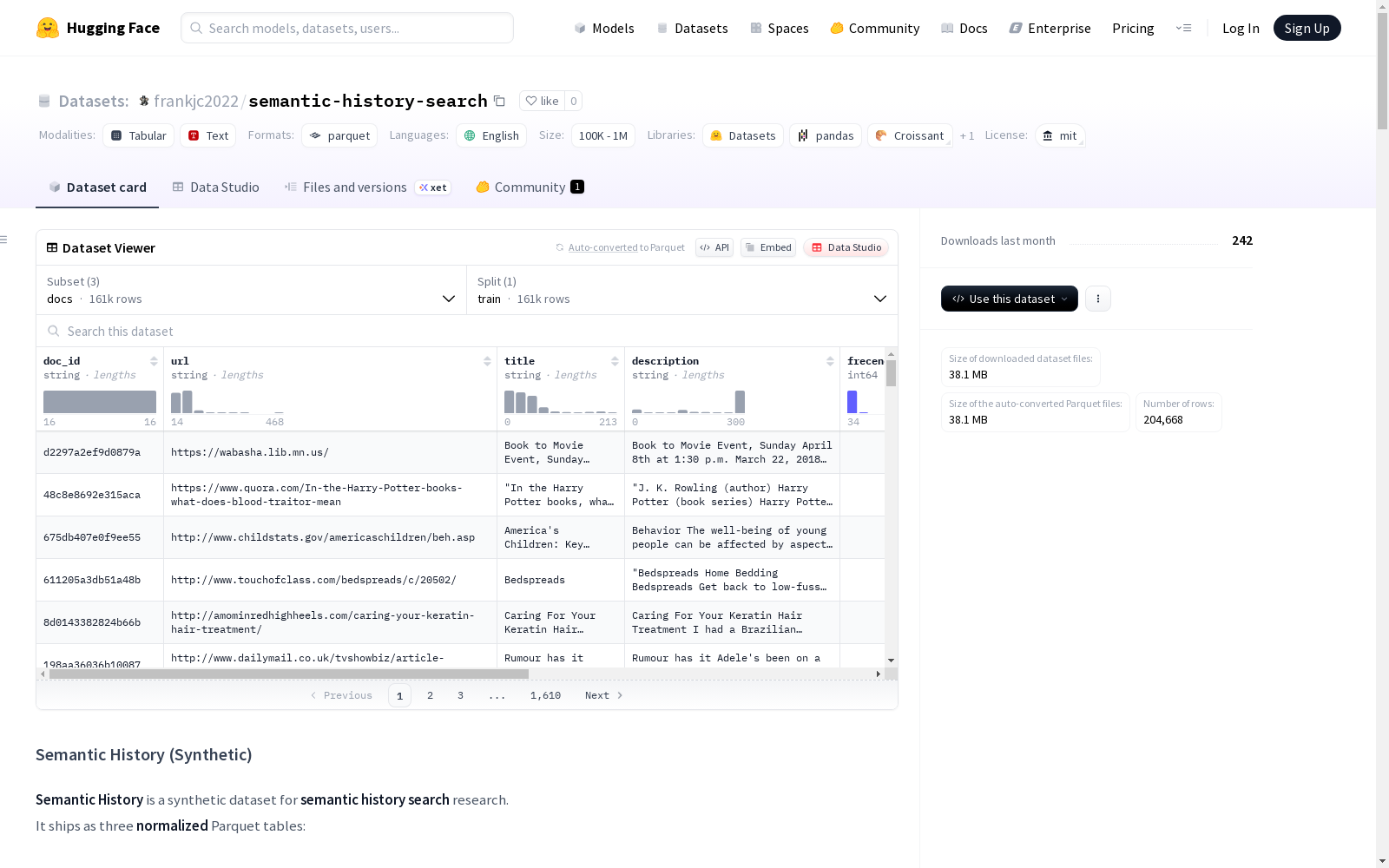
Semantic History是一个用于语义历史搜索研究的合成数据集。它包含三种规范化的Parquet表格:docs、queries和qrels。docs表格包含搜索历史记录,queries表格包含每个查询的信息,qrels表格包含查询和文档的相关性对。数据集设计用于用户导向的信息检索、时态感知检索以及嵌入和排名评估。
Semantic History is a synthetic dataset intended for research on semantic historical search. It includes three standardized Parquet tables: docs, queries, and qrels. The docs table stores search history records, the queries table contains information for each individual query, and the qrels table holds relevance pairs between queries and documents. This dataset is designed for user-oriented information retrieval, temporal-aware retrieval, as well as embedding and ranking evaluation.
创建时间:
2025-10-22
原始信息汇总
Semantic History (Synthetic) 数据集概述
数据集基本信息
- 数据集名称: Semantic History (Synthetic)
- 许可证: MIT
- 语言: 英语
- 数据格式: Parquet
- 数据性质: 合成数据(无真实浏览记录)
数据集组成
数据集包含三个标准化的Parquet表:
| 数据表 | 描述 |
|---|---|
docs |
搜索历史记录,包含URL、标题、描述、访问频率、最后访问日期和标签 |
queries |
每个查询一行,按配置文件和时态/多标签标记 |
qrels |
关联对,连接queries和docs,包含排名和相关性 |
数据配置
- 配置名称: docs
- 数据文件: data/v1/docs.parquet
- 配置名称: queries
- 数据文件: data/v1/queries.parquet
- 配置名称: qrels
- 数据文件: data/v1/qrels.parquet
时态变体特性
- 包含专门设计的时态切片,用于测试时间感知检索
- 时态查询标记为
variant="temporal" - 每个查询携带参考时间
ref_datetime_iso - 提供原始时态配置文件用于复现
数据列结构
docs表列
doc_id, url, title, description, frecency, last_visit_date, profile, profile_id, variant
queries表列
query_id, search_query, profile, profile_id, is_temporal, is_multi, variant, ref_datetime_iso
qrels表列
query_id, doc_id, profile_id, relevance, rank, variant
数据生成流程
- 数据源: MS MARCO文档(前50万行英语文档)
- 标准化: 构建统一表结构,包含URL、标题、描述等字段
- 采样: 选取约5万个英语示例
- 配置文件: 创建25个合成配置文件,每个包含1k-5k个项目
- 查询生成: 使用LLM生成配置文件特定查询并判断相关性
评估指标
- Precision@k, Recall@k, nDCG@k
- Reciprocal Rank (RR), Average Precision (AP)
- On-Topic Rate@k
相关资源
- 评估脚本和指标实现:https://github.com/mozilla/smart_search
- 数据生成代码:https://github.com/mozilla/smart_search/tree/temporal_awareness/preprocessing/generate_profiles
- 时态文档:https://huggingface.co/datasets/frankjc2022/semantic-history-search/blob/main/raw/profiles/temporal/README.md
搜集汇总
数据集介绍
构建方式
在语义历史搜索研究领域,该数据集通过系统化流程构建而成。其源数据取自MS MARCO文档集,经过规范化处理后形成包含URL、标题、描述等字段的统一表格。通过主题聚类生成25个虚拟用户画像,每个画像分配1,000至5,000条浏览记录,并注入模拟的访问频率与时间戳。查询语句与相关性标注由大语言模型生成,确保语义匹配的准确性。
特点
该数据集最显著的特征在于其完全合成的数据性质,有效规避了真实用户隐私风险。数据结构采用标准化三表范式,分别存储文档元数据、查询语句和相关性标注。特别设计了时间感知查询模块,通过参考时间戳解析相对时间表述。数据字段严格遵循Firefox浏览器历史记录规范,标题与描述字段长度均受系统级限制。
使用方法
研究者可通过HuggingFace数据集库直接加载标准化数据表,分别获取文档、查询和关联数据。支持按用户画像标识进行数据切片,可单独提取时间感知或多元标签查询子集。数据接口兼容pandas数据处理流程,支持通过查询标识符实现多表关联重构。评估体系包含精度召回率等传统指标,配套开源代码库提供完整实验框架。
背景与挑战
背景概述
语义历史搜索数据集由Mozilla研究团队于2024年构建,聚焦于个性化信息检索领域的前沿探索。该数据集通过模拟Firefox浏览器的历史记录存储结构,构建了包含文档元数据、用户查询及关联标注的标准化语料,旨在推动时序感知检索与用户画像建模的交叉研究。其创新性地引入时间维度解析机制,为处理包含'昨日''上周'等时序表达的自然语言查询提供了基准测试平台,对智能搜索引擎与个性化推荐系统的演进具有重要参考价值。
当前挑战
在解决个性化历史检索问题时,该数据集需应对时序表达消歧、多标签查询解析等核心难题。构建过程中面临合成数据真实性与多样性平衡的挑战:既要确保生成的浏览记录符合真实用户行为模式,又需维持主题分布与时间跨度的合理性。同时,基于LLM的查询-文档关联标注存在语义一致性维护困难,且需要精确模拟Firefox Places数据库的字段约束与长度限制,这对数据生成管线的设计提出了严格要求。
常用场景
经典使用场景
在信息检索研究领域,该数据集为语义历史搜索任务提供了标准化评估框架。其核心应用场景聚焦于模拟真实用户的浏览历史检索行为,通过结构化文档、查询及相关性标注构建完整的检索链路。特别在时间敏感型查询场景中,数据集通过标注参考时间戳与相对时间短语的映射关系,为时序感知检索模型提供了精准的验证环境。
衍生相关工作
该数据集催生了时序感知检索模型的系列创新研究,包括基于注意力机制的动态上下文编码器、多粒度时序嵌入方法等。在Mozilla智能搜索项目中衍生的评估框架,进一步推动了nDCG@k与On-Topic Rate等指标在语义历史检索领域的标准化应用。相关工作还拓展至跨语言检索场景,为多语种浏览历史的语义对齐提供了基准数据。
数据集最近研究
最新研究方向
在个性化信息检索领域,semantic-history-search数据集正推动时间感知检索系统的前沿探索。该数据集通过合成浏览历史记录,模拟真实用户档案中的时间敏感查询场景,例如处理包含“昨日”或“上周”等相对时间表述的搜索需求。当前研究聚焦于开发能够动态解析时间上下文的神经网络模型,结合Firefox Places数据库的标准化架构,优化语义嵌入与排序算法。这些进展不仅提升了跨会话历史检索的准确性,还为隐私保护的合成数据评估范式提供了重要基准,显著推动了用户中心化检索系统的发展。
以上内容由遇见数据集搜集并总结生成


